













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
百度新研究,登上了Nature子刊。
科技公司卷到学术圈顶刊上不算稀奇。
但这次有点不同寻常。
研究领域与生物领域直接相关,接收该论文的期刊Nature Machine Intelligence(NMI),影响因子达到了16.649。

除了专业度保障,研究的实验结果也超越MIT斯坦福。
而且更关键的在于,跟后者大部分“产学研”模式不同。
百度是实打实自己独立搞出来的——
作者全部来自螺旋桨PaddleHelix,百度生物计算团队。
嗯,还是可复现的那种,目前GitHub上已经开源了完整代码(地址可在文末获取)。
研究人员表示,相关部分项目已经实现了商业化落地。
来看看究竟是一项什么样的研究。
小分子3D结构被AI整明白了
此次百度聚焦的研究,是小分子化合物性质预测。
简单来说,通过小分子结构来预测其性质,帮助药物研发的早期探索,从而解决该领域成本高、时间长、成功率低等难题。
小分子药物结构有良好的空间分散性,其化学性质也更有助于成药,因此相较于大分子药物(蛋白质、核酸等)在药物研发上更有优势。市场上大部分药物也属于小分子药物。
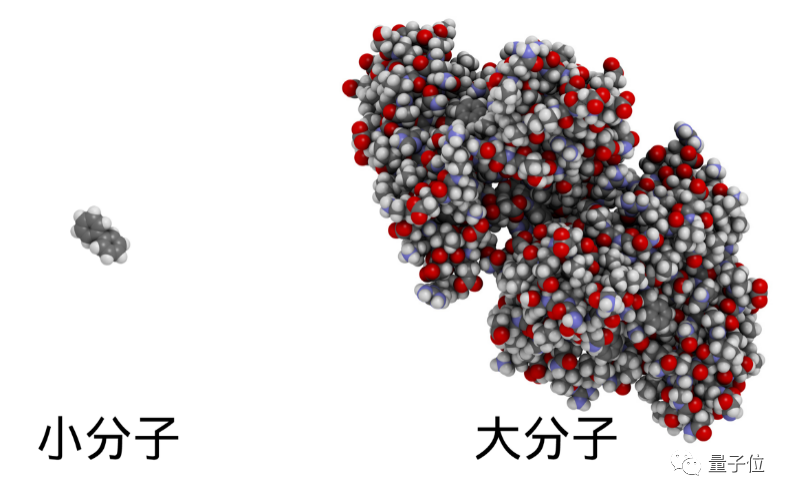
但即便有先天优势,面临的特殊挑战也不小。
最大的挑战,莫过于小分子的筛选空间实在是太大了。
早前Nature一篇研究表明,小分子药物研发筛选数量在10的60次方。
什么概念呢?作者形容,“比太阳系的原子数量还要多”。
要在这样一个庞大「小分子宇宙」中寻求合适的候选药物,高效准确的化合物表征就起到关键作用。
基于这样的背景下,研究团队此次的研究提出了几何增强型的分子表征方法,简称GEM。
这个方法主要包含两个部分:基于空间结构的图神经网络GNN、以及多个几何级别的自监督学习。
不难看出,本次研究的亮点在于空间、几何。
据介绍,这是业界首次将空间结构引入到化合物建模当中。
