今天给大家分享一篇我对学习 RocketMQ 系统架构核心知识点的梳理和总结,在讲解时力求精简、通俗易懂,通过图解来给正在学习 RocketMQ 的小伙伴带来帮助。RocketMQ 是阿里巴巴的分布式消息中间件,在 2012 年开源,在 2017 年成为 Apache 顶级项目。
1 集群架构
RocketMQ 的集群架构如下图:
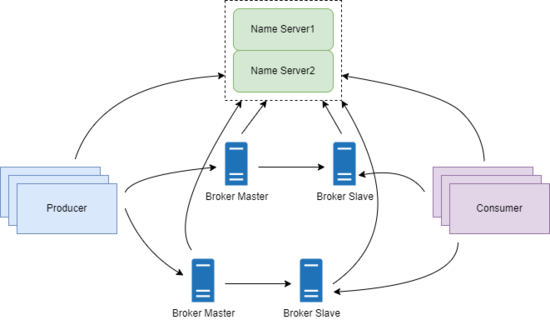
从上图可以看到,整个集群中有四个角色: Name Server集群、Broker主从集群、Producer、Consumer。
1.1 Name Server 集群
Name Server 集群部署,但是节点之间并不会同步数据,因为每个节点都会保存完整的数据。因此单个节点挂掉,并不会对集群产生影响。
1.2 Broker
Broker 采用主从集群,实现多副本存储和高可用。每个 Broker 节点都要跟所有的 Name Server 节点建立长连接,定义注册 Topic 路由信息和发送心跳。
跟所有 Name Server 建立连接,就不会因为单个 Name Server 挂了影响 Broker 使用。Broker 主从模式中, Slave 节点主动从 Master 节点拉取消息。
1.3 Producer
Producer 跟 Name Server 的任意一个节点建立长连接,定期从 Name Server 拉取 Topic 路由信息。Producer 是否采用集群,取决于它所在的业务系统。
1.4 Consumer
Consumer 跟 Name Server 的任意一个节点建立长连接,定期从 Name Server 拉取 Topic 路由信息。Consumer 是否采用集群,取决于它所在的业务系统。
Producer 和 Consumer 只跟任意一个 Name Server 节点建立连接,因为 Broker 会向所有 Name Server 注册 Topic 信息,所以每个 Name Server 保存的数据其实是一致的。
2 MessageQueue
Producer 发送的消息会在 Broker 的 MessageQueue 中保存,如下图:
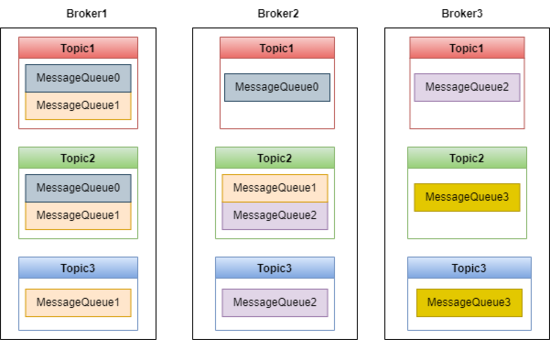
有了 MessageQueue ,Topic 就可以在 Broker 中实现分布式存储,如上图,Broker 集群中保存了 4 个MessageQueue,这些 MessageQueue 保存了 Topic1-Topic3 这三个 Topic 的消息。
MessageQueue 类似于 Kafka 中的 Partition,有了 MessageQueue,Producer 可以并发地向 Broker 中发送消息,Consumer 也可以并发地消费消息。
默认 Topic 可以创建的 MessageQueue 数量是 4,Broker 可以创建的 MessageQueue 数量是 8, RocketMQ 选择二者中数量小的,也就是 4。不过这两个值都可以配置。
3 Consumer
RocketMQ的消费模式如下图:
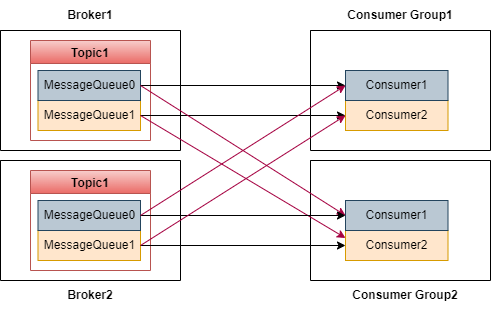
图中,Topic1 的消息写入了两个 MessageQueue,两个队列保存在 Broker1 和 Broker2 上。
RocketMQ 通过 Consumer Group 实现消息广播。比如上图中有两个消费者组,每个消费者组有两个消费者。
一个消费者可以消费多个 MessageQueue,但是同一个 MessageQueue 只能被同一个消费者组的一个消费者消费。比如 MessageQueue0 只能被 Consumer Group1 中的 Consumer1 消费, 不能被 Consumer2 消费。
4 Broker 高可用集群
Broker 集群如下图:
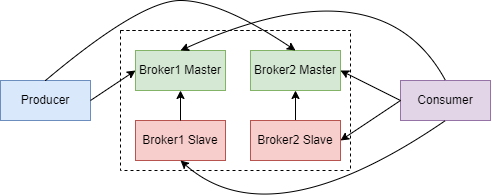
Broker 通过主从集群来实现消息高可用。跟 Kafka 不同的是,RocketMQ 并没有 Master 节点选举功能,而是采用多 Master 多 Slave 的集群架构。Producer 写入消息时写入 Master 节点,Slave 节点主动从 Master 节点拉取数据来保持跟 Master 节点的数据一致。
Consumer 消费消息时,既可以从 Master 节点拉取数据,也可以从 Slave 节点拉取数据。 到底是从 Master 拉取还是从 Slave 拉取取决于 Master 节点的负载和 Slave 的同步情况 。如果 Master 负载很高,Master 会通知 Consumer 从 Slave 拉取消息,而如果 Slave 同步消息进度延后,则 Master 会通知 Consumer 从 Master 拉取数据。总之,从 Master 拉取还是从 Slave 拉取由 Master 来决定。
如果 Master 节点发生故障,RocketMQ 会使用基于 raft 协议的 DLedger 算法来进行主从切换。
Broker 每隔 30s 向 Name Server 发送心跳,Name Server 如果 120s 没有收到心跳,就会判断 Broker 宕机了。
5 消息存储
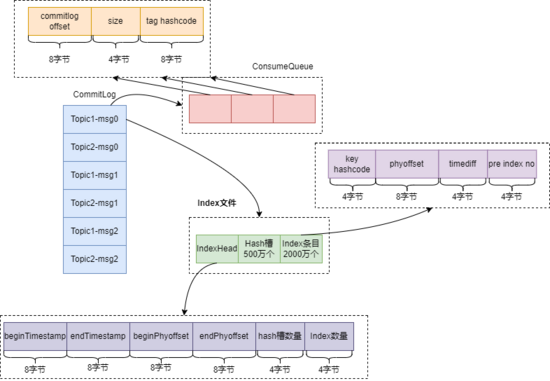
RocketMQ 的存储设计是非常有创造性的。存储文件主要有三个:CommitLog、ConsumeQueue、Index。如下图:
5.1 CommitLog
RocketMQ 的消息保存在 CommitLog 中,CommitLog 每个文件 1G 大小。有趣的是,文件名并不叫 CommitLog,而是用消息的偏移量来命名。比如第一个文件文件名是 0000000000000000000,第二个文件文件名是 00000000001073741824,依次类推就可以得到所有文件的文件名。
有了上面的命名规则,给定一个消息的偏移量,就可以根据二分查找快速找到消息所在的文件,并且用消息偏移量减去文件名就可以得到消息在文件中的偏移量。
R oc ketMQ 写 CommitLog 时采用顺序写,大大提高了写入性能。
5.2 ConsumeQueue
如果直接从 CommitLog 中检索 Topic 中的一条消息,效率会很低,因为需要从文件的第一条消息开始依次查找。引入了 ConsumeQueue 作为 CommitLog 的索引文件,会让检索效率大增。
刚开始不理解 ConsumeQueue 和 MessageQueue 的区别,网上查了一些资料发现,每个ConsumeQueue对应一个上面介绍的 MessageQueue,MessageQueue 只是一个概念模型。
ConsumeQueue 中的元素内容如下:
- 前 8 个字节记录消息在 CommitLog 中的偏移量。
- 中间 4 个字节记录消息消息大小。
- 最后 8 个字节记录消息中 tag 的 hashcode。
这个 tag 的作用非常重要,假如一个 Consumer 订阅了 TopicA,Tag1 和 Tag2,那这个 Consumer 的订阅关系如下图:

可以看到,这个订阅关系是一个 hash 类型的结构,key 是 Topic 名称,value 是一个 SubscriptionData 类型的对象,这个对象封装了 tag。
拉取消息时,首先从 Name Server 获取订阅关系,得到当前 Consumer 所有订阅 tag 的 hashcode 集合 codeSet,然后从 ConsumerQueue 获取一条记录,判断最后 8 个字节 tag hashcode 是否在 codeSet 中,以决定是否将该消息发送给Consumer。
5.3 Index 文件
