













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
众所周知,猫是一种液体。
这也给CVer带来了极大的烦恼:如何从2D视频中准确地对一只猫进行3D重建?
在很多情况下,3D重建模型得到的真是一滩液体。

而最近Meta团队提出的BANMo(Builder of Animatable 3D Neural Models),实现了对猫精确的3D重建。

这种方法既不需要专门的传感器,也不需要预定义的模板形状,甚至只用你平时给猫咪拍摄的休闲小视频,就可以做3D重建。
这篇关于BANMo的论文最近被CVPR 2022接收,作者已经将相关代码开源。
原理
从单目视频中重建自由移动的非刚性物体(例如猫),是一项高度约束不足的任务,会面临三大挑战:
如何在规范空间中表示目标模型的3D外观和变形;
如何找到规范空间与每帧之间的映射关系;
如何找到图像中视角、光线变化、目标变形之间的2D对应关系。
之前像NRSfM、NeRF等方法,要么是无法精确重建表面,要么对拍摄视角与物体的刚性有要求。
针对这些问题,BANMo使用神经混合皮肤,提供了一种限制目标物体变形空间的方法。
BANMo可以实现高保真3D几何重建。与动态NeRF方法相比,BANMo中使用神经混合皮肤可以更好地处理相机参数未知情况下的姿势变化和变形。
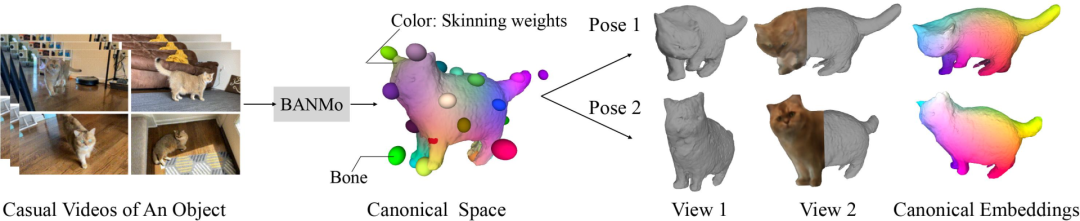
总的来说,BANMo的关键在于合并了三种技术:
(1)利用铰接骨架和混合皮肤的经典可变形形状模型;
(2)适合基于梯度优化的神经辐射场NeRF;
(3)在像素和铰接模型之间产生对应关系的规范嵌入。
大致方法如下图所示:
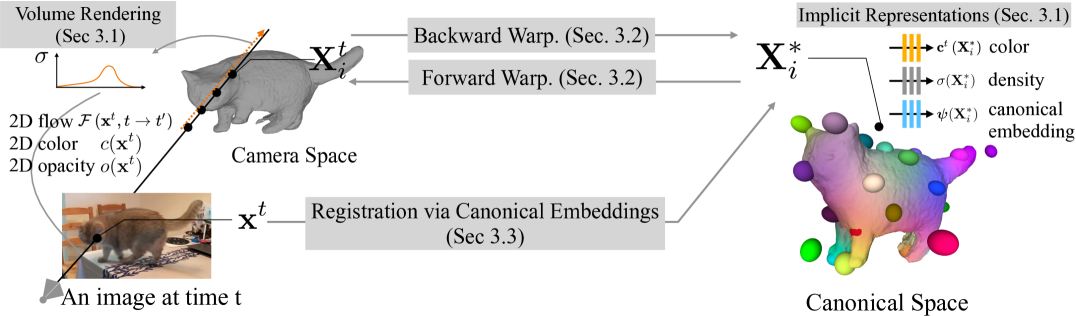
根据可微分的卷渲染框架(3.1)优化一组形状和变形参数,用像素颜色、轮廓、光流和高阶特征描述词来描述视频观测结果。
使用神经混合皮肤模型(3.2)在相机空间和规范空间之间转换3D点。
联合优化隐式规范嵌入(3.3),在视频中注册像素。
从整体架构上来看,BANMo分为三块:
1、形状和外观模型
这部分用多层感知器(MLP)网络预测颜色、密度等属性,并学习相机视角变换和处理大变形。
2、神经混合皮肤变形模型
这是基于近似关节身体运动的神经混合皮肤模型,将物体的扭曲作为刚体变换的组合,每个变换都是可微和可逆的。