之所以这样强调,跟他们要解决的问题不无关系,那就是让AI也能理解小分子的3D结构。
个中原因,需要从现有表征方式说起。
目前研究主要有两种表征方式:基于序列的一维表征和基于图形的表征。
一个以字符串作为输入,利用序列模型比如RNN和Transformer来学习分子表征,但存在一些明显的局限性,比如字符串语法难以理解,两个相邻的原子在文本序列上可能相距甚远;字符串的一个小变化可能导致分子结构的大变化。
另一个则与今天的研究相关——GNN建模,以图作为输入,每个原子是一个节点,每个化学键是一个边。
嗯,就跟化学书那样式儿的。
但多数研究只停留分子的二维信息,忽略了三维空间结构。
这也不难理解,毕竟要想准确获得分子的三维结构信息其实并不容易。
要是所选描述三维结构的参数一旦不理想,其性能可能上述两种表征方法更糟,还将面临鲁棒性不足和预测性能不理想等问题。
但即便如此,三维结构信息却很关键,因为往往决定了分子的物理化学性质及生物活性的不同。
最典型的例子,就是高中学的同分异构体。
以二氯乙烯为例,它就有顺反式结构,因为几何结构不同,导致二者的水溶性不同。
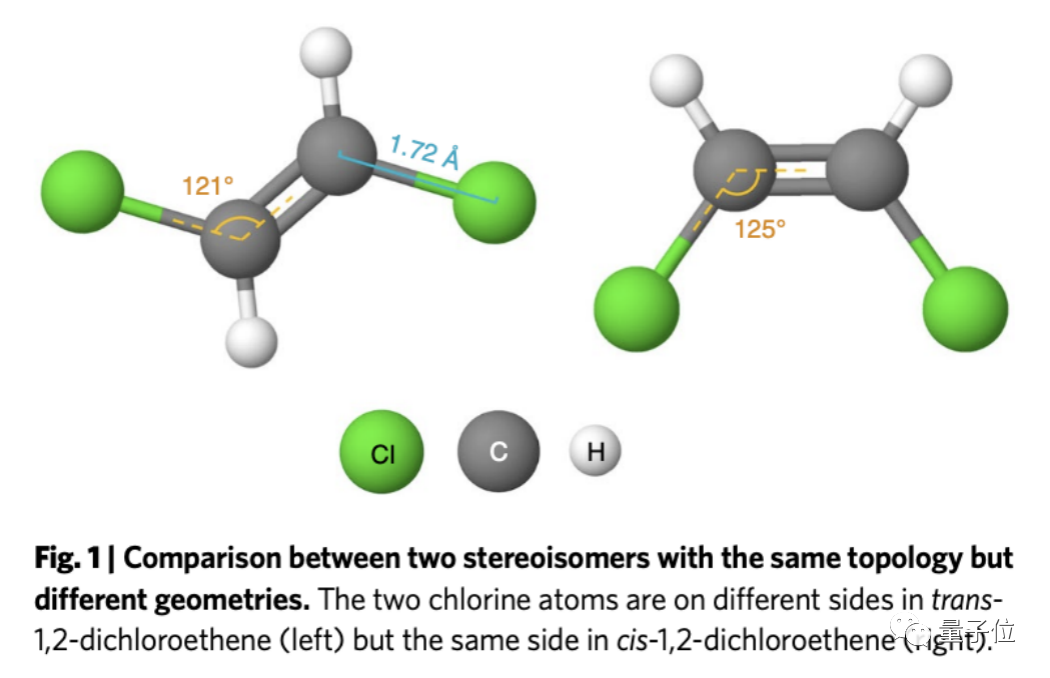
还有像顺铂和反铂(二氯二氨合铂),顺铂是一种流行的抗癌药物;但反铂有毒却没有抗癌活性。
既然如此,那就来看看这项研究是如何解决的。
首先来看图神经网络,本次研究人员提出了一种GeoGNN。每个分子的输入包含两个图,可同时模拟原子、键和键角的影响。
第一个图,即二维结构图,也叫做原子-化学键图,仍以原子为节点,键为边。
第二个图,化学键-键角图,则是以键视作节点,键角视作边。
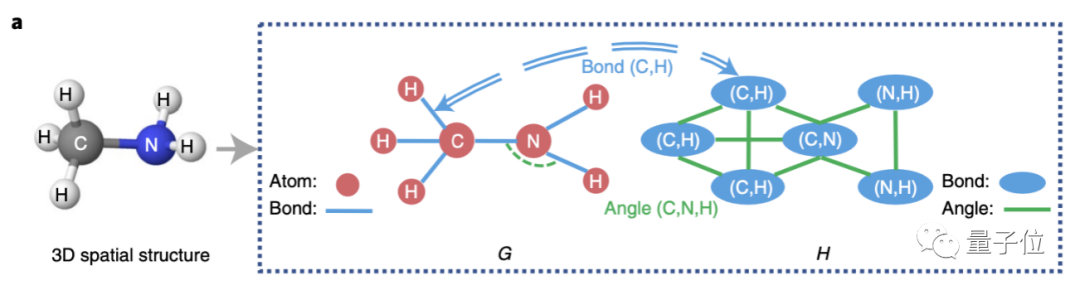
GeoGNN经过多轮迭代学习原子和键的表征向量,为了连接两个图,化学键作为每一轮迭代中图G和图H的桥梁进行信息互通。
最后通过汇集原子表征得到分子表征,用来化合物性质预测。
