本文转载自微信公众号「阿里技术」,作者遥凌。转载本文请联系阿里技术公众号。
本文会深入介绍PolarDB MySQL在并行查询这一企业级查询加速特性上做的技术探索、形态演进和相关组件的实现原理,所涉及功能随PolarDB MySQL 8.0.2版本上线。
一 背景
1 PolarDB
云的兴起为古老而顽固的数据库市场带来了新的发展机遇,据Gartner预测,到 2022 年,所有数据库中将有 75% 部署或迁移到云平台,云原生数据库的诞生为各个数据库厂商、云服务供应商提供了弯道超车的绝好机遇,看一下AWS在Re:invent 2020发布的Babelfish,就能嗅到它在数据库市场的野心有多大。
AWS在2017年发表的关于Aurora的这篇paper[1],引领了云原生关系型数据库的发展趋势,而作为国内最早布局云计算的厂商,阿里云也在2018年推出了自己的云原生关系数据库PolarDB,和Aurora的理念一致,PolarDB深度融合了云上基础设施,目标是在为客户提供云上特有的扩展性、弹性、高可用性的同时,能够具备更低的响应延迟和更高的并发吞吐,其基本架构如下:
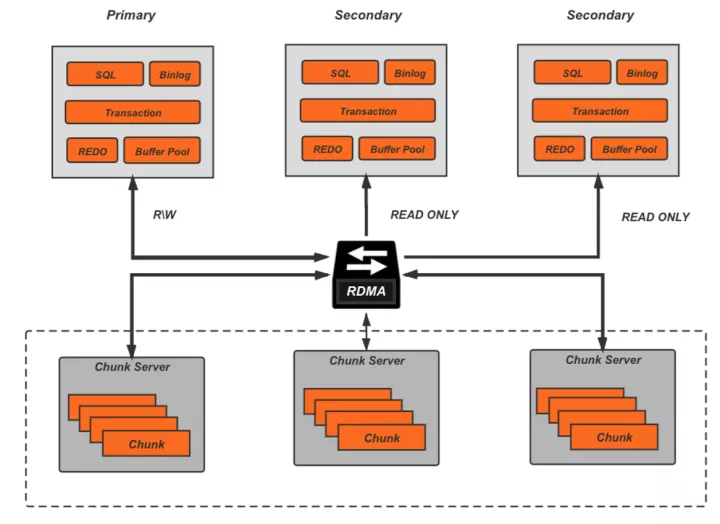
底层的分布式共享存储突破了单机存储容量的限制,而且可以随用户的数据量增长自动弹性扩容,计算层则是一写多读的典型拓扑,利用RDMA提供的高速远程访问能力来抵消计算存储分离带来的额外网络开销。
2 挑战
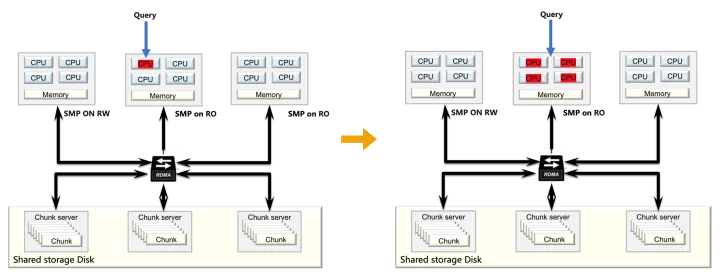
从上图可以看到,存储层将允许远大于单机的数据容量(目前是128T),甚至线上会出现一些用户,单表容量达到xx T的级别,这在基于MySQL主从复制的传统部署中是难以想象的。同时大量用户会有对业务数据的实时分析诉求,如统计、报表等,但大家对MySQL的直观印象就是:小事务处理快,并发能力强,分析能力弱,对于这些实时性分析查询,该如何应对呢?
