













复旦大学数据智能与社会计算实验室
复旦大学数据智能与社会计算实验室(Fudan DISC)推出大规模跨视觉语言模态预训练模型:MVPTR。
本文介绍了 Fudan DISC 实验室提出的一种基于多层次语义对齐的多阶段视觉 - 语言预训练模型 MVPTR,MVPTR 是一个多阶段的视觉 - 语言表征模型和预训练方法,通过显式地学习表示不同层级的,来自图片和文本信息的语义,并且在不同的阶段对齐不同层次的语义,在大规模图片 - 文本对语料库上预训练的 MVPTR 模型在下游视觉 - 语言任务上取得了明显的进展,包括图片 - 文本检索、视觉语言问答、视觉推断、短语指代表示。

- 论文链接:https://arxiv.org/abs/2201.12596;
- 代码链接:https://github.com/Junction4Nako/mvp_pytorch.
论文动机
视觉和语言是人类智能的两大重要体现,为了能协同处理来自视觉和文本的信息,近年来关于视觉 - 语言的多模态研究专注于从不同的任务出发去对齐视觉和语言的语义学习,比如图片文本检索、视觉语言问答(VQA)、短语表示指代等等。为了能打破任务间的壁垒,学习到泛化的多模态表示,研究者尝试去构建了视觉 - 语言的预训练模型(如 VL-BERT、UNITER、OSCAR 等),它们在大规模的图片 - 文本对上进行自监督的预训练后能在下游任务上通过微调取得不错的性能。
目前的视觉语言预训练模型大多沿袭了 BERT 中的序列建模方法,从图片中通过物体检测器 / CNN / 视觉 Transformer 抽取物体级别 / grid 级别 / patch 级别的特征拼接为视觉序列,将其与分词后的文本序列拼接成一个序列,通过多层 Transformer 学习模态内和跨模态的交互,这样的方式比较直接,但研究者认为其背后却少了对于跨模态信息间多层语义粒度对齐的探索。
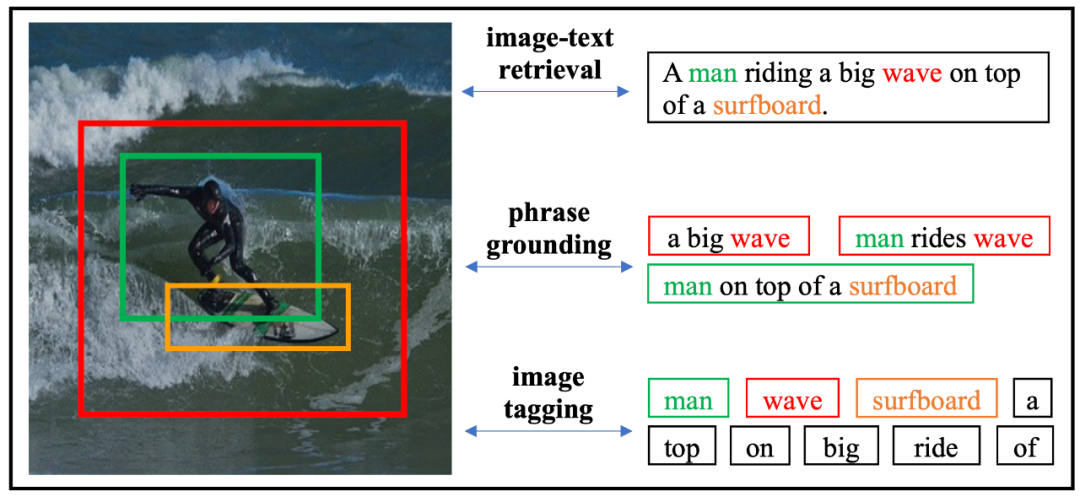
该研究在这里给出了一个图片 - 文本对的例子来说明图片 - 文本间的语义匹配情况。首先模态内的语义存在着层次嵌套结构,整个图片可以由很多的子图组成,每个子图里可能有多个物体存在;对于一个句子,可以被分词成很多的 token,多个 token 可以组成短语。同时各个层次间的语义对齐是互相帮助的,image tagging 将 token 对应到图片及图片中的物体,可以进一步帮助包含这个词的短语匹配到图片中的区域,完成 phrase grounding 的任务。基于物体和 token 的匹配、短语和图片区域的匹配信息,可以进一步推断出图片 - 句子间的相似度,完成 image-text retrieval 的任务。
