Part One 可用性概念一览
永不停机总归是不现实的。那么,在可操作性的范围内,怎样把影响降到最小,而影响又该怎么衡量呢?
概念一:MTBF (mean time between failure)
MTBF是指两次相邻的系统失效(服务故障)之间的工作时间长度。也可以叫它无故障时间 或 失效间隔。这个值越大,说明系统的故障率越低,系统越可靠。因此,我们通常希望这个时间间隔越大越好。
概念二:MTTR (mean time to repair)
MTTR是指从出现故障到修复中间的时间长度。也叫做修复时间。这个值越低,说明故障越容易恢复,系统可维护性越好。因此,我们通常希望这个时间间隔越小越好。
因此,系统可用性可以量化为:
MTBF / (MTBF + MTTR)
示例:系统的可用性要求 99.999% ,那么,按一年365天来算:
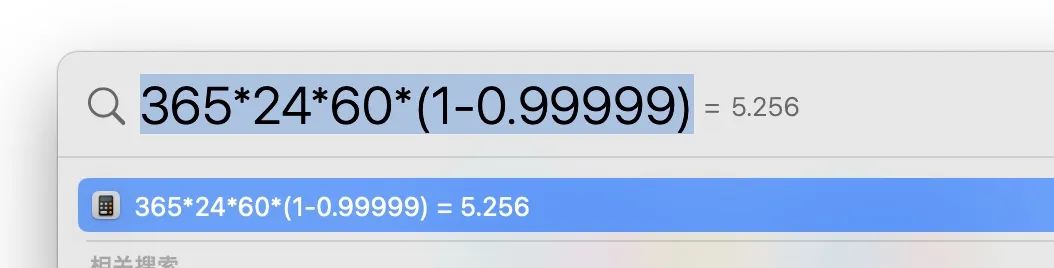
全年允许的宕机时间只有5分钟多一点。
Part Two 高可用的保障
全年宕机5分钟?从上一部分可以知道,我们的目的,是要尽可能的增大系统的无故障运行时间,同时,在发生故障时,尽可能迅速的完成恢复。
故障的发生多种多样,经过了这么多年的研发前辈的踩坑,我们可以将其分类汇总,并给出分析和对应的方案。
Level1: 配置修改出错
最不应该犯的错,但是感觉很多人都没少犯。
原因也很简单,要不就是格式错了,要不就是配置的数据不对,而且错误的配置还被直接发到了线上,直接导致业务异常,甚至宕机。
解决方案主要是两部分:变更管控 + 配置灰度
- 用工单+审批的方式,让配置变更流程化、正规化,提升配置变更的被重视程度。
- 利用配置灰度发布平台功能,通过测试和灰度多环境的上线前验证加上版本可回滚的能力,减少由于配置问题造成的可用性降级。

Level2: 代码BUG
人为BUG往往是系统异常的罪魁祸首。coder? 不,请叫我buger ~ 虽然最是常见,但这一部分又是相对最容易应对的。
解决方案有两个方面:
把控研发质量 + 测试质量:
- 需要通过系统分析文档的撰写和评审提前分析业务问题和系统边界。
- 通过容错设计、单侧、CR来完善代码的健壮性。
- 通过测试分析来明确测试重点和影响点。
- 通过线上请求录制回放等仿真测试来保证原有的逻辑不受影响。

Level3: 依赖服务故障
业务高速发展,系统被水平垂直拆分,越来越复杂,几乎没有哪个系统可以独立存在,总归会有依赖。
然而,依赖系统在整个业务流程中占比很重,但我们自己又无法把控,因此,服务的依赖治理,是可用性保障中的非常重要的一环。
解决方案包括:
依赖梳理+指标约定+故障解决
- 首先,要根据业务本身的情况,梳理出强弱依赖,不同级别的依赖区分应对。比如,弱依赖就可以剥离主链路,采用异步或离线等方式进行;而强依赖如RPC中间件,就只能增加监控,提高问题发现速率。
- 其次,定制指标,做好指标监控和百分位预警。比如对依赖系统的调用量预估以及sla约定,达到百分位阈值时,及时报警
- 再次,制定故障预案,如主链路的限流、弱依赖的熔断等。预案需要多次演练才能上线。

Level4: 突发流量和流量洪峰对应不足
让业务按我们预先计划的线路增长是不切实际的。吭哧瘪肚做个需求想让它涨10%,结果没涨反而掉了,当你不注意的时候,突然来了一波上涨,都是很常见的事~
应对方法有两个方面:
流量规律预估 + 异常流量防护
- 规律方面,要分析业务规律,合理安排策略,如请求排队,提前扩容等。如打车场景,流量高峰(上下班)和流量突发(雨雪大风天)的情况都非常典型。为啥经常遇到司机吐槽接不到单,为啥一到雨雪天就要从派单模式切换成抢单模式,真的是因为选择性突然变多了么~
- 异常流量方面,要让上游协助减少无效重试,用缓存等策略防止底层服务雪崩。如电商商品详情系统,一到晚上流量就徒增,爬虫无疑;再如系统超时导致用户不断刷新的流量放大
Level5: 容量预估不足
上述的流量预估其实属于容量预估的一个方面,除此之外,还有缓存容量、底层数据存储容量、服务器容量、带宽容量等等。
应对方案有四个方面:
容量规划+限流降级+冗余+全链路压测
- 前期,需要做好容量规划和容量预警方案,争取把可能的突发流量都考虑在内,核心模块尽量实现冗余部署、容灾部署;同时,利用多维度的报警,尽量早和及时的发现容量问题。
- 故障发生时,依据前面提到的依赖服务治理方案,根据重要程度的不同,进行限流、降级或熔断。减少对容量的持续冲击。
- 故障发生后,利用冗余部署,快速切换路由,分担当前单元的容量压力。
- 单服务压测只能摸到当前服务的高度,但是这个高度是否满足全链路的要求,就需要全链路去呀,这个时候,全局统一的路由、影子库等的基础建设就至关重要了。
Level6: 硬件甚至整个机房故障
相比于动则百万造价的大型服务器,普通计算机以及docker的稳定性要大打折扣。因此,宕机是难免的事,除了服务器,还有交换机甚至是光纤抖动都有可能发生。
而应对方案有两个方面:分散+冗余:
- 正所谓不要把鸡蛋都装到一个篮子里,而要多分几个篮子装。这样,一个篮子打了,不至于影响全部鸡蛋。蚂蚁的单元化部署就是这个思路,不同的用户按ID分到不同的处理单元,因此,就算这个单元全宕了,最差的情况也只会影响到这个单元的用户群。
- 冗余,则是有备无患的思想。主从互备、同城机房互备、两地三中心、三地五中心则是这个思路的具体落地。
Part Three 总结
越是重要的系统,对高可用的要求越高。而高可用的治理,会很考验整个技术团队的技术沉淀。如果后面大家遇到对系统可用性非常敏感的情况,希望本文可以对大家的思路和着手点有所帮忙。