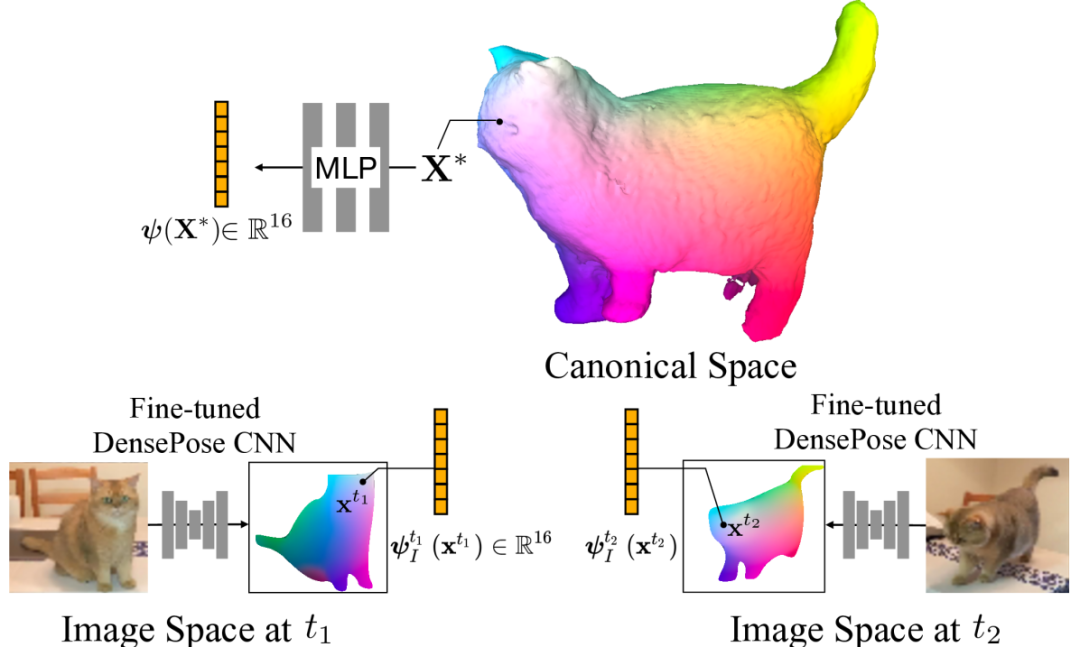
3、规范嵌入像素注册
嵌入对规范空间中3D点的语义信息进行编码,在这里作者优化了一个隐式函数,从与2D DensePose CSE嵌入相匹配的3D规范点生成规范嵌入。
在真实和合成数据集上,BANMo在重建穿衣服的人类和动物方面表现出强大的性能。
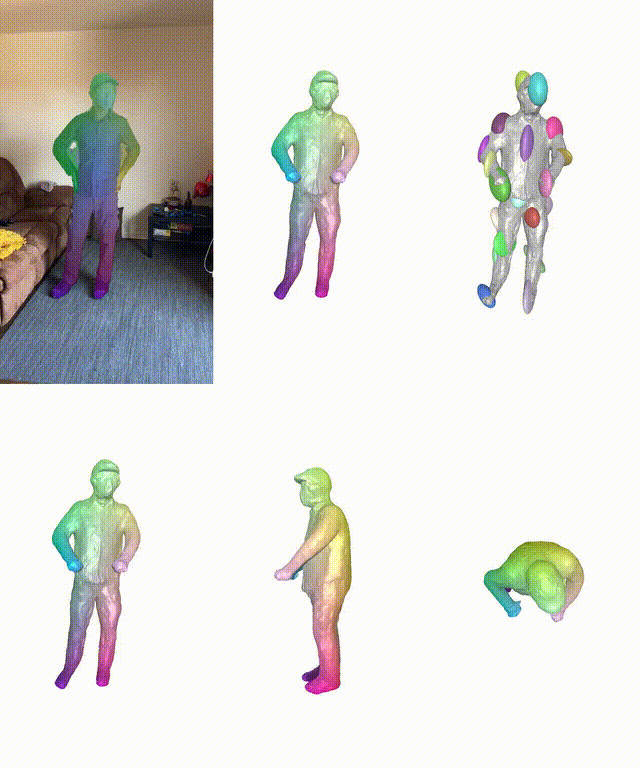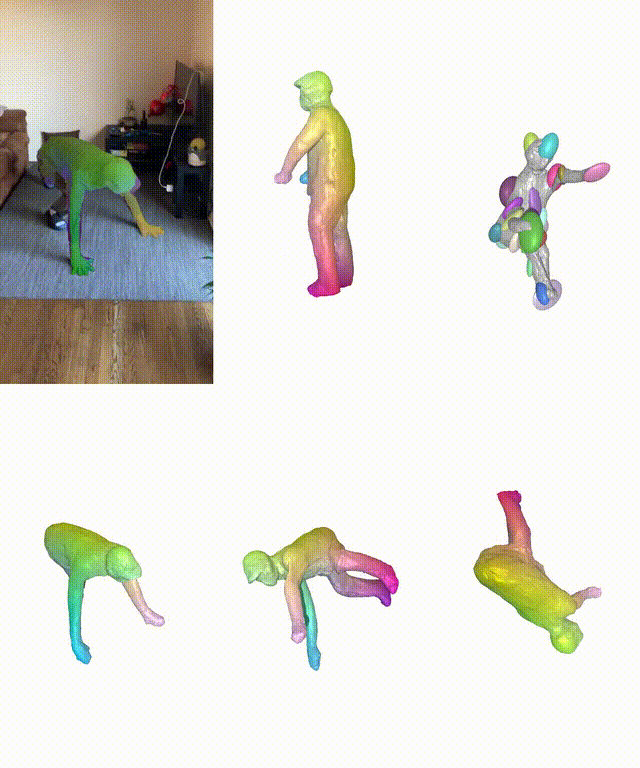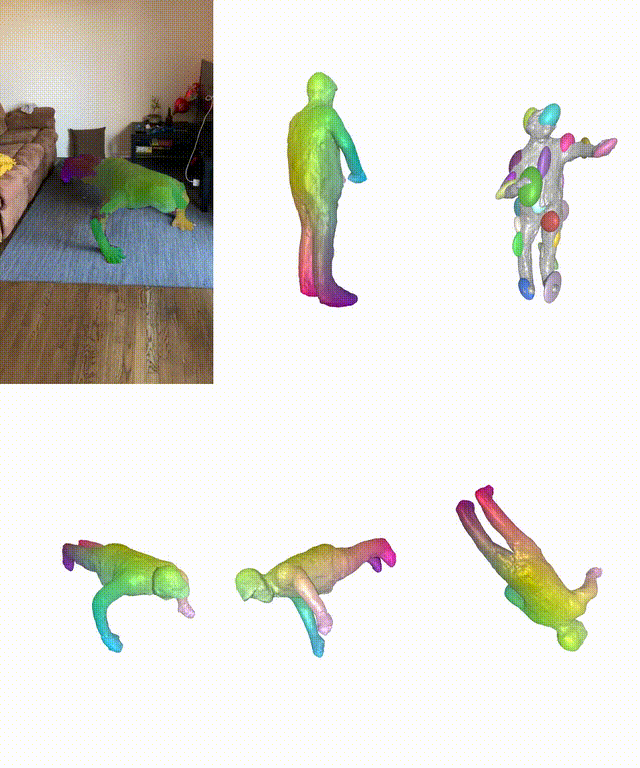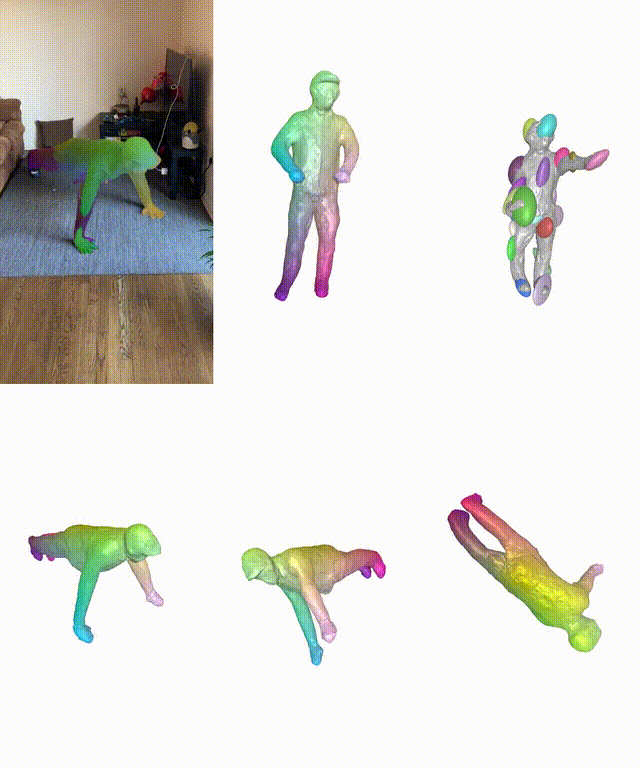
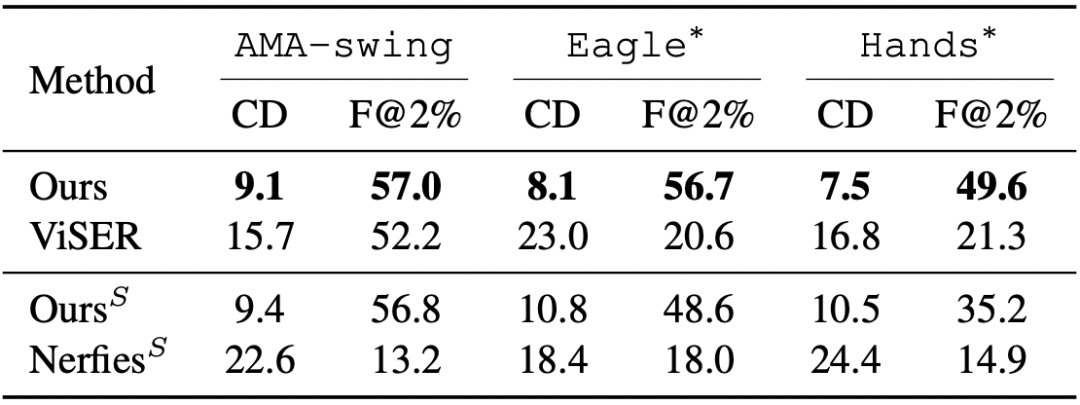
作者简介
这篇第一作者是杨庚山,毕业于西安交通大学,现在在CMU攻读博士学位,研究动态结构的3D重建算法。

BANMo这篇论文是他在Meta实习期间完成。
从2019年至今,他共有4篇一作论文被NeurIPS接收、4篇一作论文被CVPR接收。



























