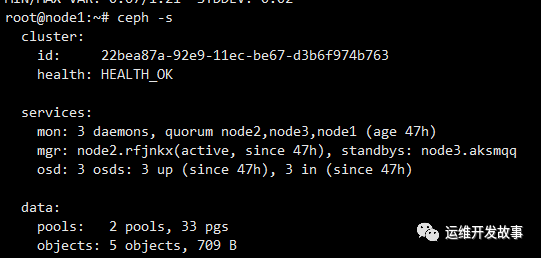
本文主要介绍ceph16版本集群节点系统磁盘故障后的集群恢复,虽然系统盘很多都是做了raid1,但从实际做的项目看,总是有很多未知意外发生,节点挂掉后,上面的mon和osd,mgr都会down掉,如果所在节点的mgr服务是激活状态,则其他节点所在的备用节点将会升级为激活状态。
移除问题主机
节点挂掉后,在确定不能继续开机进入系统的情况下,需要在其他正常的节点将故障节点进行移除,此次宕机的节点为node4,以下命令可能会导致数据丢失,因为 osd 将通过调用每个 osd 来强制从集群中清除。
ceph orch host rm node4 --offline --force
节点初始化操作
将node4节点即故障节点更换新的系统盘并重新安装系统,重装后node4主机名我修改成了node1,并更换了新的ip,在三台ceph节点上重新添加hosts解析
192.168.1.1 node1
192.168.1.2 node2
192.168.1.3 node3
将公钥添加至新主机。
ssh-copy-id -f -i /etc/ceph/ceph.pub node1
安装docker环境。
curl -sSL https://get.daocloud.io/docker | sh
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
安装cephadm以及ceph-common。
# curl --silent --remote-name --location https://github.com/ceph/ceph/raw/pacific/src/cephadm/cephadm
# chmod +x cephadm
# ./cephadm add-repo --release pacific
# ./cephadm install
# ./cephadm install ceph-common
向集群中添加新节点
在ceph集群添加新主机。
[root@node2 ~]# ceph orch host add node1
Added host 'node1'
添加后的主机列表可通过以下命令查看。
ceph orch host ls
之后会自动安装mon以及crash等服务,还有node-exporter监控agent,但是新添加的节点上还不能进行ceph集群操作,因为新添加的节点上缺少ceph集群管理的密钥环,在上面的命令中其实可以看到新加的node1是缺少一个_admin标签的,这里提一下ceph是有几个特殊的主机标签的,以_开头的属于ceph主机的特殊标签,将_admin标签添加到这台新节点,就会导致cephadm 将配置文件ceph.conf和密钥环文件ceph.client.admin.keyring分发到新节点上,这里我们把_admin标签添加至新节点,这样可以在新节点上执行ceph集群的操作。
ceph orch host label add node1 _admin
或者在添加节点时就可以把标签添加上
ceph orch host add node1 --labels=_admin
添加osd
之前想着原有的故障节点的osd直接恢复到现有集群上,后来发现虽然是恢复回去了,但是osd的daemon没有被cephadm所管理,osd的容器也没有被创建,因此还是把原来故障节点的osd给格式化了,重新添加的osd,不过这里还是把我恢复的操作写一下吧。先创建一个空的osd。
# vceph osd create
2
然后激活bluestore-osd的tmpfs目录 由于bluestore中osd的目录是以一个tmpfs的形式存在的,所以被umount掉了以后需要重新激活。
ceph-volume lvm activate (osdid) (fsid)
- PS:这里的osdid就是我刚创建的,osdid为2,后面的fsid不是集群的fsid,而是这个osd自己的fsid,获取方式可以直接执行ll /dev/ceph*查看,osd-block-后面的即为osd的fsid。
然后添加auth和crush map,重启osd。
ceph auth add osd.2 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-2/keyring
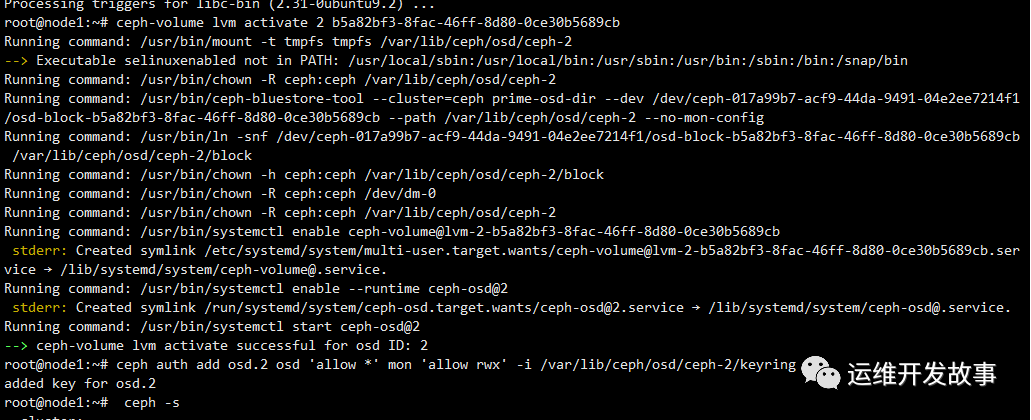
 之后三个osd都会up,但是存在osd的daemon不被cephadm管理的问题,因此我还是删掉这个osd,重新格式化后添加的,删除osd的操作如下:
之后三个osd都会up,但是存在osd的daemon不被cephadm管理的问题,因此我还是删掉这个osd,重新格式化后添加的,删除osd的操作如下:
ceph orch ps --daemon_type osd
#查看osd对应的容器id,先停止容器,我这里没有osd容器启动,所以这步可以忽略
ceph osd out 2
ceph osd crush remove osd.2
ceph auth del osd.2
ceph osd rm 2
上步只是在ceph删除,还需要在磁盘上进行格式化。
# 显示当前设备的状态
# dmsetup status
# 删除所有映射关系
# dmsetup remove_all
# 格式化刚才删除的osd所在磁盘
mkfs -t ext4 /dev/vdb
重新添加osd。
ceph orch daemon add osd node1:/dev/vdb
此时集群就恢复正常了。