所以为了能协同利用起多个层次的语义对齐,来自 Fudan DISC 实验室的研究者提出了 MVPTR:a Multi-stage Vision-language Pre-training framework。MVPTR 首先从文本和图片中分别构建了两个层次的语义:对于图片,该研究使用物体检测器抽取区域的特征,并且用预测出的物体类别作为物体级别的语义概念;对于文本,除了分词后的 token,该研究使用文本场景图解析器从中提取出场景图的结构化元组,作为短语级的语义概念。同时 MVPTR 的模型分成了两个阶段:单模态学习和跨模态学习阶段。在单模态阶段,模型学习模态内的交互,得到各个模态的多层语义的表示;在跨模态阶段,模型学习模态间的交互,并进行细粒度的推理。对于 MVPTR 的预训练,该研究设计在不同阶段设计了不同的自监督任务,来进行多层次的语义对齐。在单模态的视觉端,研究者引入了 MCR(masked concept recovering)来对齐区域特征和物体级别的概念;在跨模态阶段,首先通过 VSC(visual-semantic constrastive)来粗粒度地对齐全局的图片、文本单模态表征,然后使用 WPG(weakly-supervised phrase grouding)对齐短语级概念和区域特征,最后使用 ITM(image-text matching)和 MLM(masked language modeling)作为高层次的语义推断任务。
通过在约 9M 的图片 - 文本对的语料库上进行预训练,该研究的 base 设定下的 MVPTR 在下游任务上有着更好的表现。
方法介绍
MVPTR 的模型结构如下图所示:
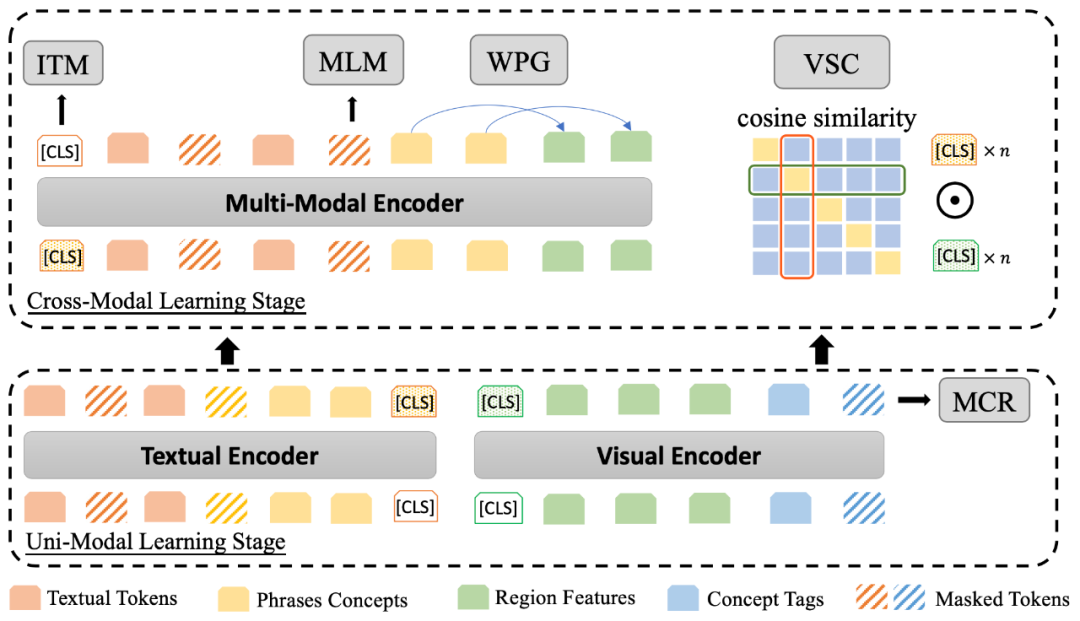
模型输入
为了能显式地学习多层次语义,如图所示,对于每个模态研究者构建了两个部分的输入,通过不同的颜色进行表示。受启发于之前主要是用在 Image captioning 任务中的方法,该研究通过学习概念 embedding 的方法引入其他层次的语义。
对于文本,类似 BERT 的处理方式,该研究首先将其经过分词器拆分成词,同时使用现成的文本场景图解析器 SPICE 将其解析为一个场景图,将图中的结构元组(物体,属性 - 物体,物体 - 关系 - 物体)作为短语级语义概念。对于每个短语概念,该研究会为其单独学习一个 embedding 表示,初始化自其中所有词的平均 embedding,同时因为概念需要有泛化性,该研究只考虑出现在预训练语料库中超过 50 次的短语。