3 方案
首先要说的是,随着互联网的发展,数据量的爆炸,一定的数据分析能力、异构数据的处理能力开始成为事务型数据库的标配,MySQL社区在8.0版本中也对自身的查询处理能力做了补强,包括对子查询的transformation、hash join、window function支持等,同时PolarDB MySQL优化器团队也做了大量工作来提升对复杂查询的处理能力,如统计信息增强、子查询更多样的transformation、query cache等。
并行查询(Parallel Query)是PolarDB MySQL在推出伊始就配备的查询加速功能,本质上它解决的就是一个最核心的问题:MySQL的查询执行是单线程的,无法充分利用现代多核大内存的硬件资源。通过多线程并行执行来降低包括IO以及CPU计算在内的处理时间,来实现响应时间的大幅下降。毕竟,对于用户来说,一条查询如果可以1分钟用10个核完成,总比10分钟用1个核完成更有意义。此外所有成熟的商业型数据库也都具备并行查询的能力。
二 并行查询介绍
1 特性
并行查询可以说是PolarDB MySQL在计算层最为重要复杂度也最高的功能组件,随着PolarDB的推出已经线上稳定运行多年,而且一直在持续演进,它具备如下几个特性:
- 完全基于MySQL codebase,原生的MySQL 100%兼容,这里包括
- 语法兼容
- 类型兼容
- 行为兼容
- 0 附加成本,随产品发布就携带的功能
- 无需额外存储资源
- 无需额外计算节点
- 0 维护成本,使用和普通查询没有任何差别,只是响应变快了
- 随集群部署,开箱即用
- 对业务无侵入
- 单一配置参数(并行度)
- 实时性分析,PolarDB原生的一部分,受惠于REDO物理复制的低延迟
- 统一底层事务型数据
- 提交即可见
- 极致性能,随着PQ的不断完善,对于分析型算子、复杂查询结构的支持能力不断提升
- 全算子并行
- 高效流水线
- 复杂SQL结构支持
- 稳定可靠,作为企业级特性,这个毋庸置疑
- 扩展MySQL测试体系
- 线上多年积累
- 完备诊断体系
上面这些听起来像是广告宣传词,但也确实是并行查询的核心竞争力。
2 演进
并行查询的功能是持续积累起来的,从最初的PQ1.0到PQ2.0,目前进入了跨节点并行的研发阶段并且很快会上线发布,这里我们先不介绍跨节点并行能力,只关注已上线的情况。
PQ1.0
