













最近我们团队的D-SMART在做蚂蚁的OCEANBASE的适配,因此又把OB的资料拿出来,重新做研究。要想让D-SMART纳管OCEANBASE,不像一些传统的监控软件那么简单,只要把一些关键指标接入进来,搞几个基线模板就可以做做简单的报警了。必须对OB的基本原理、配置信息、运维要点、常见故障、巡检要点等做大量的归纳总结,并找到一些实际的用户,进行大量的测试,才能完成初步的适配,随后不断积累运维经验,才能让这个工具的能力越来越强。这也是做数据库的智能运维工具的不易之处。要重新学习OB,所以近期我会和大家分享一些我学习OB的心得。
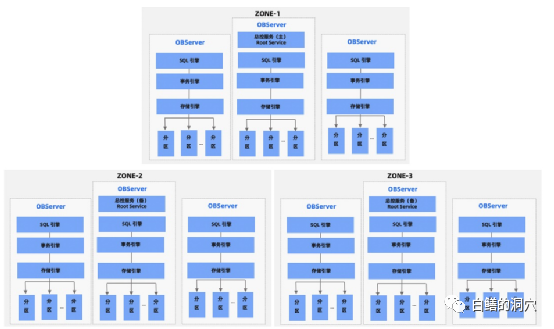
研究OB数据库,我们首先需要从这张OB架构图上开始分析。上面这张三个ZONE的OB架构图来自于OB的官方手册。从这张图上来看,OB除了总控服务(Root Service)是主备模式,采用一主N备的模式,其他的组件都可以看成是分布式去中心化的。其SQL引擎、事务引擎、存储引擎是采用分区分片的方式的。每个OBSERVER都包含一个SQL引擎,一个事务引擎、一个存储引擎和一组数据分区。
这种SHARDING架构的数据库系统十分适合高并发的小型交易,其中最为典型的就是支付宝业务。因为可以根据用户的ID,将大并发量的用户通过算法分散到各个对等的OBSERVER上去,通过扩展OBSERVER的数量就可以横向扩展OB的并发处理能力。
OB的ZONE具备远程部署能力,因此OB原生态具有支持同城双活的能力,可以将不同的ZONE部署在不同的数据中心里。OB的数据是采用多副本的,在每个ZONE里存储一份,并通过PAXOS分布式选举算法选举LEADER。OB的数据副本粒度可以到分区级。
SHARE NOTHING架构的分布式数据库一般被称为MPP数据库,集群上不共享任何数据,因此这种架构很容易横向扩展。作为MPP分布式数据库的设计理念,主要在高可用(采用多副本存储数据,单点故障不影响数据库)、可横向扩展(因为采用SHARE NOTHING,因此不存在缓冲区融合的问题,增加节点就可以增加处理能力)、使用简单(自动分库分表、自动数据路由,研发人员比较容易掌握)、运维方便等。
高可用这条毋庸置疑,比如OB这种架构,一份数据会在多个ZONE里有多个副本存储,甚至有的ZONE还可以位于远程或者异地,可用性方面是绝对没有问题的。不过OB这种靠一套数据库实现同城双活的方案,对于一般的系统来说可能够用了,不过对于一些可靠性要求十分高的系统来说,也是不够的。虽然ZONE可以跨数据中心,但是数据库本身也是一个单点,一旦整个数据库出问题了,那么业务也就中断了。使用可跨数据中心的分布式数据库之后,还需要不需要再搞高可用,还是只依赖于单一数据库的高可用,这一点就仁者见仁智者见智了。
可横向扩展也是没问题的,现在的网络能力下,SHARE NOTHING集群可以很方便的扩展到数十个甚至数百个。可以构建十分庞大的数据库集群。这是MPP数据库的优势所在。不过对于大多数传统架构的业务系统来说,大集群的MPP所提供的处理能力不一定是必须的,有可能一台2路服务器就已经远远超出你的业务处理能力的需求了,这时候选择MPP数据库的目的应该就不是横向扩展了。在我遇到的很多用户的应用场景中,选择具有横向扩展能力的架构实际上是一个伪命题。
运维方便这一点目前来看要从两个方面来看,对于日常运维来说,如果不出一些特别的问题,那么MPP分布式数据库总体来说运维还是比较简单的,日常运维主要看看SQL优化就可以了,因为高可用架构屏蔽了大量的硬件单点故障带来的系统问题,因此日常运维的压力是会得到缓解的。如果出现一些大一点的问题,那么运维人员也是无能为力的,MPP数据库的复杂性决定了,一旦出问题,很可能数据库原厂都不一定能很快搞定,因此故障处理的主力就是原厂了。从这一点上来讲,使用MPP数据库,运维人员的压力会比较小。
