1.什么是Storm
Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
按照storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。Hadoop提供了map、reduce原语,使我们的批处理程序变得简单和高效。同样,Storm也为实时计算提供了一些简单高效的原语,而且Storm的Trident是基于Storm原语更高级的抽象框架,类似于基于Hadoop的Pig框架,让开发更加便利和高效。
2.Storm应用场景
推荐系统(实时推荐,根据下单或加入购物车推荐相关商品)、金融系统、预警系统、网站统计(实时销量、流量统计,如淘宝双11效果图)、交通路况实时系统等等。
3.Storm的一些特性
1.适用场景广泛: storm可以实时处理消息和更新DB,对一个数据量进行持续的查询并返回客户端(持续计算),对一个耗资源的查询作实时并行化的处理(分布式方法调用,即DRPC),storm的这些基础API可以满足大量的场景。
2. 可伸缩性高: Storm的可伸缩性可以让storm每秒可以处理的消息量达到很高。扩展一个实时计算任务,你所需要做的就是加机器并且提高这个计算任务的并行度 。Storm使用ZooKeeper来协调集群内的各种配置使得Storm的集群可以很容易的扩展。
3. 保证无数据丢失: 实时系统必须保证所有的数据被成功的处理。 那些会丢失数据的系统的适用场景非常窄, 而storm保证每一条消息都会被处理, 这一点和S4相比有巨大的反差。
4. 异常健壮: storm集群非常容易管理,轮流重启节点不影响应用。
5. 容错性好:在消息处理过程中出现异常, storm会进行重试
6. 语言无关性: Storm的topology和消息处理组件(Bolt)可以用任何语言来定义, 这一点使得任何人都可以使用storm.
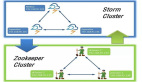
4.storm集群结构
Nimbus 和Supervisors 之间所有的协调工作是通过 一个Zookeeper 集群。
Nimbus进程和 Supervisors 进程是无法直接连接,并且是无状态的; 所有的状态维持在Zookeeper中或保存在本地磁盘上。
意味着你可以 kill -9 Nimbus 或Supervisors 进程,而不需要做备份。
这种设计导致storm集群具有令人难以置信的稳定性,并且无耦合。
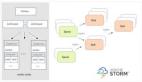
5.storm工作原理
Nimbus 负责在集群分发的代码,topo只能在nimbus机器上提交,将任务分配给其他机器,和故障监测。
Supervisor,监听分配给它的节点,根据Nimbus 的委派在必要时启动和关闭工作进程。 每个工作进程执行topology 的一个子集。一个运行中的topology 由很多运行在很多机器上的工作进程组成。
在Storm中有对于流stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象为tuple即元组
Storm认为每个stream都有一个源,也就是原始元组的源头,叫做Spout(管口)
处理stream内的tuple,抽象为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout再将spout中流出的tuple导向特定的bolt,bolt又对导入的流做处理后再导向其他bolt或者目的地。
可以认为spout就是水龙头,并且每个水龙头里流出的水是不同的,我们想拿到哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(bolt),水处理器处理后再使用管道导向另一个处理器或者存入容器中。
为了增大水处理效率,我们很自然就想到在同个水源处接上多个水龙头并使用多个水处理器,这样就可以提高效率。
这是一张有向无环图,Storm将这个图抽象为Topology(拓扑),Topo就是storm的Job抽象概念,一个拓扑就是一个流转换图
图中每个节点是一个spout或者bolt,每个spout或者bolt发送元组到下一级组件。
而Spout到单个Bolt有6种流分组策略。
6.Topology
Storm将流中元素抽象为tuple,一个tuple就是一个值列表value list,list中的每个value可以是任意可序列化的类型。拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
7.storm相关概念
Streams:消息流
消息流是一个没有边界的tuple序列,而这些tuples会被以一种分布式的方式并行创建和处理。 每个tuple可以包含多列,字段类型可以是: integer, long, short, byte, string, double, float, boolean和byte array。 你还可以自定义类型 — 只要你实现对应的序列化器。
Spouts:消息源
Spouts是topology消息生产者。Spout从一个外部源(消息队列)读取数据向topology发出tuple。 消息源Spouts可以是可靠的也可以是不可靠的。一个可靠的消息源可以重新发射一个处理失败的tuple, 一个不可靠的消息源Spouts不会。
Spout类的方法nextTuple不断发射tuple到topology,storm在检测到一个tuple被整个topology成功处理的时候调用ack, 否则调用fail。
storm只对可靠的spout调用ack和fail。
Bolts:消息处理者
消息处理逻辑被封装在bolts里面,Bolts可以做很多事情: 过滤, 聚合, 查询数据库等。
Bolts可以简单的做消息流的传递。复杂的消息流处理往往需要很多步骤, 从而也就需要经过很多Bolts。第一级Bolt的输出可以作为下一级Bolt的输入。而Spout不能有一级。
Bolts的主要方法是execute(死循环)连续处理传入的tuple,成功处理完每一个tuple调用OutputCollector的ack方法,以通知storm这个tuple被处理完成了。当处理失败时,可以调fail方法通知Spout端可以重新发送该tuple。
流程是: Bolts处理一个输入tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
Bolts使用OutputCollector来发射tuple到下一级Blot。