为了更好的学习分子空间知识,除了以几何信息作为输入,进一步地,研究团队设计了多项自监督学习任务。
比如,预测化学键的长度、化学键组成的键角、两两原子之间的距离。
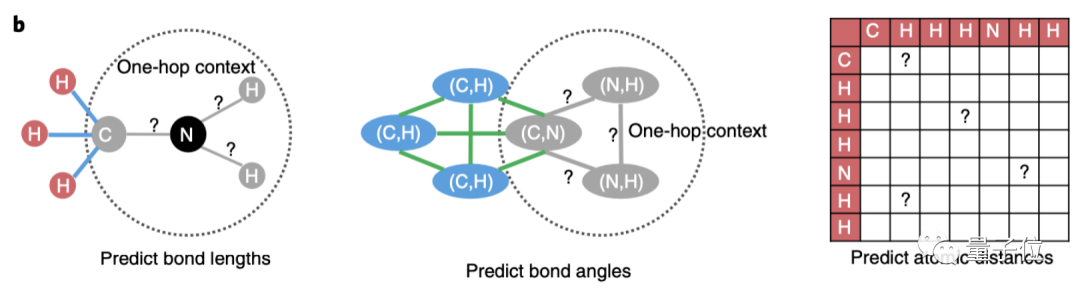
其中,键长和键角描述化合物的局部结构,两两原子之间的距离更关注化合物的全局结构。
局部结构的,就随机挑选某个原子中心(图中的N)的子图进行遮盖,预测化学键的键长和之间的键角。
全局结构的,则是预测原子距离矩阵中的元素。
预训练过程中,团队从一个公开数据集Zinc1522中,抽取2000万个未标记的分子来训练GeoGNN。
其中90%的分子用来训练,其余分子进行测试。
最终结果显示,在当前公认化合物性质预测数据集MoleculeNet21的15个基准数据集中,与现有方法比较,得到了14个SOTA结果。
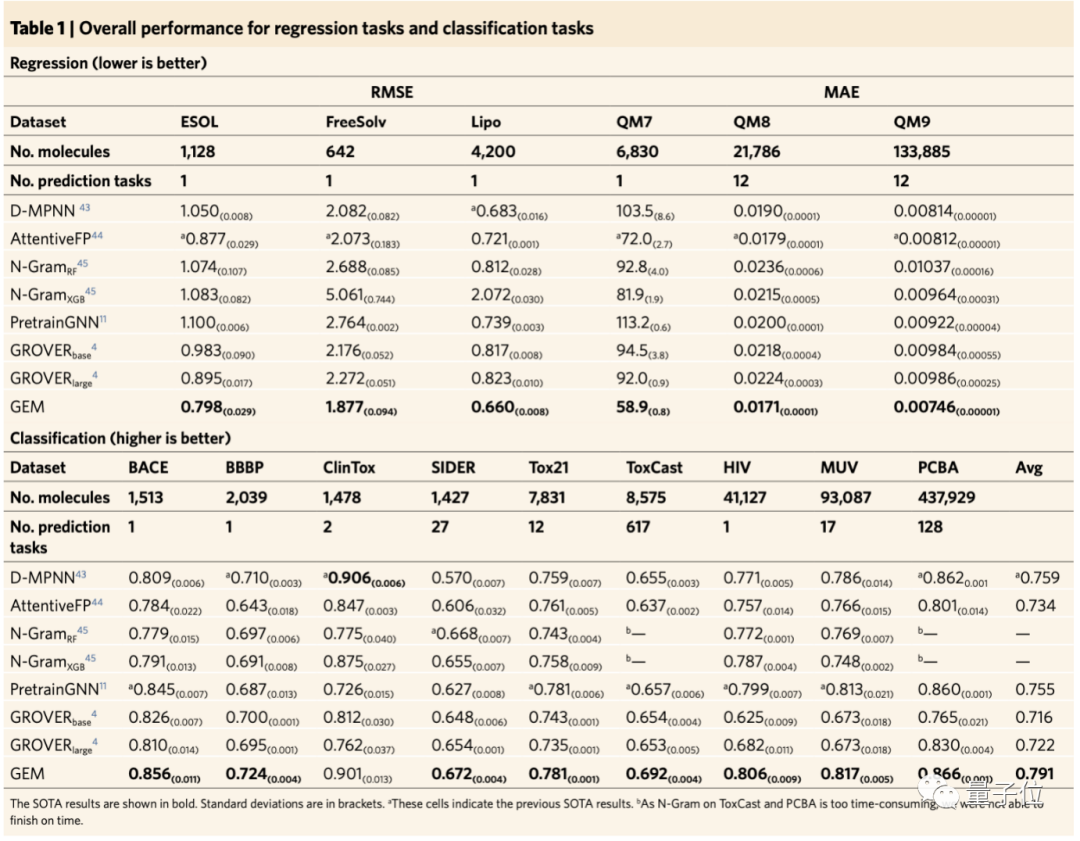
其中,像与毒性相关的数据集tox21、toxcast,以及HIV病毒数据集,GEM的表现比其他模型要好,比如腾讯的GROVER、斯坦福的PretrainGNN以及MIT的D-MPNN等。
总体而言,百度的GEM模型,在回归任务上相对现在方法提升8.8%,在分类任务上相对提升4.7%。
可以看到,在回归数据集上的结果比分类数据集上的改进更大。团队猜测,因为回归数据集的重点是预测量子化学和物理化学特性,而这与分子几何结构高度相关。
进一步地,团队研究了GeoGNN在没有预训练的情况下,在回归数据集上的表现有何影响。
结果与现有的GNN架构比较,其中包含常用GNN架构、结合三维分子几何的架构以及分子表征架构。
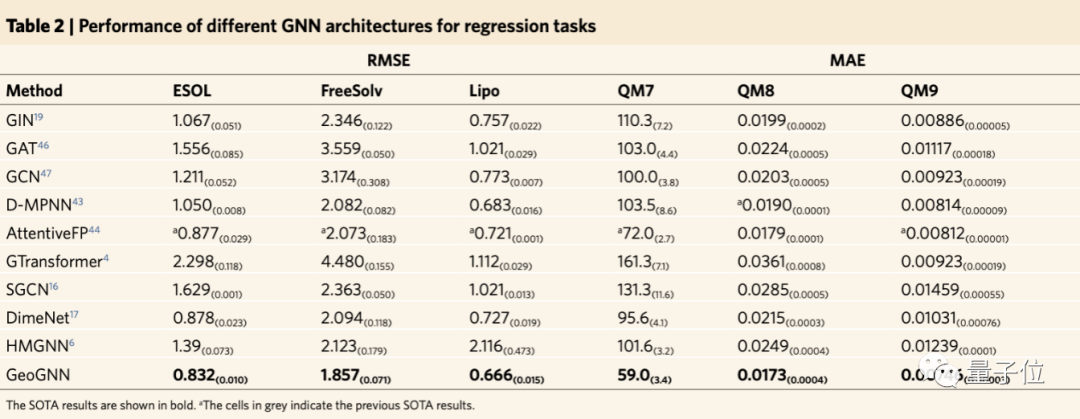
与以往最优结果相比,总体改进7.9%。
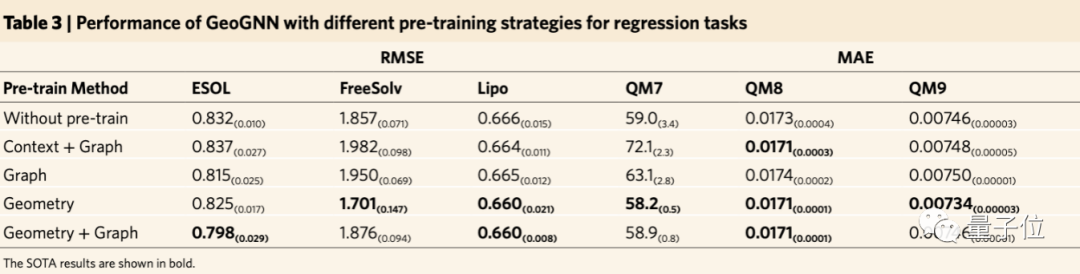
此外,在自监督学习方法上的消融实验也证明了基于空间结构的自监督学习方法的有效性。
该项目已经在GItHub上开源。