对于图片,该研究使用固定的物体检测器从图片中检测出重要的物体的标记框和对应的视觉特征,进一步通过一个线性层将视觉特征和标记框坐标映射到与其他 embedding 同样的维度。同时对每个框使用对应的物体标签作为物体级别的概念,使用其标签词的 embedding 作为这个概念的表示。
单模态学习
在单模态学习阶段,MVPTR 只通过一个视觉编码器和文本编码器学习模态内的交互和表示,视觉编码器以拼接后物体特征序列和物体标签序列作为输入,学习物体间的关系,同时对齐物体特征和对应的物体级概念;文本编码器以拼接后的词序列和短语序列作为输入,提供短语中的结构信息,并进一步学习语境下的短语级概念。
MCR 遮盖概念恢复
在视觉编码器中,输入的视觉序列里包括了物体级的概念,以预测标签的方式。之前的代表性工作 Oscar 认为这样的概念可以作为锚点帮助对齐物体表示和词。为了能进一步地强化其锚点的作用,该研究提出了一个预训练任务 MCR。
类似于 BERT 的 MLM 任务,研究者随机地遮盖输入标签序列中的一部分,将其设为特殊字符 [MASK] 或随机替换,基于视觉编码器的输出,通过一个线性层预测遮盖部分原本的标签。MCR 任务可以看作是弱监督下的视觉特征和物体概念的对齐(预测特定的标签需要学习到对应物体与其的联系),MCR 类似 image tagging,能进一步对齐区域的表示,帮助之后跨模态的交互学习。
跨模态学习
在学习了单模态内的交互和表征后,在第二阶段学习跨模态的语义交互和对齐。首先从粗粒度,使用 VSC 任务对齐单模态编码器得到的全局表示,对齐两个编码器的语义空间;之后将对齐后的 token、短语、物体特征序列拼接输入到多模态编码器中进行学习,为了防止在进行后续预训练任务中产生从标签到词的 shortcut,影响真正跨模态关系的学习,标签序列并没有被考虑进去。在本阶段,进一步通过 WPG 来对齐物体特征和短语表示,并基于之前的表征,完成高层的推理任务,包括 ITM 和 MLM。
VSC 视觉语义对比学习
在输入跨模态编码器之前,MVPTR 通过 VSC 对齐两个模态编码器的语义空间,其具体的做法类似于 CLIP 和 ALBEF 中的训练方式,在全局层次上粗粒度地对齐图片和文本。
