












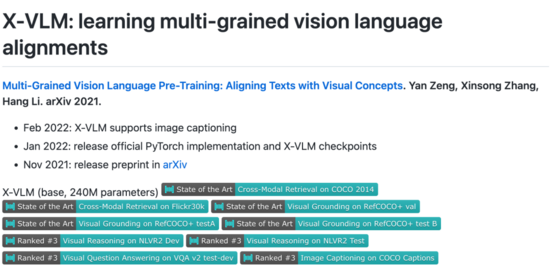
写在前面
视觉语言预训练提高了许多视觉语言任务的性能。但是,现有的多数预训练方法依赖目标检测器(object detectors)提取基于物体的视觉特征,以此学习细粒度的视觉和语言对齐,例如物体(object)级别。然而,这种方法存在识别视觉概念有限、图像编码上下文信息丢失和计算效率低下的问题。
在本文中,字节跳动人工智能实验室提出了 X-VLM,以统一的方法学习多粒度的视觉和语言对齐,不依赖目标检测方法且不局限于学习图片级别或物体级别的对齐。 该方法在广泛的视觉语言任务上获得了最先进的结果,例如:图像文本检索 (image-text retrieval)、视觉问答(VQA)、视觉推理(NLVR)、视觉定位 (visual grounding)、图片描述生成(image captioning)。
论文标题:
Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts
论文链接:
https://arxiv.org/abs/2111.08276
代码链接:
https://github.com/zengyan-97/X-VLM
研究背景

▲ 图1:现有两类的方法(a, b)和X-VLM(c)
现有的多模态预训练模型大致分为两类:1)依赖目标检测器提取基于物体的视觉特征,以此学习细粒度的视觉和语言对齐,如图 1 中(a)。这些方法要么直接利用预先训练的目标检测器,要么将目标检测过程合并到多模态预训练中;2)用 CNN 或者视觉 Transformer 编码整张图片,直接学习文本和图片特征之间的粗粒度对齐,如图 1(b)。
这两种方法都存在问题。首先,基于目标检测的方法会识别图片中所有可能的物体,其中不乏一些与配对文本无关的。此外,这种方法所提取的基于物体的视觉特征可能会丢失物体之间的信息(可以认为是一种上下文信息)。而且,我们也很难预先定义需要识别的物体种类。而第二种方法则较难学习到细粒度的视觉和语言对齐,例如:物体级别的对齐。这种细粒度的对齐关系被之前的工作证实对于视觉推理(visual reasoning)和视觉定位(visual grounding)任务很有帮助。
实际上,对于多模态预训练,有以下公开数据以供模型训练:1)图片和图片标题;2)区域标注,例如:图 1 中的文本“man crossing the street”关联到了图片中的某个具体区域。然而,之前的工作却粗略地将区域标注与整张图片对齐;3)物体标签,例如“backpack”,这些标签被之前的工作用来训练目标检测器。
与之前的做法不同,本文中作者提出 X-VLM,以统一的方式利用上述数据学习多粒度的视觉和语言对齐,而不依赖目标检测方法且不局限于学习图像级别或物体级别的对齐。作者提出学习多粒度视觉和语言对齐的关键在于,如图 1(c)所示:1)给出文本,定位图片中的视觉概念,以边界框的回归损失和交并比损失优化;2)同时拉齐文本和对应的视觉概念,通过常用的对比学习损失,匹配损失,MLM 损失优化。实验证明,X-VLM 能在下游任务中有效利用预训练时学到的多粒度视觉和语言对齐,在多种视觉语言任务上获得非常优秀的表现。
方法
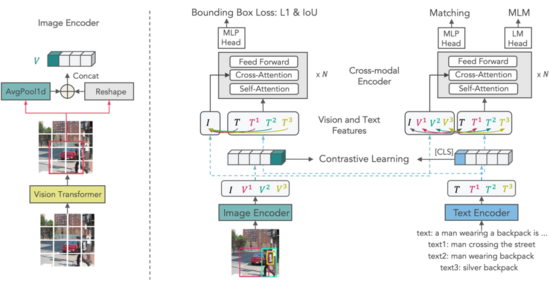
▲ 图2:X-VLM框架
X-VLM 由一个图像编码器,一个文本编码器,一个跨模态编码器组成。
图 2 左侧给出了视觉概念 V(可以是物体/区域/图片)的编码过程:该图像编码器采用视觉 Transformer,将输入图片分成 patches 编码。然后,给出任意一个边界框,简单地通过取框中所有 patch 表示的平均值获得区域的全局表示。