最早发布的并行查询能力,其基本的思路是计算的下推,将尽可能多的计算分发到多个worker上并行完成,这样像IO这样的重操作就可以同时进行,但和一般的share-nothing分布式数据库不同,由于底层共享存储,PolarDB并行中对于数据的分片是逻辑而非物理的,每个worker都可以看到全量的表数据,关于逻辑分片后面执行器部分会介绍。
并行拆分的计划形态典型如下:
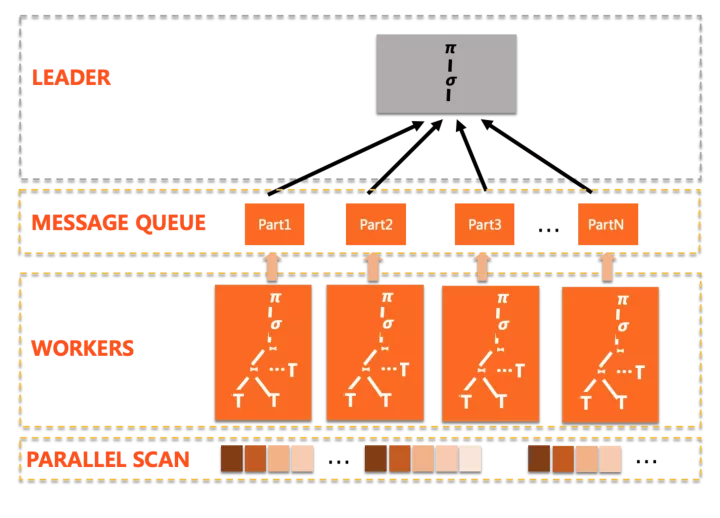
可以看到有这么几个特点:
- 执行模式是简单的scatter-gather,也就是只有一个plan slice,多个worker完成相同的功能,汇总到leader
- 尽可能的下推算子到worker上
- leader负责完成无法下推的计算
这个方案能够解决很多线上的慢查询问题,得到很好的加速效果,不过也存在着一定的局限性
- 计划形态是单一的,导致算子的并行方式单一,比如group by + aggregation,只能通过二阶段的聚集来完成:worker先做partial aggregation,leader上做final aggregation
- 一旦leader上完成聚集操作,后续如果有distinct / window function / order by等,都只能在leader上完成,形成单点瓶颈
- 如果存在数据倾斜,会使部分worker没有工作可做,导致并行扩展性差
- 此外实现上还有一些待完善的地方,例如少量算子不支持并行、一些复杂的查询嵌套结构不支持并行
总得来说,PQ1.0的并行形态和PostgreSQL社区的方案比较像,还有改进空间,毕竟所有商业数据库的并行形态都要更灵活复杂。
PQ2.0
PQ2.0弥补了上面说到的那些局限性,从执行模式上对齐了Oracle/SQL Server,实现了更加强大的多阶段并行。
计划形态典型如下:
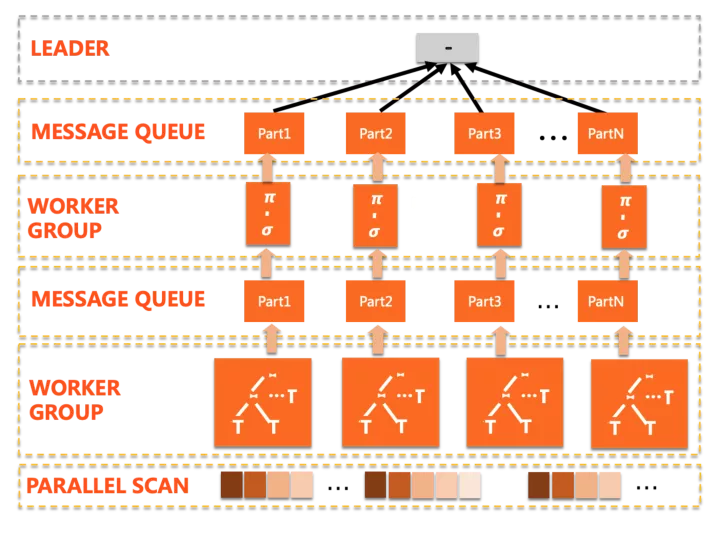
第一眼看到的变化是这里存在多个worker group,PQ2.0的执行计划是多阶段的,计划会被拆分为若干片段(plan slice),每个slice由一组worker并行完成,在slice之间通过exchange数据通道传递中间结果,并触发后续slice的流水线执行。其中一些补强的点包括:
- 全新的Cost-based并行优化器,基于统计信息和代价决定最优计划形态
- 全算子的并行支持,包括上面提到的复杂的多层嵌套结构,也可以做到完全的并行
