遗留系统的现代化演进是一门艺术。
Why 开源 + 遗留系统现代化工具
在日常的软件开发里,我们经常会遇到一系列的问题,诸如于:
- 如何解决人类智商不够的问题?模式、原则和工具
- 谁应该去解决代码的问题?代码
- ……
应对于这些问题,其中的一个解决方案就是: 自动化的工具 ,有些人喜欢称之为 器 。支撑这些工具的便是一系列的 原则 与 模式 ,将它们融入到工具之中。另外一个解决人成长的方案就是:元元(meta-meta),这是另外一个故事。
遗留系统是常态。多数时候,我们所遇到的系统里多数是遗留系统,来到一个新项目时,可能就需要对他们快速的分析,以提供洞见 —— 写 PPT 汇报。所以,在过去的几年里,咨询团队也沉淀了一系列的遗留系统分析和重构的工具,比如新哥的 Tequila、正在开源的架构分析和守护工具 ArchGuard 等等。除此,在有些重构项目里,还要编写定制的工具来进行分析。
技术热情发电。主要的挑战是,我们需要拿自己的业余时间来完善工具。
既然要用自己的时间来开发,还和项目没有关系,这种 用爱发电 的事情,用开源的方式最合适了。
我们需要怎样的工具?
从对于使用工具的结果来看,我们需要这个现代化工具是:
特定坏味道。不同的开发团队会有不同的坏味道,有些坏味道是无法由 Sonarqube 这样的工具识别的。
自动化重构。基于已知的坏味道,对应的代码位置信息,对代码进行自动化重构。
- 可视化驱动。快速生成项目的分析结果,并展示出来给开发人员了解现状,还有编写 PPT。
- 必要的交互性。用于在重构的过程中,寻找合适的切入点。
- 定制化开发。
- 适当的语法精准度。更高的语法精准度,意味着更高的开发成本,需要有针对地平衡它们。
- 多平台。我们用的是 macOS,而多数时候,客户使用的是 Windows。
如何开发这样的工具?
这里定义的遗留系统现代化工具包含了这么几部分:语法分析、结果及可视化、自动化重构、架构守护。
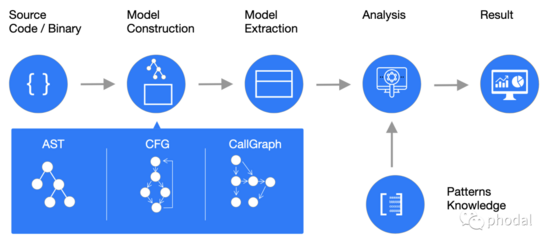
语法分析
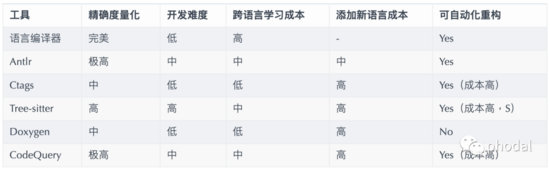
对代码进行语法分析,生成特定的语言的数据结构。常用的工具有:Antlr、Ctags、TreeSitter、Doxygen、CodeQuery 等。一个大致的对比(拍脑袋订的)如下表所示:
结果及可视化
通常来说,我们会出于以下的一些情况,来对遗留系统进行可视化:
- 数值化。如针对于特定的 smell 进行自动化重构,类似于 Sonarqube,常见的模式和原则源自于《重构》一书。在 Coca 里,还引入了在一些论文里看到了测试的 bad smell,诸如于没有断言的测试等。
- 可视化依赖。如针对于代码中的类、包等的依赖情况进行可视化,主要用于分析分层架构等。常用的工具有:PlantUML、Graphviz、D3.js、Echarts 等。
- 代码属性可视化。如针对于文件的修改频率、大小等属性进行可视化,可以获取诸如于单位时间内的文件变化频率。一个文件经常修改,还大量被引用,那说明它是一个不稳定的类、文件,除了业务变化,最有可能就是设计不合理。
- 其它。
自动化重构
这一步是可选的,它取决于我们的场景。通常来说,编写这样的功能主要弥补是现代化的 IDE 无法完成的工作,诸如于:
- 多代码库间的未使用类删除。
- 多代码库间的聚类。
- 针对于 CSS 颜色的重构。
架构守护