据介绍,除了在学术期刊亮相外,研究团队透露,这项研究在药物研发领域已经实现商业化落地,在合作伙伴的早期药物筛选管线上得到应用。
未来,这项技术还有更多可预见的应用价值,比如像化合物成药性预测、小分子的药物筛选、药物联用等具体场景。
再拓展一点,没准儿在蛋白质、核酸等领域,也能构建基于大分子的表征模型,有助于更多药物研发。

事实上,百度这次在Nature子刊上的亮相,带来计算生物领域的新进展。
情理之外,却是意料之中。
不为大多数人所知道的是,百度在计算生物上的探索,其实早已开启。
曾在GNN顶赛上超越DeepMind
早在2018年,百度就正式启动了计算生物方向的研究。
著名的RNA二级结构开源算法LinearFold,将新冠预测从原来的55分钟提速至27秒(接近120倍),就是百度的研究成果之一。
2020年12月,百度正式将自己研究的一系列生物计算相关技术进行了集成,发布了螺旋桨(PaddleHelix)。
这是一个囊括了各种各样“AI+计算生物”开源工具的生物计算平台,基于百度飞桨框架开发,可以被用于药物研发、疫苗设计和精准医疗等领域。

而这次的研究,正是来自百度螺旋桨团队。
在发表这项研究之前,螺旋桨团队就已经在包括像KDD、NeurIPS、IEEE BIBM等顶会上发表过不少“AI+生物”的研究成果。
例如,一篇用采用多任务学习训练ML模型进行药物虚拟筛选的研究,就于去年年底被生物信息与生物医学顶会IEEE BIBM 2021接收;
除此之外,包括蛋白质、mRNA也有不少研究成果,例如一篇基于蛋白质序列预测蛋白质间相互作用的多模态预训练模型就入选MLCB的Spotlight;
关于图神经网络预测分子性质的相关模型,则更是在全球性的顶会赛事上取得过数一数二的成绩。
例如,去年6月KDD CUP与OGB(Open Graph Benchmark)联合举办了首届图神经网络大赛OGB-LSC,共有包括DeepMind、微软、蚂蚁金服等来自全球的500多个著名高校&机构参与。