- 引入exchange算子,也就是支持shuffle/broadcast这样的数据分发操作
- 引入一定自适应能力,即使并行优化完成了,也可以根据资源负载情况做动态调整,如回退串行或降低并行度
这些改变意味着什么呢?我们来看一个简单且实际的例子:
SELECT t1.a, sum(t2.b)
FROM
t1 JOIN t2 ON t1.a = t2.a
JOIN t3 ON t2.c = t3.c
GROUP BY t1.a
ORDER BY t1.a
LIMIT 10;
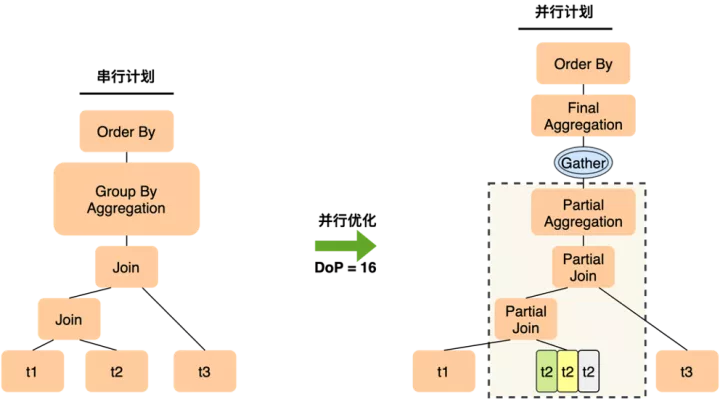
对上面的简单查询,在经过优化后,PQ1.0会生成图中的执行计划。
- 在join的表集合中,寻找一个可以做逻辑分片的表做拆分,如果3个表都不足以拆分足够多的分片,那就选最多的那个,比如这里选择了t2,它可能拆出12个分片,但仍然无法满足并行度16的要求,导致有4个worker读不到数据而idle。
- 聚集操作先在worker上做局部聚集,leader上做汇总聚集,如果各个worker上分组的聚拢不佳,导致leader仍然会收到来自下面的大量分组,leader上就会仍然有很重的聚集计算,leader算的慢了,会来不及收worker数据,从而反压worker的执行速度,导致查询整体变慢。
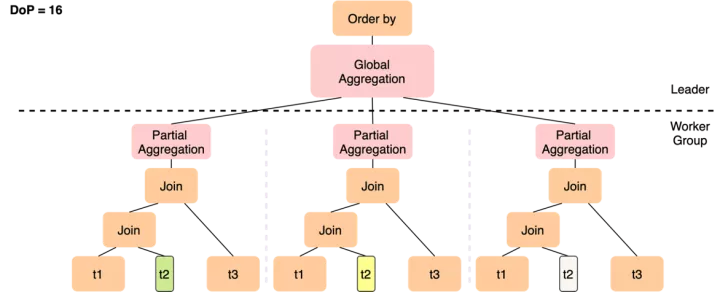
而PQ2.0的执行计划如下
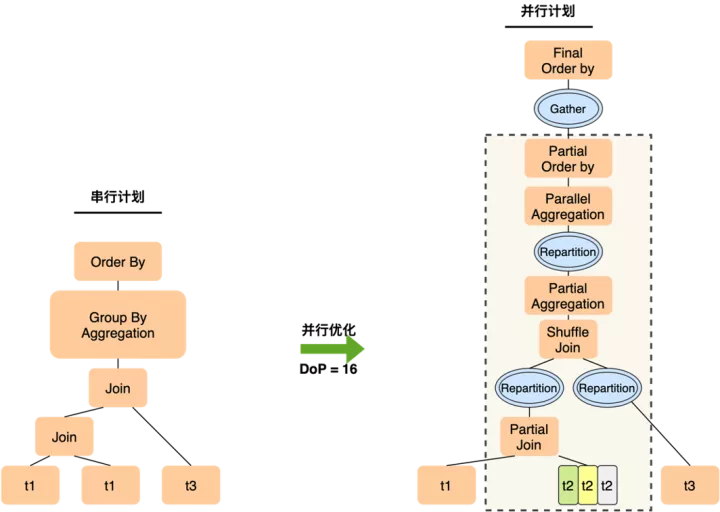
- 虽然仍然只能在t2上做数据分片,但12个worker只需要完成t1 join t2这个操作,在join完成后一般数据量会膨胀,通过Shuffle(Repartition)将更多的中间结果分发到后续的slice中,从而以更高的并行度完成与t3的join
- 各worker完成局部聚集后,如果分组仍很多,可以基于group by key做一次Shuffle来将数据打散到下一层slice,下一组worker会并行完成较重的聚集操作,以及随后的order by局部排序,最终leader只需要做一次merge sort的汇总
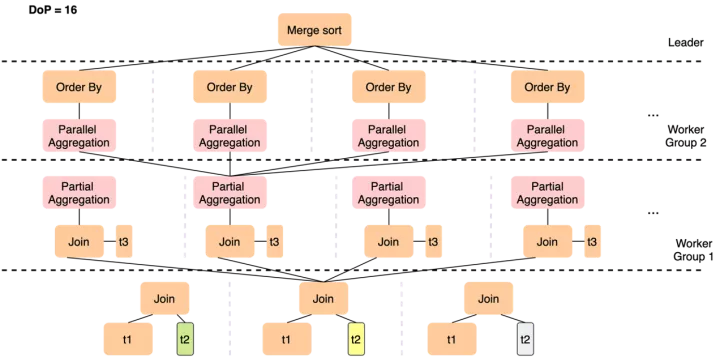
这样就解决了单点瓶颈和数据量不足导致的扩展性问题,实现线性加速。
为什么线性扩展如此重要?
