













场景
在微服务拆分的架构中,各服务拥有自己的数据库,所以常常会遇到服务之间数据通信的问题。比如,B服务数据库的数据来源于A服务的数据库;A服务的数据有变更操作时,需要同步到B服务中。
解决方案
1、 在代码逻辑中,有相关A服务数据写操作时,以调用接口的方式,调用B服务接口,B服务再将数据写到新的数据库中。这种方式看似简单,但其实“坑”很多。在A服务代码逻辑中会增加大量这种调用接口同步的代码,增加了项目代码的复杂度,以后会越来越难维护。并且,接口调用的方式并不是一个稳定的方式,没有重试机制,没有同步位置记录,接口调用失败了怎么处理,突然的大量接口调用会产生的问题等,这些都要考虑并且在业务中处理。这里会有不少工作量。想到这里,就将这个方案排除了。
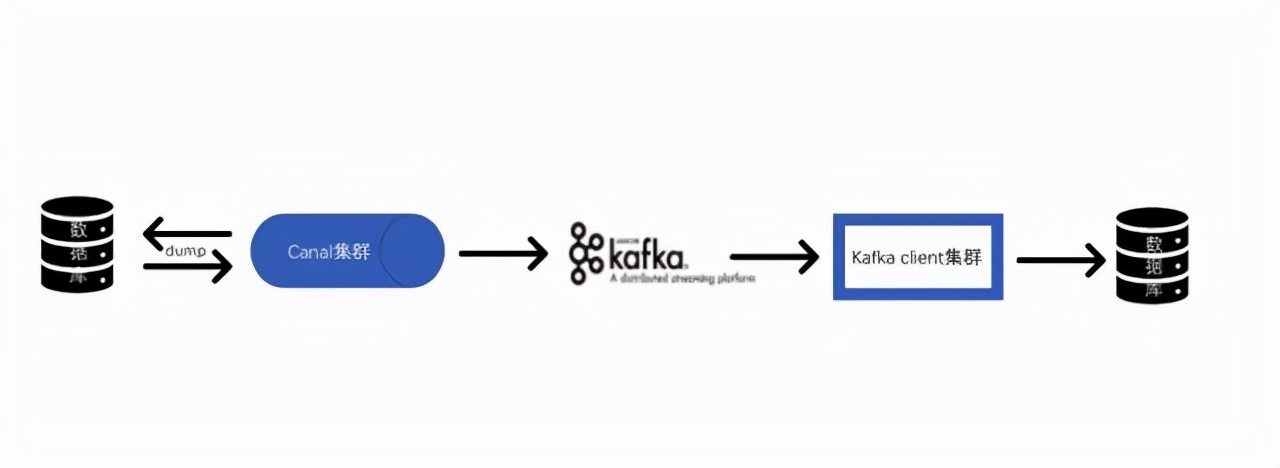
2、通过数据库的binlog进行同步。这种解决方案,与A服务是独立的,不会和A服务有代码上的耦合。可以直接TCP连接进行传输数据,优于接口调用的方式。 这是一套成熟的生产解决方案,也有不少binlog同步的中间件工具,所以我们关注的就是哪个工具能够更好的构建稳定、性能满足且易于高可用部署的方案。
经过调研,我们选择了canal[
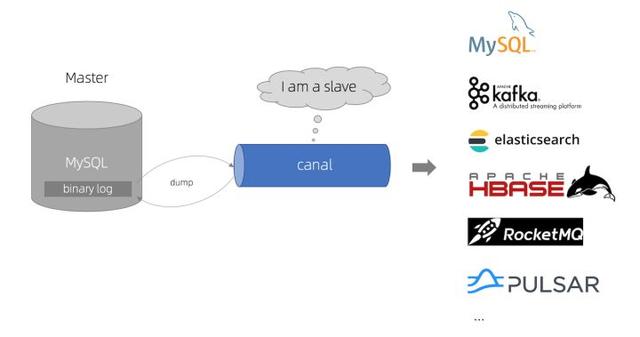
https://github.com/alibaba/canal]。canal是阿里巴巴 MySQL binlog 增量订阅&消费组件,已经有在生产上实践的例子,并且方便的支持和其他常用的中间件组件组合,比如kafka,elasticsearch等,也有了canal-go go语言的client库,满足我们在go上的需求,其他具体内容参阅canal的github主页。