编写架构的守护规则,以对于系统的架构进行守护,用的工具有:ArchUnit、ArchGuard 等。在参考了 ArchUnit 的语法之后,我们也设计了一个多语言的架构守护工具:Guarding。
在开发这些工具的过程中,它们也不断地 push 着我进一步学习语言背后的东西,如编译原理(语言的前端部分),理解构建系统(build system)等。
遗留系统现代化工具集
为了更有针对性地对遗留系统进行现代化,最近我们创建了一个新的组织:Modernizing,集合了先前开发的一系列工具。并创建了:awesome-modernization 用于对其它的一系列相关的工具进行收集。
在 Modernizing 里,针对于单个编程语言的工具有:
- 针对于 Java 语言的系统重构、系统迁移和系统分析的工具: Coca ,Go 语言,GitHub stars:691。Coca 是一个“全功能”的重构工具,基于 Antlr 进行语法分析的,除了常规的可视化、调用分析,还可以进行自动化重构。Coca 一名的由来是:对标新哥写的 Tequila —— 龙舌兰酒 vs 快乐水。
- 针对于 CSS/LESS/CSS 的分析和自动化重构工具: Lemonj ,TypeScript 语言,GitHub stars:128。当时设计的主要目的是:用来对 CSS 中的颜色进行提取,基于 Antlr 的语法树分析,可以用于进行自动化的重构。
- 针对于 MySQL 代码进行自动化分析,并从中构建中 UML,并生成其关系的: SQLing ,Go 语言,使用 PingCap 的 SQL 解析器解析。当然了,还有一个初始化的针对于 PL/SQL 的版本:pling。
- 适用于 Ant 转 Maven 的半自动化工具: Merry ,Go 语言 + Antlr。
- 前端规范化改造工具: Clij ,用于一键添加 eslint、husky、lint-staged 等,TypeScript 语言。
针对于多语言的工具,我们有:
- 基于 Antlr 的多语言的语言模型分析工具: Chapi ,Kotlin 语言。其设计的初衷是用于生成 Coca 相同的数据结构,以接入更多的可视化工具。在语法分析上,采用的是 Antlr 进行分析。
- 基于 Doxygen 的多语言分析和可视化工具:Go mod 版本的新哥的 Tequila 。其中,还有一系列的迷之代码,需要重构掉。
- 基于 Ctags 的多语言模型分析和可视化工具: Modeling ,Rust 语言。分析源码,并生成基于模型的可视化依赖。
- 基于 TreeSitter 的多语言架构守护工具: Guarding ,Rust 语言。通过自制的 DSL,来对系统架构进行守护。
除此,还有一个在 Inherd 开源小组下开源的:Coco,它主要是通过代码的物理属性:修改频率 + 目录 + 行数来分析系统的工具。以及现在紧锣密鼓开源中的 ArchGuard。
我们使用一系列不同的语言和工具来开发这些软件,因为不同的场景之下,都会有不同的选择。
下一步?
现有的工具都是分散的,不同工具之前的数据格式不尽相同,缺乏统一的数据格式。在输出格式不统一时,我们就难以进行标准的可视化,诸如于我们正在构建 codecity 用于在元宇宙里,对遗留系统进行可视化,又或者是正在从 ArchGuard 中拆分的前端可视化部分,以用于复用。理想的情况下,它应该像是一个 pipeline 架构的系统,由一系列的 pipe 和 filter 所构成。
欢迎访问我们的 GitHub: https://github.com/modernizing