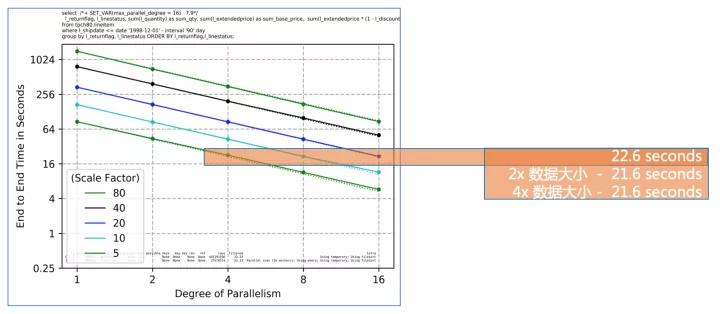
从上图可以看到,随着并行度的增长,E2E的响应时间是线性下降的,这对于客户有两个重要作用:
- 随着业务增长数据不断膨胀,通过相应提高并行度来使用匹配的计算资源,来持续得到稳定可预期的查询性能
- 始终快速的分析时间可以驱动快速的业务决策,使企业在快速变化的市场环境中保持竞争力
完美的线性加速就是,Parallel RT = Serial RT / CPU cores,当然这并不现实
3 架构
并行查询组件的整体架构如下
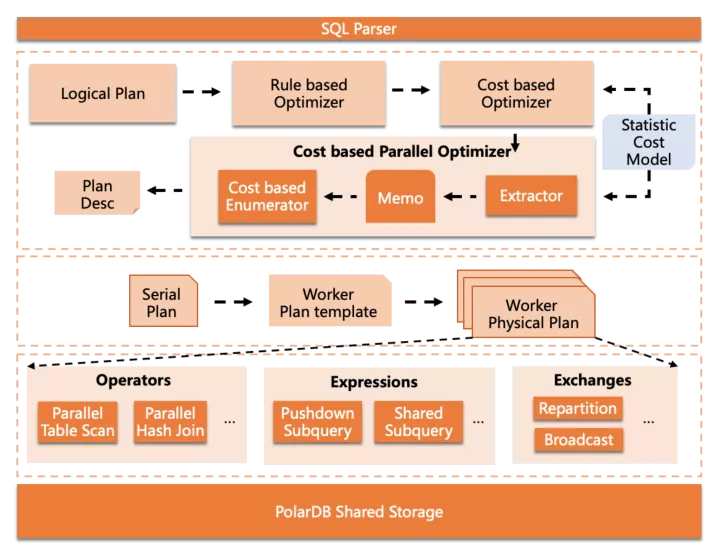
核心部分包括在3层中,从上到下依次是:
Cost-based Parallel Optimizer,嵌入在MySQL的优化器框架中,完成并行优化部分
Parallel Plan Generator,根据抽象的并行计划描述,生成可供worker执行的物理执行计划
Parallel Executor,并行执行器组件,包括一些算子内并行功能和数据分发功能等
具体每个组件的实现会在后面详细介绍
4 性能
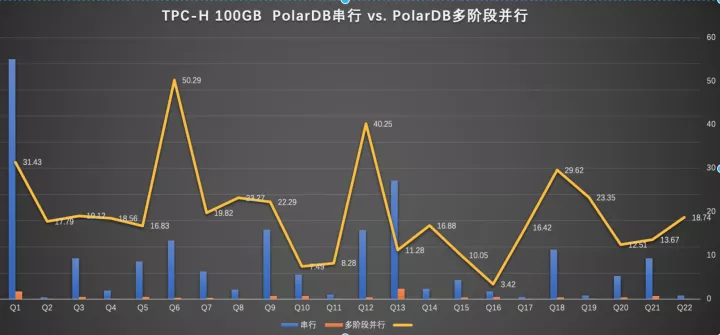
由于是个人文章这里隐去了具体执行时间(可以网上搜索下),主要看下PQ2.0的查询加速能力,这里并行度是32(可能有同学会奇怪为什么Q6/Q12的加速比超过了32,后面会具体讲到)
总的数字是:100%的SQL可以被加速,总和加速比是18.8倍。
5 使用方式
从易用性的角度,用户开启并行查询只需要设置一个参数:
set max_parallel_degree = xxx;
如果想查看并行执行计划,只需要和普通查询一样,执行EXPLAIN / EXPLAIN FORMAT=TREE 即可。
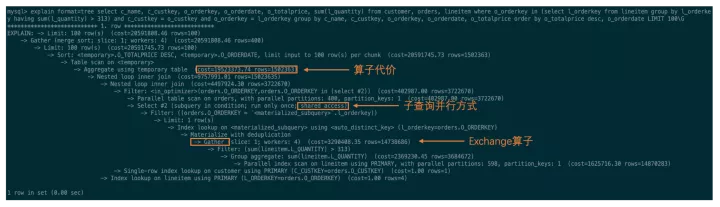
Explain 做了必要的增强来显示并行相关的information,包括代价、并行模式、分发方式等。
三 并行查询实现
上面是一些总体性的内容,没有什么技术细节,后面的章节会依次dive到每个模块中介绍下。