原理简图
工作流程
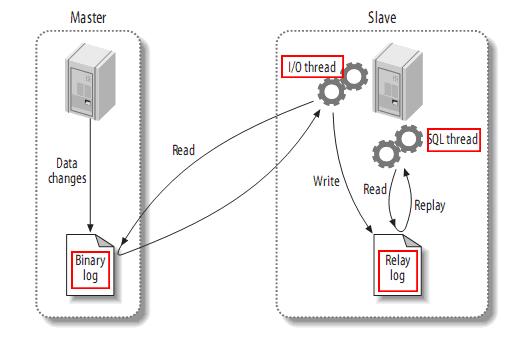
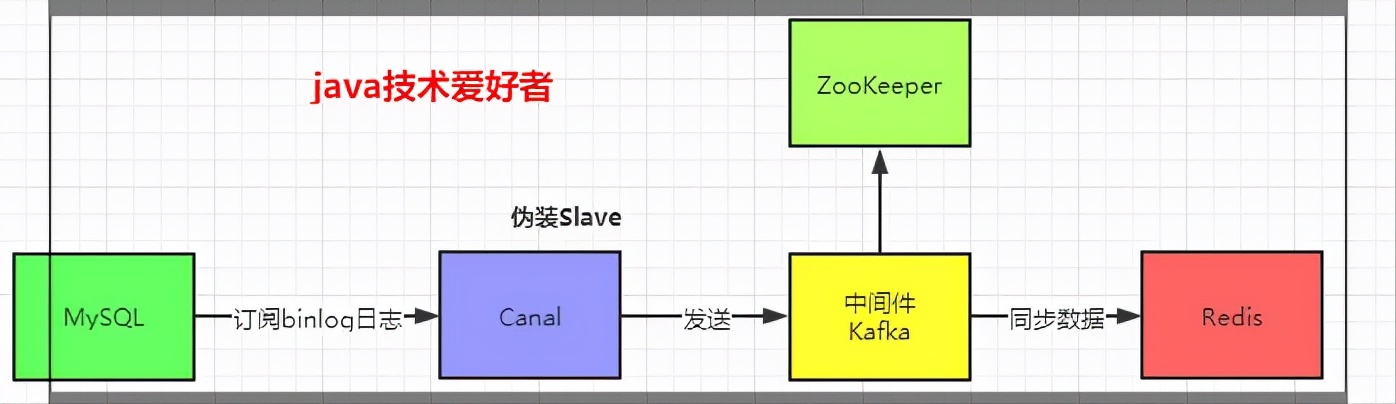
1.Canal连接到A数据库,模拟slave
2.canal-client与Canal建立连接,并订阅对应的数据库表
3.A数据库发生变更写入到binlog,Canal向数据库发送dump请求,获取binlog并解析,发送解析后的数据给canal-client
4.canal-client收到数据,将数据同步到新的数据库
安装canal
下载canal
修改配置/conf/canal.properties
# ...
# 可选项: tcp(默认), kafka, RocketMQ
canal.serverMode = kafka
# ...
# kafka/rocketmq 集群配置: 192.168.1.117:9092,192.168.1.118:9092,192.168.1.119:9092
canal.mq.servers = 127.0.0.1:9002
canal.mq.retries = 0
# flagMessage模式下可以调大该值, 但不要超过MQ消息体大小上限
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
# flatMessage模式下请将该值改大, 建议50-200
canal.mq.lingerMs = 1
canal.mq.bufferMemory = 33554432
# Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下)
canal.mq.canalBatchSize = 50
# Canal get数据的超时时间, 单位: 毫秒, 空为不限超时
canal.mq.canalGetTimeout = 100
# 是否为flat json格式对象
canal.mq.flatMessage = false
canal.mq.compressionType = none
canal.mq.acks = all
# kafka消息投递是否使用事务
canal.mq.transaction = false
# mq config
canal.mq.topic=default
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.dynamicTopic=mydatabase.mytable
canal.mq.partition=0
# hash partition config
canal.mq.partitionsNum=3
#解决消费顺序问题
canal.mq.partitionHash=mydatabase.mytable
然后配置instance,找到
/conf/example/instance.properties配置文件:
## mysql serverId , v1.0.26+ will autoGen(自动生成,不需配置)
# canal.instance.mysql.slaveId=0
# position info
canal.instance.master.address=127.0.0.1:3306
# 在Mysql执行 SHOW MASTER STATUS;查看当前数据库的binlog
canal.instance.master.journal.name=mysql-bin.000006
canal.instance.master.position=4596
# 账号密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=Canal@****
canal.instance.connectionCharset = UTF-8
#MQ队列名称
canal.mq.topic=canaltopic
#单队列模式的分区下标
canal.mq.partition=0
启动zookeeper和kafka
zookeeper-server-start.bat ../../config/zookeeper.properties
kafka-server-start.bat ../../config/server.properties
启动 canal
canal/bin/start.bat
编写读取消息的相关代码
kafka相关配置
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
@Configuration
@EnableKafka
public class KafkaConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.producer.retries}")
private String retries;
@Value("${spring.kafka.producer.batch-size}")
private Integer batchSize;
@Value("${spring.kafka.producer.buffer-memory}")
private Integer bufferMemory;
/**
* 生产者配置信息
*/
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap();
//重试,0为不启用重试机制
props.put(ProducerConfig.ACKS_CONFIG, "all");
//连接地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.RETRIES_CONFIG, 2);
//控制批处理大小,单位为字节