再将该全局表示和原本框中所有的 patch 表示按照原本顺序整理成序列,作为该边界框所对应的视觉概念的表示。 通过这样的方式获得图片本身( )和图片中视觉概念( , , , )的编码。与视觉概念对应的文本,则通过文本编码器一一编码获得,例如图片标题、区域描述、物体标签。
X-VLM 采用常见的模型结构,其不同之处在于预训练的方法。作者通过以下两类损失进行优化:
第一,给出文本,例如: (text)、 (text1)、 (text2)、 (text3),预测图片 中的对应视觉概念的边界框:
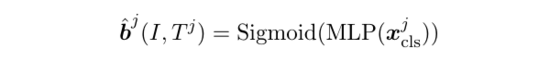
是跨模态编码器在 [CLS] 位置的输出向量。Sigmoid 函数是为了标准化。Ground-truth 对应了( ),依次是标准化后的的中心横坐标、中心纵坐标、宽、高。最后,该损失是边界框的 GIoU 损失和 L1 损失之和。作者认为在同一张图片中,给不同文字,要求模型预测出对应的视觉概念,能使模型更有效地学习到多粒度的视觉语言对齐。该损失也是首次被使用在多模态预训练中。
第二,同时优化模型去拉齐文本和对应的视觉概念,包括了物体/区域/图片与文本的对齐。 作者使用多模态预训练中常见的三个损失优化,依次是:
1)对比学习损失:
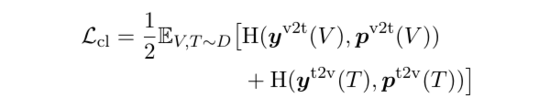
, 是 ground-truth 相似度,对角线为 1,其余为 0 。 , 是模型基于文字编码器输出和图像编码器输出所计算的相似度。
2)匹配损失:
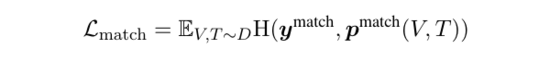
是基于跨模态编码器计算,预测所给( )对是否匹配(换句话说,0/1分类)。对于每对正例,作者采样一对负例。
3)Masked Language Modeling 损失:
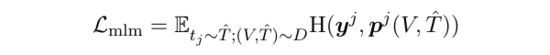
中的一些词已经被随机替换成了 [MASK], 是跨模态编码器在词 位置的输出向量所计算的词表概率分布。
实验
作者使用多模态预训练中常见的 4M 图片数据集进行实验,同时也在一个 16M 数据集下验证了模型效果,如下表所示:
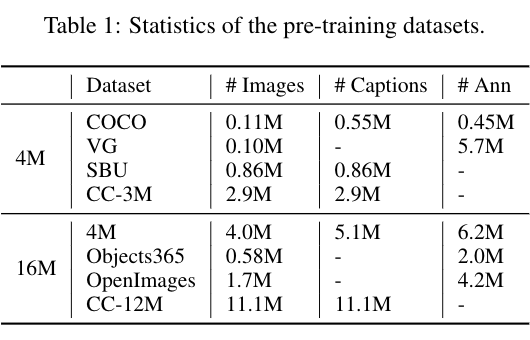
▲ 表1:两种预训练数据集
其中,标注(# Ann)是区域标注和物体标签的总称。可以看出,有些数据集没有图片标题(Captions),例如 Visual Genome,有些数据集没有图片标注,例如 CC-3M/12M。
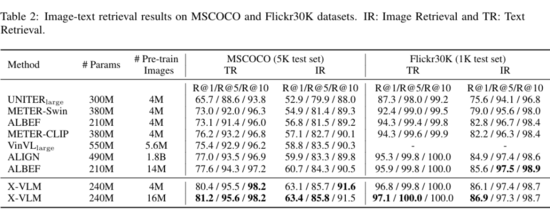
▲ 表2:在图像文本检索任务上的实验结果
表 2 展示了在图像文本检索任务(MSCOCO 和 Flickr30K)上的表现。可以看出在 4M 图片数据集下训练的 X-VLM 就已经超过了之前的方法。
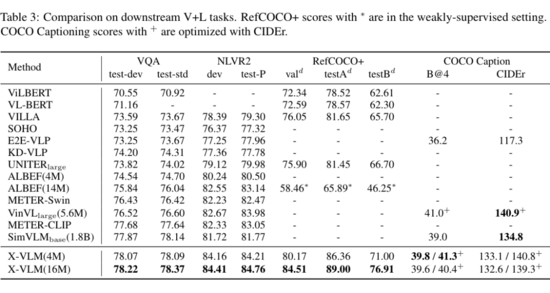
▲ 表3:在多种下游视觉语言任务上的实验结果
表 3 展示了在视觉推理(VQA2.0 和 NLVR2)、视觉定位(RefCOCO+)、图片描述生成(COCO Captio)上的模型表现。结合表 2 和表 3,可以看出,相比之前的方法,X-VLM 支持更多种类的下游任务,并且在这些常见的视觉语言任务上都取得了最先进的表现。
总结
在本文中,作者提出了 X-VLM,以统一的方法学习多粒度的视觉和语言对齐,不依赖目标检测方法且不局限于学习图片级别或物体级别的对齐。这种预训练方法适用于广泛的下游任务,除了视觉推理,还同时在图像文本检索、视觉定位、图片描述生成任务上取得了最先进的表现。全部代码均已开源,可扫下方二维码体验。






