该研究将视觉、文本编码器得到的“[CLS]”token 的表示作为图片和文本的全局表征,以两个向量间的余弦相似度作为语义相似度。使用 InfoNCE 作为训练损失,同一 batch 里仅匹配的图片 - 文本为正样本对(对应模型图中 cosine similarity 矩阵的对角线部分),其余都为负样本对。
通过对全局粗粒度的对齐,该研究将处在对齐后空间的 token、短语、物体特征序列拼接输入跨模态编码器。
WPG 弱监督下的短语对齐
在跨模态学习阶段,该研究进一步显式地学习短语间的对齐关系,因为无法得到具体的图片区域和短语的匹配关系,研究者在 MVPTR 中使用类似现有的弱监督的 phrase grounding 方法进行学习。
对于每一个共同编码的图片 - 文本对,该研究考虑跨模态编码器得到的 n 个短语的表征和 m 个物体特征的表征,通过余弦相似度计算每个短语 - 区域间的语义相似度,对这样 n*m 的相似度矩阵。基于多样例学习的方法对每个短语选择与其最相似的一个区域作为该短语在整个图片中匹配的得分,对所有短语进行平均后得到基于短语 - 区域匹配的图片 - 文本匹配得分。之后训练过程中可以根据图片 - 句子匹配的得分
类似之前在 ALBEF 工作中的发现,该研究在跨模态编码器的第三层训练 WPG。在模型完成各层次的匹配之后,最后模型完成高层次的语义推理任务,包括 ITM 和 MLM。
ITM 图文匹配
图文匹配是视觉 - 语言预训练模型中常用的预训练任务,本质上是一个序列关系推断的任务,需要判断该多模态序列的图片和文本是否匹配。
在 MVPTR 中,该研究直接通过使用跨模态编码器输出的 CLS token 特征,学习一个多层感知器来预测是否匹配的 2 分类得分。类似 ALBEF 的做法,该研究基于 VSC 任务输出的全局相似度从训练批次中采样得到较难的负样本进行 ITM 任务。
MLM 遮盖语言模型
遮盖语言模型同样是预训练模型中的常见任务,研究者认为其本质上是一个推理任务,因为对于描述性文本中的关键词语的遮盖和回复,比如数量词、形容词、名词、动作等实质上是从不同角度的推理任务。MLM 的设定与其他的预训练模型一致:随机遮盖或替换一部分的 token,通过模型输出的表征,学习一个多层感知器预测原本的 token。
实验
预训练设定
首先在模型结构上,该研究采取了与 BERT-base 一样的参数设定,两个单模态编码器均为 6 层的 Transformer 架构,参数初始化自 BERT-base 的前六层;跨模态编码器也为 6 层的 Transformer 架构,参数初始化自 BERT-base 的后六层。
