













以下观点可能有点反直觉:
为了让AI更好地应对真实世界应用场景,训练数据集最好别用真实世界数据。

是的,合成数据才是解锁AI真正潜力的关键所在。
顾名思义,合成数据不是从真实世界搜集所得,而是由人工生成的。
但合成数据的使用素来伴随争议,业界一直对其能否精确对应现实世界、能否让受训AI应对真实状况存有疑虑。
为此,负责模拟技术与Omniverse引擎建造的英伟达副总裁Rev Lebaredian在专访中给出了解答。

物理模拟
2021年11月,老黄在GTC大会上推出了Omniverse Replicator,一个强大的合成数据生成引擎,可以产生物理模拟的合成数据,并用于训练神经网络。
说到「模拟」,我们最常接触的其实就是游戏了,而在这其中加入一些现实中的物理学定律可以让体验更加真实。
比如,当你用炸药包去爆破一堵墙时,随着一声巨响,这堵墙也跟着轰然倒塌。但如果这堵墙纹丝不动,就会不禁让人怀疑,是不是又在偷工减料了。
当然了,在大多数情况下,游戏并不会去试图做到真正100%的还原。毕竟,模拟真实的世界太消耗算力了。
另外,游戏终究是幻想世界的模拟,目的就是为了好玩,所以遵循现实世界的物理准确性不一定是一件好事。
虽然此前有不少研究探讨过在游戏中训练AI,不过效果肯定还是大打折扣的。
而Omniverse的目标就是还原一个完全遵照现实物理学定律的模拟世界。
这里说的模拟,是用刚体物理学、软体物理学、流体动力学以及其他相关的东西模拟原子如何相互作用。
例如,光是如何与物体的表面相互作用,最终呈现出我们平时所看到的外观的。

而当我们能足够近似地模拟真实世界的时候,也就获得了相应的「超能力」。
预测未来
比如说,把我们所在的这个房间,1:1在虚拟世界中复刻出来,那么我就可以用上帝视角选择任何想去的地方,然后「瞬移」过去。
再比如,通过在火星上安装传感器摄取真实世界的信息,并在虚拟世界中重建之后,那么实际上我就可以在任何时间体验生活在火星上的感受。
而这,还不是最厉害的。
在足够精准的模拟下,只需设置一定的初始条件,就能具备预测未来的能力。
还是用这个房间举例,我正举着我的手机。此时,就可以模拟我放手的那一刻会发生什么,而不需要我真的松手。
显然,手机会随着重力掉落。
在模拟世界中,我就可以预测这部手机会以怎样的姿态掉下,落地之后屏幕会不会碎,等等。

也就是说,你可以无限次地测试在不同决策和条件下产生的结果,甚至探索所有可能出现的「平行世界」。
如果能据此做出相应的优化,也就能找到最好的未来。
还在用真实数据训练AI?
在这个AI业勃兴的新时代,一个研究生拿台笔记本电脑就能写出先进软件的场景不可能出现了。
可以说,任何先进算法的开发,都需要在海量数据的巨型系统之下训练。
所以,当下也有着「数据是新时代石油」的说法。
如此看来,方便搜集数据的大型科技企业似乎更占优势。

不过实情是,现在企业搜集的大数据,对未来将创造的尖端AI并没有真正用处。
在2017年国际计算机图形学大会(SIGGRAPH 2017)上,我就注意到了这一点。
当时我们开发了可以玩多米诺骨牌的机器人,还开发了好几个用来训练机器人的AI模型。其中最基础的一个是能侦测摊在牌桌上的多米诺牌的计算机视觉模型,能够分辨骨牌的指向与牌面花色、点数。

用谷歌总能找到足够的训练数据吧?
确实,用谷歌图像搜索是可以找到一大堆多米诺骨牌图像,但你会发现:
- 这些图像都没标注,所以要费大量人工去逐个标注每张图中的骨牌。
- 就算标注完了,你又会发现这些数据缺乏必要的多样性。
应用于真实场景的图形识别算法若要足够稳健,就必须在不同的光照条件、摄像头/传感器状态下都能成功运行。而识别多米诺骨牌的算法还要对所有材质的骨牌都能成功区分。
所以说,就算如此简单的训练要求,必要的足够数据都不存在。