其中,OGB是图神经网络的通用性能评价基准数据集,素有“图神经网络的ImageNet”之称;KDD CUP则是目前数据挖掘领域水平最高的顶尖国际赛事。
这场比赛一共分为三场,包括大规模节点分类、大规模图关系预测和化学分子图性质预测。
在化学分子图性质预测赛事中,百度螺旋桨生物计算团队取得了亚军的成绩,冠军来自MSRA和北大等高校机构联合团队,第三名则是DeepMind。
这还只是三场GNN比赛中,与生物计算相关的那场。
在同一赛事的另外两场图神经网络比赛,节点分类和图关系预测中,螺旋桨生物计算平台背后的百度飞桨框架,又接连取得了2个冠军,同样超越了DeepMind等团队。

这些模型与研究并非“纸上谈兵”,有不少成果都已经被落地。
例如,百度与斯微生物合作,针对LinearDesign的mRNA疫苗序列设计算法进行了生物实验,证明模型的关键指标超出基准序列20倍,在疫苗研发中确实有更高的实用价值;
随后百度也与药企赛诺菲签订协议,将LinearDesign用于优化mRNA疫苗的设计研发。
至于更早的研究LinearFold开源算法,则已经被上百家企业用于疫苗设计研究中。
种种迹象都在表明,百度进军生物计算并非一日之谈。
恰恰相反,这项发表在Nature子刊上的研究,正是它在生物计算方面布局了很多年的成果力证。
数据爆炸下的生物科技
百度走的生物科技这条路,其道不孤。
放到整个更大的计算生物领域来看,不止是百度,这几年的国内外科技公司,包括腾讯、阿里、英特尔、三星、谷歌母公司Alphabet等,其实都在加大布局。
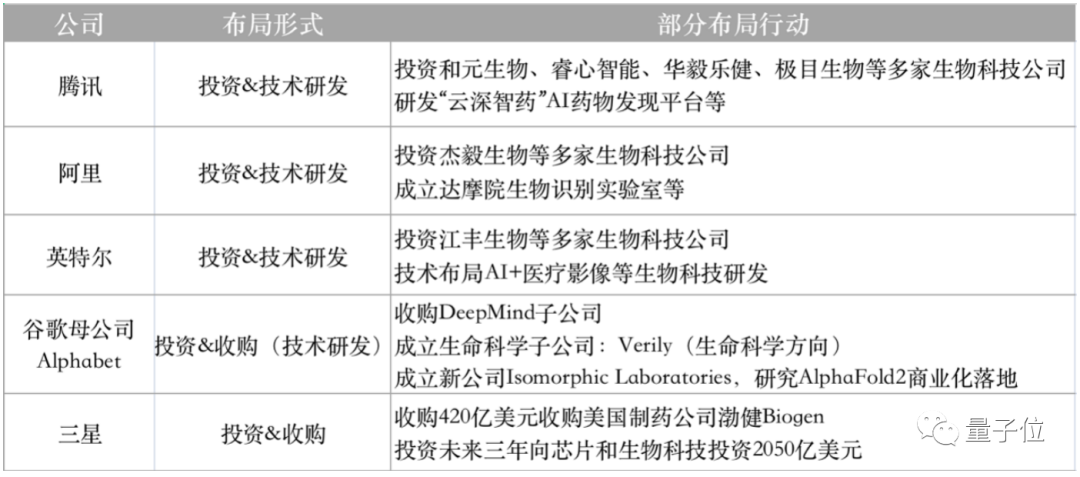
这也与当前所处的科技生长态势有关——生物领域的发展,恰好赶上了数据爆炸的时代,以及AI对过去研究方式的变革。
从技术应用来看,典型代表之一就是AI+新药研发。
数据驱动导向的深度学习技术,给传统的新药研发带来了大量的潜力。
制药领域有一个知名的反摩尔定律:每隔9年,投资10亿美元产出的上市新药就减少一半。更为常见的是,首创药物(First-in-Class)占获批新药总数量不足一半。