RocketMQ 支持按照消息的属性查找消息,为了支持这个功能,RocketMQ 引入了 Index 索引文件。Index 文件有三部分组成,文件头 IndexHead、500万个 hash 槽和 2000 万个 Index 条目组成。
5.3.1 IndexHead
总共有 6 个元素组成,前两个元素表示当前这个 Index 文件中第一条消息和最后一条消息的落盘时间,第三、第四两个元素表示当前这个 Index 文件中第一条消息和最后一条消息在 CommitLog 文件中的物理偏移量,第五个元素表示当前这个 Index 文件中 hash 槽的数量,第六个元素表示当前这个 Index 文件中索引条目的个数。
查找的时候除了传入 key 还需要传入第一条消息和最后一条消息的落盘时间,这是因为 Index 文件名是时间戳命名的,传入落盘时间可以更加精确地定位 Index 文件。
5.3.2 Hash 槽
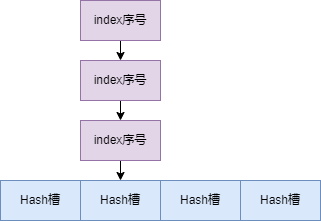
熟悉 Java 中 HashMap 的同学应该都比较熟悉 Hash 槽这个概念了,其实就是 Hash 结构的底层数组。Index 文件中的 Hash 槽有 500 万个数组元素,每个元素是 4 个字节 int 类型元素,保存当前槽下最新的那个 index 条目的序号。
这里 Hash 槽解决 Hash 冲突的方式是链表法,如下图:
5.3.3 Index 条目
每个 Index 条目中,key 的 hashcode 占 4 个字节,phyoffset 表示消息在 CommitLog 中的物理偏移量占 8 个字节,timediff 表示消息的落盘时间与 header 里的 beginTimestamp 的差值占 4 个字节,pre index no 占 4 个字节。
pre index no 保存的是当前的 Hash 槽中前一个 index 条目的序号,一般在 key 发生 Hash 冲突时才会有值,否则这个值就是 0,表示当前元素是 Hash 槽中第一个元素。
In dex 条目中保存 timediff,是为了防止 key 重复。 查找 key 时,在 key 相同的情况下, 如果传入的时间范围跟 timediff 不满足,则会查找 pre index no 这个条目。
5.3.4 本节总结
通过上面的分析,我们可以总结一个通过 key 在 Index 文件中查找消息的流程,如下:
- 计算 key 的 hashcode;
- 根据 hashcode 在 Hash 槽中查找位置 s;
- 计算 Hash 槽在 Index 文件中位置 40+(s-1)*4;
- 读取这个槽的值,也就是Index条目序号 n;
- 计算该 index 条目在 Index 文件中的位置,公式:40 + 500万 * 4 + (n-1) * 20;
- 读取这个条目,比较 key 的 hashcode 和 index 条目中 hashcode是否相同,以及 key 传入的时间范围跟 Index 条目中的 timediff 是否匹配。如果条件不符合,则查找 pre index no 这个条目,找到后,从 CommitLog 中取出消息。
6 刷盘策略
Rocket MQ 采用灵活的刷盘策略。
6.1 异步刷盘
消息写入 CommitLog 时,并不会直接写入磁盘,而是先写入PageCache 缓存中,然后用后台线程异步把消息刷入磁盘。异步刷盘策略就是消息写入 PageCache 后立即返回成功,这样写入效率非常高。如果能容忍消息丢失,异步刷盘是最好的选择。
6.2 同步刷盘
即使同步刷盘,RocketMQ 也不是每条消息都要刷盘,线程将消息写入内存后,会请求刷盘线程进行刷盘,但是刷盘线程并不会只把当前请求的消息刷盘,而是会把待刷盘的消息一同刷盘。同步刷盘策略保证了消息的可靠性,但是也降低了吞吐量,增加了延迟。
7 总结
本文用 7 张图总结了 RocketMQ 的核心知识,希望能带你快速入门。