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
//批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//生产者可以使用的总内存字节来缓冲等待发送到服务器的记录
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
//键的序列化方式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//值的序列化方式
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
return props;
}
/** kafka无事务模式
* @return
*/
/* @Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}*/
/**
* 开启kafka事务
*
* @return
*/
@Bean
public ProducerFactory<String, String> producerFactory() {
DefaultKafkaProducerFactory factory = new DefaultKafkaProducerFactory<>(producerConfigs());
//在producerFactory中开启事务功能
factory.transactionCapable();
//TransactionIdPrefix是用来生成Transactional.id的前缀
factory.setTransactionIdPrefix("tran-");
return factory;
}
@Bean
public KafkaTransactionManager transactionManager(ProducerFactory producerFactory) {
KafkaTransactionManager manager = new KafkaTransactionManager(producerFactory);
return manager;
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
读取消息
/**
* 如何解决topic指定对应的表(一个topic对应一个表即可解决此问题)
* @param record
* @param ack
* @param topic
*/
@KafkaListener(topics = KafkaConstants.CANAL_TOPIC, groupId = KafkaConstants.DISPATCH_GROUP)
public void canalConsumer(ConsumerRecord<?, ?> record, Acknowledgment ack,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
String messageStr = (String) message.get();
CanalDto<OrderTbl> canalDto = JSONObject.parseObject(messageStr, CanalDto.class);
LOGGER.info("canalConsumer 消费了: Topic:{},Message:{}", topic, messageStr);
LOGGER.info(canalDto.toString());
boolean isDdl = canalDto.isDdl();
if(!isDdl){
String type = canalDto.getType();
List<OrderTbl> data = canalDto.getData();
if("INSERT".equals(type)){
mongodbBase.batchSave(data,OrderTbl.class);
}else if ("UPDATE".equals(type)) {
// mongodbBase.updateFirst();
}else {
//删除语句
for (OrderTbl orderTbl : data) {
mongodbBase.remove(orderTbl);
}
}
}
ack.acknowledge();
}
}
canal实体信息
public class CanalDto<T> implements Serializable {
private static final long serialVersionUID = 3652575521269639607L;
//数据
private List<T> data;
//数据库名称
private String database;
private long es;
//递增,从1开始
private int id;
//是否是DDL语句
private boolean isDdl;
//表结构的字段类型
private MysqlType mysqlType;
//UPDATE语句,旧数据
private String old;
//主键名称
private List<String> pkNames;
//sql语句
private String sql;
private SqlTypeDto sqlType;
//表名
private String table;
private long ts;
//(新增)INSERT、(更新)UPDATE、(删除)DELETE、(删除表)ERASE等等
private String type;
}





