1 并行优化器
在PQ2.0中,由于计划形态会变得更加多样,如果拆分计划只是依靠简单规则和简单统计是很难得到最优解的,因此我们重新实现了一套完全基于cost的并行优化器。
基本的流程是在MySQL串行优化后,进一步做并行拆分,这里可能有同学疑惑为什么不像Oracle或Greenplum那样搞成一体化的,也就是在优化流程中统一考虑串/并行的执行策略。原因在于,MySQL的优化流程中,各个子步骤之间没有清晰的边界,而且深度递归的join ordering算法以及嵌入其中的semi-join优化策略选择等,都使得代码逻辑与结构更加复杂,很难在不大量侵入原生代码的前提下实现一体化优化,而一旦对社区代码破坏严重,就没法follow社区后续的版本迭代,享受社区红利。
因此采用了两步走的优化流程,这也是业界常用的手法,如Spark、CockroachDB、SQL Server PDW、Oceanbase等都采用了类似的方案。
代价模型的增强
既然是基于cost的优化,在过程中就必然要能够得到各个算子并行执行的代价信息。为此PolarDB也做了大量统计信息增强的工作:
- 统计信息自动更新
- 串行优化流程中做针对并行执行的补强,例如修正table扫描方式等,这也是上面性能数据中Q6/Q12会有超线性加速比的原因
- 全算子统计信息推导+代价计算,补充了一系列的cost formula和cardinality estimation推导机制
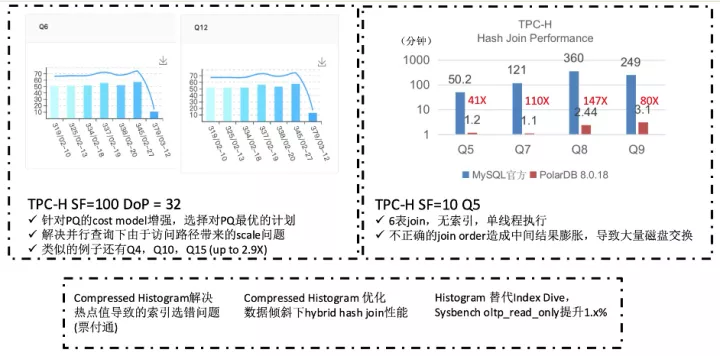
这里只能展示下统计信息增强带来的效果,收益的不止是并行查询,串行执行也会提升。
自适应执行策略
在早期版本中,串行优化和并行优化,并行优化和并行计划生成之间存在一定的耦合性,导致的问题就是在开始并行优化后会无法退化回串行,如果系统中这样的查询并发较多,会同时占用很多worker线程导致CPU打爆。新的并行优化器解决了这个问题。
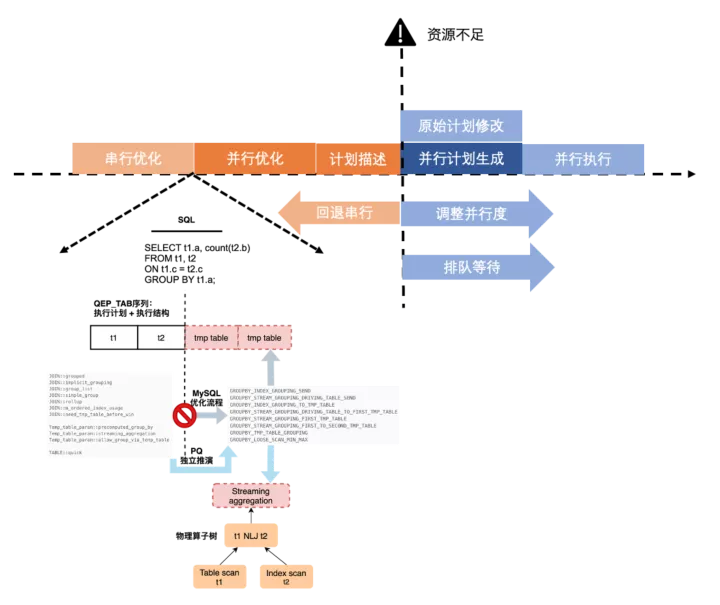
- 串行优化与并行优化解耦,并行优化会重新构建抽象算子树,并以此为输入开始enumeration
