本文摘自清华大学出版《深入浅出Python量化交易实战》一书的读书笔记,这里把作者用KNN模式做的交易策略,换成了逻辑回归模型,试试看策略的业绩会有怎样的变化。
二话不说,上梯子,导库拉数据:
import pandas as pd
import pandas_datareader.data as web
import numpy as np
from datetime import datetime- 1.
- 2.
- 3.
- 4.
数据甭多了,来个3年的:
end = datetime.date.today()
start = end - datetime.timedelta(days = 365*3)- 1.
- 2.
我大A股,最牛X的股票,要说是茅台,没人反对吧?那咱搞茅台的行情数据:
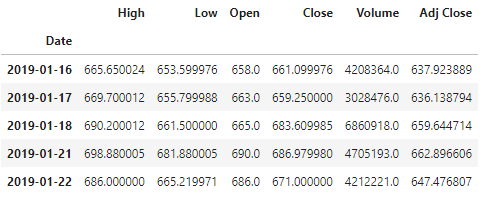
cowB = web.DataReader('600519.ss', 'yahoo', start, end)
cowB.head()- 1.
- 2.
拉下来本仙就惊了,2019年1月的时候,大茅台才600多块钱啊!不过估计当时让本仙买,本仙也不敢。那时候我大A股过百的股票也没多少吧!
然后我按照书里的方法,做下特征工程:
cowB['open-close'] = cowB['Open'] - cowB ['Close']
cowB ['high-low'] = cowB ['High'] - cowB ['Low']
cowB ['target'] = np.where(cowB['Close'].shift(-1) >
cowB['Close'],1,-1)
cowB = cowB.dropna()
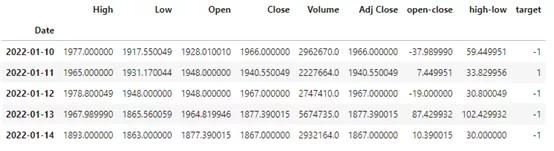
cowB.tail()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
然后就多了几列,target里面,1表示次日上涨,-1表示次日下跌:
下面要搞模型了:
x = cowB [['open-close','high-low']]
y = cowB ['target']- 1.
- 2.
拆成x和y,然后请出scikit-learn:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression- 1.
- 2.
然后把数据集拆分成训练集和测试集:
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size =
0.8)- 1.
- 2.
看看逻辑回归表现如何:
lr = LogisticRegression()
lr.fit(x_train, y_train)
print(lr.score(x_train, y_train))
print(lr.score(x_test, y_test))- 1.
- 2.
- 3.
- 4.
结果发现,还没有书里KNN的分数高:
0.5438898450946644
0.5136986301369864- 1.
- 2.
逻辑回归在训练集里面的准确率是54.39%,与书里KNN的准确率基本持平;但是测试集里只有51.37%,比书里的KNN模型低了差不多3个百分点。
折腾了一圈,结果并不满意。按说逻辑回归在分类任务上的表现,应该优于KNN才对啊。难道是本仙的数据噪音太大了?还是说其实这种预测本身意义就不大呢?