预训练的数据集上,MVPTR 使用了和 VinVL 一样的数据集,包括 MSCOCO、FLickr30k、GQA、Conceptual Captions、SBU、OpenImages,一共包括约 5M 的图片和 9M 的图文对。对于图片特征的抽取,MVPTR 使用的 VinVL 提供的物体检测器。具体的模型和训练参数设置可以参考论文中的介绍。
该研究对预训练后的 MVPTR 在多个下游任务上进行了微调,包括在 MSCOCO 和 Flickr30k 上的图文检索任务、VQA v2 上的视觉问答任务、SNLI-VE 上的视觉推理任务、RefCOCO + 上的短语表示指代任务,具体的微调方法和参数设定等请参考文章以及代码。
下图给出了在其中三个任务上结果:
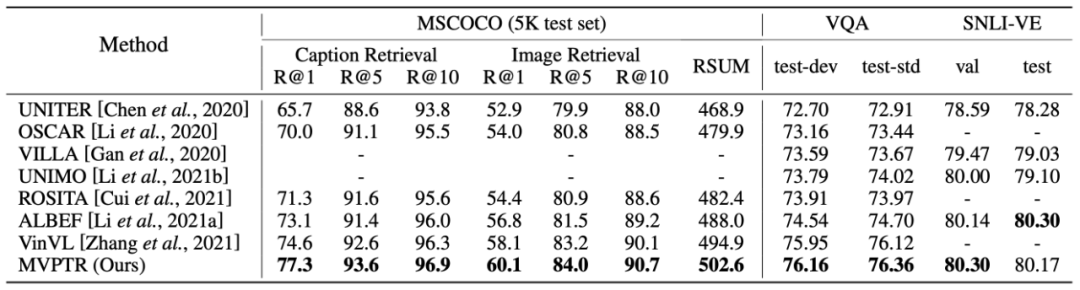
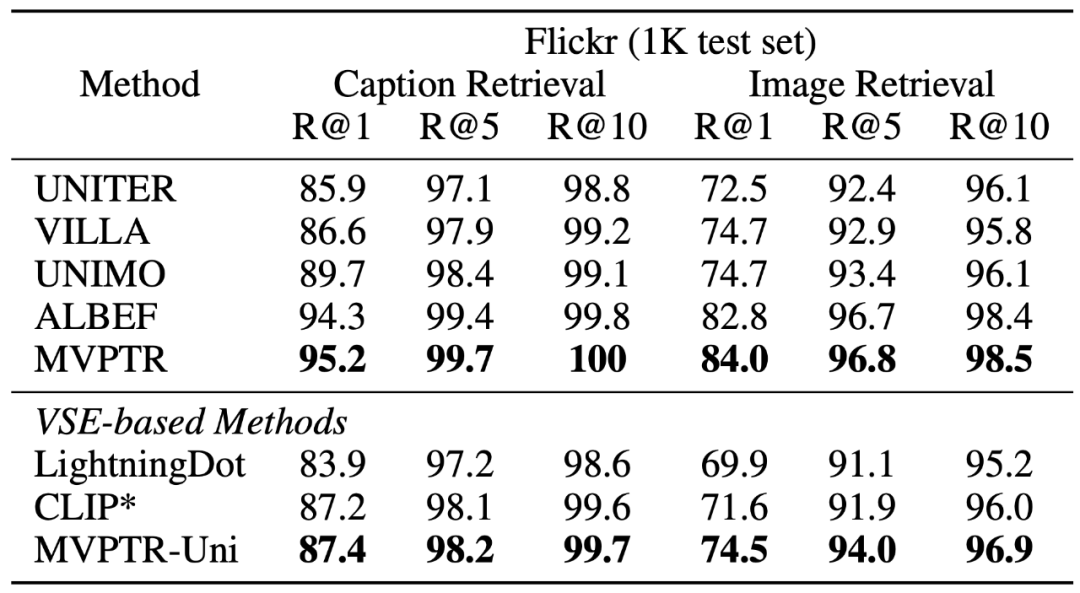
可以看到预训练后的 MVPTR 在 MSCOCO 和 FLickr 上的图文检索任务上都有着明显的提升,表明多个层次的语义对齐能够很好地帮助模型学习到全局上图片 - 文本的匹配关系。同时研究者在 Flickr 数据集上验证了 MVPTR 中单模态编码器的语义对齐能力(表 2 的下半部分),并比较了 MVPTR 的单模态部分和其他基于单模态编码器的方法(CLIP * 为该实验中微调后的 CLIP-ViT32 版本),从结果可以看出通过引入额外的概念,以及物体概念的对齐任务 MCR,单模态部分表现甚至要优于另外两个模型 CLIP,尽管 MVPTR-Uni 的参数规模仅为另外两者的一半(6 层与 12 层 Transformer 架构)。
在跨模态推理任务上,MVPTR 在 VQA 上有着一定的提升,同时对比 MVPTR 和 VinVL 在各个类别上的表现,MVPTR 在 VQA v2 的 “其他” 类问题上表现较好,VinVL 在数字类问题上表现较好。因为 VinVL 会直接根据物体检测标签去预测答案,研究者猜想这样的方法能很好地完成数数类问题,而 MVPTR 则更好地学习了跨模态的交互,来解决需要推理的其他类问题。在 SNLI-VE 上的视觉蕴含任务里,MVPTR 在测试集上效果要稍逊于 ALBEF,研究者认为 ALBEF 在测试集上的强大的泛化表现来自于其设计的动量蒸馏方法,此外,该研究也会进一步探究这样的方法对于 MVPTR 的改进。