- 并行优化与并行计划生成解耦,优化的结果是计划子片段的抽象描述,作为输出进行plan generation
这样就使执行策略的灵活性成为可能,允许在资源不足情况下,要么退回串行,要么降低并行度,或者进入调度队列排队等资源。
基于代价的穷尽式枚举
这是一个比较大的话题,概略来说,并行优化是一个自底向上,基于动态规划的穷尽式枚举过程,实现思路参考了SQL Server PDW paper[2],在过程中会针对每个算子,枚举可能的并行执行方式和数据分发方式,并基于输出数据的phsical property(distribution + order)构建物理等价类,从而做局部剪枝,获取局部子问题的最优解并向上层传递,最终到root operator获取全局最优解。
下图是针对t1 NLJ t2这个算子,做枚举过程的一个简要示例:
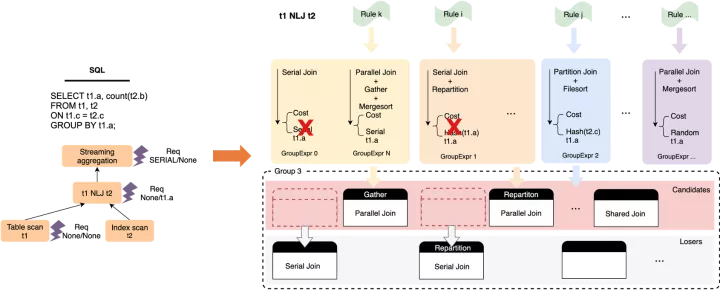
在整体枚举完成后,计划空间中会产生一系列带有数据分发Exchange Enforcer的物理算子树,基于代价选择最优树即可,然后以Enforcer作为子计划的切分点,可以构建出一系列的执行计划抽象描述,输出到plan generator中。
2 并行计划生成
从工程实现角度,并行计划生成可以说是整个组件中复杂度最高,坑最多的部分。这里采用了physical plan clone的机制来实现,也就是说,根据优化器生成的并行计划描述,从原始串行计划clone出各个计划片段的物理执行计划。
为什么要用这种方式呢?还是和MySQL本身机制相关,MySQL的优化和执行是耦合在一起的,并没有一个清晰的边界,也就是在优化过程中构建了相关的执行结构。所以没有办法根据一个独立的计划描述,直接构建出各个物理执行结构,只能从串行计划中“clone”出来,这可以说是一切复杂度的根源。
MySQL的执行结构非常复杂,expression(Item)和query block(SELECT_LEX)的交叉引用,内外层查询的关联(Item_ref)等等,都使得这项任务难度大增,但在这个不断填坑不断完善的过程中,团队也对MySQL的优化执行结构有了很深入的理解,还发现了社区不少bug...