相比之下,利用AI则能在包括用ADMET来做性质预测以筛选药物等在内的步骤中,节省大量的人力和物力,包括辉瑞、阿斯利康等传统药企,也开始纷纷增加AI研发投入、或是寻求与AI公司进行合作。
而AI+新药研发,还只是生物科技爆发中的一小部分技术应用。
放大到整个行业来看,科技对生物领域的促进,本身就正在成为不可抵挡的趋势之一。
此前量子位智库发布的“2021十大前沿科技趋势”中,与生物相关的技术突破就占据了接近一半:
除了利用AI助力新药研发以外,还有CRISPR基因编辑、侵入式脑机接口的落地应用、利用AI预测蛋白质结构的模型AlphaFold2。

从产业来看,像百度这样的AI公司重仓研究,反过来又说明了AI给生物科技领域带来的潜力和价值。
2018年开始,百度就研发RNA二级结构预测等算法,到后来李彦宏亲自创立百图生科公司,再到与传统药企赛诺菲等合作进行算法研究落地;
李彦宏也不止一次强调过自己对这一领域的看好:
依靠生物计算引擎,能够有效利用大量的生物数据,把药物发现的“大海捞针”变成“按图索骥”。

不止百度。春江水暖总是技术公司先知。
谷歌母公司Alphabet就在不久前,宣布成立一家新公司Isomorphic Laboratories,研究如何将AlphaFold2在AI+新药研发方向的能力进行商业化落地。
OpenAI也在尝试利用AI模型,训练出能够诊断疾病和预测复杂蛋白质结构等能力的复杂系统……
AI+生物科技,正在成为产业界落地趋势的一种新“共识”。
21世纪是生物的世纪。诚不我欺?
论文链接:
https://www.nature.com/articles/s42256-021-00438-4
GitHub链接:https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/pretrained_compound/ChemRL/GEM





