在 RefCOCO + 上的短语指代表示任务上,因为该任务很依赖于物体检测器和所考虑的区域选择,所以研究者比较了 MVPTR 和 VinVL(VinVL 的结果为该研究使用与 MVPTR 类似方法进行微调实验得到):在 RefCOCO + 上的 testA 和 testB 上的两个测试集准确率上,MVPTR 的表现为 80.88/67.11,要高于 VinVL 的 80.5/65.96,说明 MVPTR 具有更强的对于短语级别对齐能力。
消融实验
为了验证各层次对齐的协同促进作用,该研究针对物体 / 短语级概念的引入和对齐设计了消融实验:
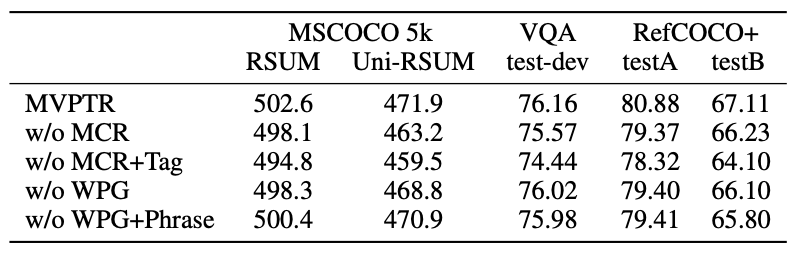
首先比较表内的前三行,可以看出缺少物体级概念的引入会给其他层次的语义对齐带来负面影响,包括细粒度、粗粒度的图片文本匹配,短语级别的对齐,并进一步影响对视觉问答的推理能力,且影响为所有消融实验里最大的,说明物体级的概念为其他层次对齐的基础。同时仅在引入输入的基础上,通过 MCR 的弱监督能进一步提高模型的性能,尤其是对于 Uni-RSUM 的影响说明了 MCR 能强化物体概念的锚点能力。总的来说物体级别的对齐帮助了短语级与图文级的对齐。
通过比较第一行和最后两行,可以看到短语级的概念能比较有效地帮助完成 visual grounding 和细粒度的图文匹配任务,同时比较最后两行可以看出如果不通过 WPG 显式地引导学习短语概念的表示,仅在输入端引入短语概念反而会引入一些噪声,拉低了图文匹配的表现。总的来说短语级的对齐帮助了图片文本的对齐。
概念的层次化表示
在 MVPTR 中该研究显式学习了短语级、物体级的概念,研究者通过可视化学习到的概念 embedding 表征来验证两者间存在嵌套层次关系。如下图所示,研究者使用 t-SNE 将学习到的 embedding 降维到 2 维,选择了几个常见的物体概念(三角形)和包含该物体概念的短语概念(圆点)进行呈现:
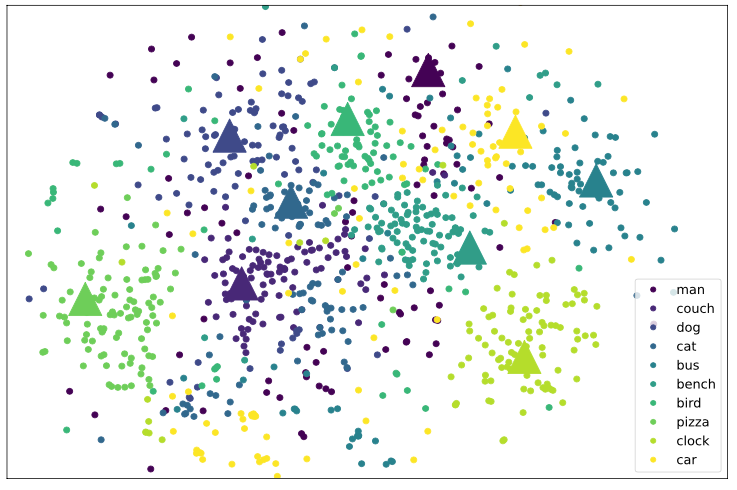
可以从图中看到明显的层次化特点:物体级别的概念作为聚类的中心,与其相关的短语级概念分布在其周围,出现在各种场景中的 man 和 car 分布很广泛,cat/dog/bird 都为动物分布很接近。
短语指代可视化
为了显式展现 MVPTR 学习到的短语级别概念的对齐,该研究使用 WPG 中的短语 - 区域间的相似度,对每个短语展示了与其语义相似度最高的区域,以下展现了一个 MSCOCO 测试集中的例子:






