真要在现实中搜集好必要数据,那就先得买几百副不同的多米诺牌、在不同打光下用不同的摄像头去拍。
因此在2017年,我们直接用一个游戏引擎编码出随机的多米诺牌生成器,所有训练数据都用它来生成,一晚上就训练出能稳健工作的图像分辨模型了。
该模型在大会现场处理用不同摄像头拍摄图像后的工作状况也很满意。
这只是个简单例子,对于自动驾驶汽车或全自动机器等远为更复杂的场景,所需训练数据的体量、准确度、多样性,全从真实世界搜集是不可能满足的。
除非生成物理上足够精确的AI训练数据,否则没有继续进步的空间。

能否覆盖训练所需的危险状况?
在Omniverse里,日夜可以随时倒换,并且可以模拟包括冰雪环境、急速过弯等情景。
行人与动物也可以安置在真实世界中绝不会安排的危险场景内。
没人会愿意真正将人或动物置于高危中,但自动驾驶汽车生产者肯定需要了解产品在各种危险边缘环境里将如何表现。

所以在虚拟世界中训练AI,各得其便。
合成数据是最好的训练策略?
当下大部分AI还是通过「监督学习」方式创造的。例如让神经网络AI分别猫狗,先得用标注好的图片教AI何为猫何为狗,然后才能应用在未标注的新图片上。
而用于训练AI的合成数据,由于内置了超级精确的数据标注,是可以作为「基准真相数据」使用的。
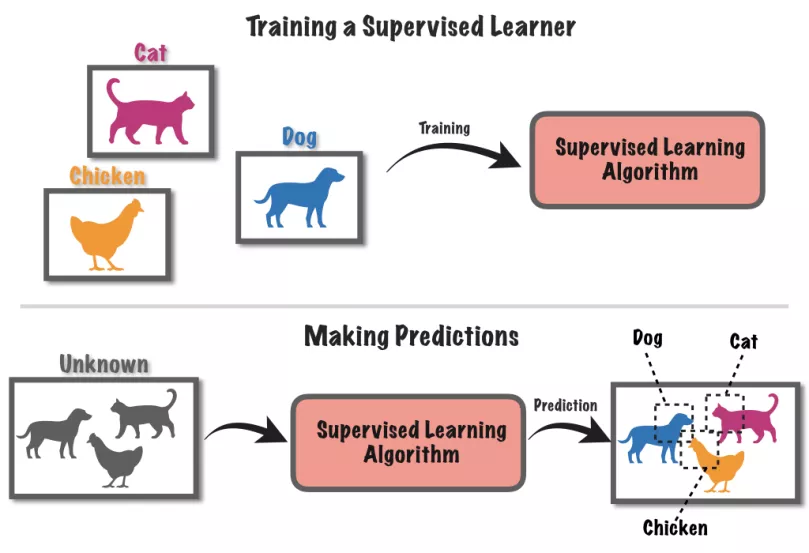
在自动驾驶汽车场景中,用户需要让智能汽车通过真实世界的传感器了解到路面各种车辆和行人相对于自身的3D位置。但其实传感器给AI的信息是除了像素啥都没有的2D图像。
如果要训练AI推断出物体3D信息,首先得在2D图像的物体周围画框,告知AI「这是基于某传感器的某镜头得到的某物相对距离」。
不过若在Omniverse合成数据的话,就可以省略此步骤直接得到有完全物理精度的物体3D位置信息了,如此可以避免人工引入数据产生的错误标注。用来训练神经网络也会得到更智能和更精确的效果

会不会出现过拟合的问题?
合成数据其实是解决过拟合难题的有效途径之一,因为生成多样性数据集远为更方便。
如果要训练一个识别面部表情的神经网络AI,但训练数据集全来自白人男性,那这个AI就在白人男性数据上过拟合了,识别多种族裔面部表情时会失败。
合成数据不会恶化这种状况,只会更容易地在数据中创造多样性。
如果要生成人像时有个能改变人脸参数的合成数据生成器,那么肤色、瞳色、发型等各种信息就能有丰富的多元区别,用来训练AI就避免了上述过拟合状况。

一个没有偏见的乌托邦?
AI诞生的环境就是合成的。它们在电脑中出世,然后只靠人类输入的任何数据受训。所以建构训练AI的完美虚拟世界是可行的。
在如此世界中完成训练的AI,会比靠真实数据训练的AI更智能,在真实世界中的运行状态也会更好

不过,合成数据的难点在于生成优质数据不容易。需要有个如Omniverse一般能物理上精确对应真实世界的模拟器。
如果合成数据生成器的生成图像质量有如卡通画,那显然难以胜任。
没人愿意把用卡通画训练出的AI搭载在服务于真实医院的机器人上,这种机器人照顾起病弱老幼的结果可太吓人了。
模拟器因此也需要尽可能地极度物理精确,但做到这点真的很不容易。














