今天我们来讨论OB,我也是一个OB的初学者,因此我对OB的内在原理和应用特性也知之甚少,我的大部分观点都是基于我对数据库的理解套用在OB上的。
另外,对于OB、TIDB等基于LSM-TREE存储引擎的数据库,经常会有人产生一些对比,因此在一些分析中我也会与TIDB进行对比。同样,对于TIDB,我也是只知道一些皮毛,因此这些对比很可能也有一些错误。
以前我也写文章分析过,TIDB和OCEANBASE虽然底层都是使用LSM-TREE存储引擎,不过其架构上是不同的。OB是一种典型的MPP架构的数据库,而TIDB是存储计算完全分离的架构。不过TIDB 5.0中也引入了MPP计算框架,具体是如何实现的,我还没有做研究,因此这里不展开讨论。
以往TIDB与OB进行争论的时候,TIDB往往会指出MPP的缺点来证明TIDB比OB的优越,而TIDB引入MPP计算框架反而证明了这种指责的不全面。以前我也说过,目前的大多数分布式数据库并不具备通用计算的能力,可能针对某种业务负载很好用,而对于一些其他的负载,就差强人意。
实际上任何一个分布式数据库厂家都在努力改善自己的产品,从而适应更广泛的应用场景。5.0以前的TIDB没有MPP的sharding key死结,不过也正因为如此,在TIDB层面上实现BUFFER CACHE十分困难,因为这需要引入缓冲区融合机制,在大规模分布式计算引擎上引入缓冲区融合将会是一个灾难。缺少TIDB层面BUFFER CAHCE,如果你不能接受稳定的稍慢,那么就需要提高硬件的配置,使用ssd盘等方式来提高SQL的响应速度,因此TIDB对硬件的要求很高。TIDB 5.0引入MPP计算模式我想也是从这方面考虑入手吧,这种计算模式的引入可以优化TIDB以往版本对某些场景的支持能力。
OB和TIDB的架构不同,OB是天生的SHARED NOTHING的MPP架构的,因此OB与其他的LSM-TREE存储引擎的数据库不同,设计了十分复杂的缓冲结构。为什么说是十分复杂的缓冲结构呢,因为OB是一种多租户的分布式数据库,在租户隔离上设计的十分完整,缓冲区可以细粒度到租户级别,每个租户都有独立的内存,CPU等的资源隔离。

另外一方面,Oceanbase是基于谷歌的五分钟原则设计的数据库系统(谷歌认为如果某个数据5分钟内会被访问至少一次,那么这个数据最好是放在内存中)。OB采用LSM-TREE,因此需要大量的内存来存储MEMT 。因此操作系统的物理内存可以尽可能多的交给OB SERVER,由OceanBase自己管理。

从上面的一张图里可以看到OB的内存使用策略。通过memory_limit_percentage参数可以设置最多有多少OS的内存可以给OB使用。这个参数的建议设置值是如果服务器内存为384GB,则设置为80%,如果服务器内存为512GB或者更高,则设置为90%。从这个策略也可以看出,OB还是比较吃内存的,为了有比较好的性能,建议给OB的服务器配置多一点内存。
实际上,OB的缓冲区除了其他LSM-TREE数据库所通用的实现外,还和B-TREE/HEAP存储引擎的数据库一样设计了BLOCK CACHE。
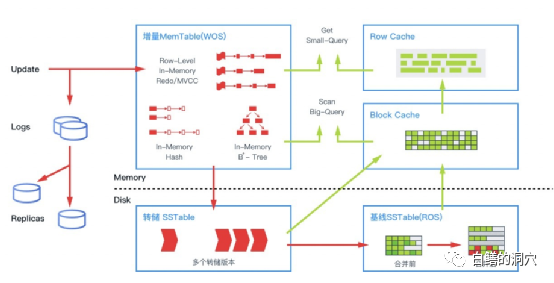
可以看出,OB设计了两层CACHE,一层是从SST读取到内存中的BLOCK CACHE,这层CACHE可以用于一般的SQL扫描操作,而在BLOCK CACHE之上,还设计了一层row cache,存储某些热行,这些热行用于一些简单的,执行频率较高的,访问少量行的SQL。
这种双层CACHE的设计(MEMSTORE的写缓冲不算在内)实际上是十分复杂的。Oracle数据库也有BLOCK CACHE和ROW CACHE两种缓冲设计,不过ROW CACHE只用来做字典缓冲使用,实际上是一种应用特定的缓冲,是应用级的。Oracle数据库对数据字典的访问是有特殊的业务逻辑的,为了提高效率而设计的ROW CACHE是按照固定的业务逻辑来设计的。而通用型的业务负载无法使用小巧高效的ROW CAHCE,必须使用统一的BLOCK CACHE。
而OB的row cache并不是用于内部计算使用,是面向通用业务场景的,如果某一行在block cache中的使用频率较高,那么就会被放入row cache中。为了避免每个访问都去查询row cache,从而导致row cache的命中率过低,影响CACHE的访问效率,在row cache上增加了一个布鲁姆过滤器。
我第一次看到OB的row cache结构的时候,就感到这种设计很互联网。这种架构,对于一些互联网应用的开发人员来说可能很熟悉,很容易让人想起应用-布鲁姆过滤器-REDIS-数据库的应用架构。对于这层CACHE,我还是十分疑惑的,因为CACHE的设计原则是简单高效,这层和业务结合的十分紧密的row cache是不是让应用开发人员自己去建立更好一些呢?当然对于应用类型十分吻合这种架构,又没有能力自己构建内存缓冲层的用户来说,这层row cache确实可以简化应用。我还没有深入去研究OB的row cache,不知道这层CACHE是否是可以在租户级关闭的,如果能够很方便的开关,这是一个不错的设计,否则我觉得如果遇到一些和这种场景不适合的应用,这种结构很可能会影响整体的性能。
LSM-TREE存储引擎的BLOCK CACHE性能问题,在国外的一些论坛上也多有讨论,比较主流的观点是效率不如HEAP/B-TREE存储引擎的数据库。这可能也是OB要引入row cache的一个原因吧。OB官方文档上对此的解释是:OLTP 业务大部分操作为小查询,通过小查询优化,OceanBase 数据库避免了传统数据库解析整个数据块的开销,达到了接近内存数据库的性能。
这种描述,对于某些应用场景来说可能是准确的,特别是像支付宝这样的交易类系统,而对于ERP,MIS系统等来说,就不一定适合了。大部分传统企业的OLTP系统并不能整合成如此简单的访问场景。从今天我们讨论的问题上,我们也看得出,分布式数据库厂商都在采用一些自己的独特技术,让数据库更加适合通用型的场景,从而在拥有分布式数据库的高可靠性、强大的横向扩展能力之外,能够像通用集中式数据库一样,对各种通用计算场景都能提供很好的支持。