张工是一名程序员,做java开发的,有两年多开发经验,有次到一家软件公司应聘大数据开发岗位,面试官问了他这样一个问题。
hive表有数据,但为什么impala查询不到数据?
你能说说这是什么情况导致的,有什么办法解决方案吗?
对于这个问题,我们不妨来回顾下,什么情况下hive表有数据,但impala没有数据的情况。
1. 问题描述
用insert overwrite方式往hive写入的数据,数据写入成功了,在hive查询是可以查到数据的,但在impala刷新元数据后,查询却没有查到,刚开始以为是元数据刷新不成功,再用命令
invalidate metadata table_name
refresh table_name
刷新成功后还是没有数据,返回结果为空。
2.问题追溯
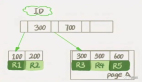
往hive表写入数据sql里使用了union ,导致hdfs目录结构多了一层,本来数据是在分区第一层的,使用了union 后,数据存储到分区底下的文件夹了。
导致impala无法访问到具体数据。impala版本2.12,查看impala版本命令(impala-shell -v)
3.解决方案
在写入数据sql 后面加上 distribute by + 表中字段 就可以了。
这是为什么呢,为什么加上distribute by +表中字段 就可以了。
我们知道,distribute 是分配、分布的意思,顾名思义,hive中(distribute by + “表中字段”)关键字就是控制map输出结果的分发,相同字段的map输出会发到一个reduce节点去处理。
总结
hive表有数据,impala表没有数据,检查是否刷新元数据,操作命令:
invalidate metadata
refresh table_name。已经成功刷新元数据了,impala依然没有数据, 检查写入hive sql 是否使用union方式,如果是,在sql 后面加上(distribute by + 表中字段 )。
拓展:
distribute by、sort by、cluster by