使用简单这一点,是MPP数据库最令客户喜欢的一点,不过这一点上往往争议也最大。实际上分布式数据库的最早雏形是互联网企业的分库分表,这方面在世纪之初我们在给运营商做优化的时候也大量的使用。把一个数据库按照业务分拆成多个,无法分拆的库做复制,进行读写分离处理,从而让已经达到纵向扩展极限的系统能够分拆负载,这个方法被称为分库。
对于开发人员来说,分库还是比较容易实现的,只要开发厂家的水平不是太差,分库后的聚合计算方面的研发能力稍微好一点,分库还是比较容易实现的,因为分库是按照业务去分的,大部分的计算都会集中在库里,只有少量的计算才需要跨库的聚合计算。不过我也遇到过很极端的情况,一个数据库被分为6个小库后,开发人员不愿意自己程序里实现聚合计算,只能创建OGG复制链路,把部分分出去的数据再复制回来。这套系统上线不到半年,这种OGG复制链路已经有好几十条了。对于MPP数据库来说,分库就更为简单了,SQL引擎可以自动实现跨库的表连接,开发人员也就不需要再去复制表数据了。
MPP架构应用的另外一种模式是分表,当分库已经不能满足要求的时候,就需要分表了。可能大家刚开始的时候觉得分表不就是比分库分的更细一点吗,既然分库没问题,那么分表也不应有有问题了。
实际上并不是这样的,分表有两种形式,一种是把一个库里的多张表分不到不同的OBSERVER中去,一种是把一张表分为多个片,存储到不同的OBSERVER中去。第一种分表对于应用开发来说还比较好办,MPP数据库的SQL引擎会做聚合计算,因此对于开发来说并没有什么不同。有差异的是性能,跨多个OBSERVER的聚合查询的性能和单机数据库比,在很多方面都是存在差异的,这和分布式数据库的优化器和执行器的水平有很大的关系。跨库数据的聚合计算肯定会比单机有更多的延时,这些延时主要是在网络上的。不过这些都不是最主要的因素,最主要的是算子下推的操作。分布式数据库的算子下推可以利用并行执行的优势来加速,不过算子下推的粒度和能力,在不同的数据库厂商实现方面存在技术差距,这一点往往需要经过严格的对比才能看得出来。
分片是一个更复杂的问题,我们要把一张表分成多个片段分布到多个OBSERVER中去,那么我们必须要按照某个SHARDING KEY来分表。如果分表后,我们对这张表的查询语句上都带有这个SHARDING KEY的过滤条件,那么优化器在分解执行算子的时候,可以很方便的进行分区裁剪,从而降低执行成本。如果我们的SQL中不带SHARDING KEY过滤条件,那么这条SQL就会分布到所有的这张表所在的OBSERVER上去执行,这样可能会放大SQL执行的资源消耗,也会影响SQL的执行效率。
分库分表另外一个对性能影响较大的因素是多表关联查询方面的性能问题。比如某个表的某个分片在OBS1上,而关联表的分区在OBS2上,那么这个分布式关联操作的性能就不如二者都存放在OBS1上了。OB数据库引入了一个表组(table group)的逻辑结构。设置为同一个table group的多张表具有相同或者像类似的分区策略,其关联操作也比较多,这样可以确保这类业务的性能不会有太大的下降。
实际上我们还经常遇到一个问题就是一张分区的大表经常需要和一些小表进行关联,有些数据库也支持将一些小表复制到多个数据库分片中,从而提高这些关联操作的性能。
在很多分布式数据库的设计之初,数据库研发人员是希望分布式数据库能够很方便的让人使用,而实际上分布式数据库和集中式数据库在架构上的不同决定了,用好分布式数据库肯定需要有更高水平的设计,利用分布式数据库的特性,做精心的设计,尽可能避免分布式数据库中的那些坑,才能把应用做的更好。如果我们的数据库厂商总是避开这些不谈,等用户在他们的数据库上开发出了不那么令人满意的系统来,那时候再去说用户不会用分布式数据库,那就不够地道了。



