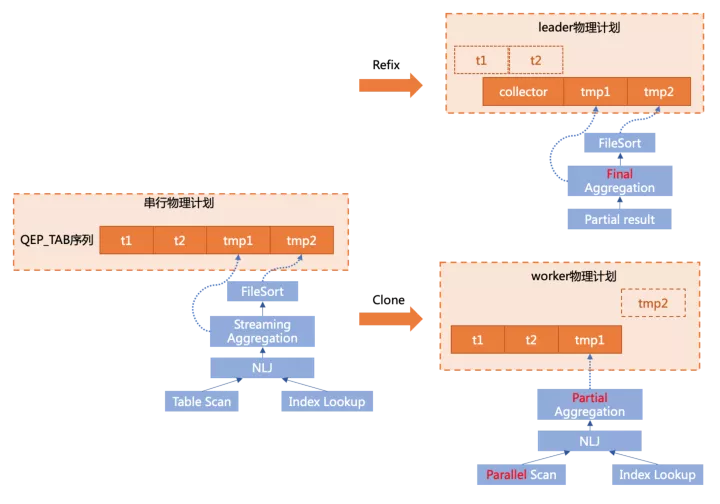
以上图中简单的查询为例
SELECT t1.a, sum(t2.b) sumb
FROM t1 join t2
ON t1.c = t2.c
GROUP BY t1.a
ORDER BY sumb;
虽然社区对执行器做了基于Iterator model的重构,但本质上,物理执行计划仍然是由QEP_TAB组成的序列,其中group by+aggr由一个tmp table1完成,order by由tmp table2完成。
在做plan generation时,有两个核心的操作:
- clone
根据串行physical plan和子slice的描述,将相对应的结构clone到各个worker线程中,如上图右下部分,将在worker上执行的t1 join t2和下推的聚集操作clone了下来。
- refix
原始的串行计划需要转换为leader计划,因此要替掉不必要的执行结构并调整一些引用关系,如上图右上部分,由于t1 join t2和部分聚集操作已经下推,leader上需要去掉不必要的结构,并替换为从一个collector table中读取worker传递上来的数据,同时需要将后续步骤中引用的t1/t2表的结构转为引用collector表的对应结构。
这里只是举了最为简单的例子,还没有涉及子查询和多阶段plan,实际的工程实现成本要高很多。
3 并行执行器
PQ实现了一系列算子内并行的机制,如对表的逻辑分区和并行扫描,parallel hash join等,来使并行执行成为可能或进一步提升性能,还有多样化的子查询处理机制等,这里选一些具有代表性的来介绍。
parallel scan
PolarDB是共享存储的,所有数据对所有节点均可见,这和sharding的分布式系统有所不同,不同worker处理哪一部分数据无法预先确定,因此采用了逻辑分区的方案:
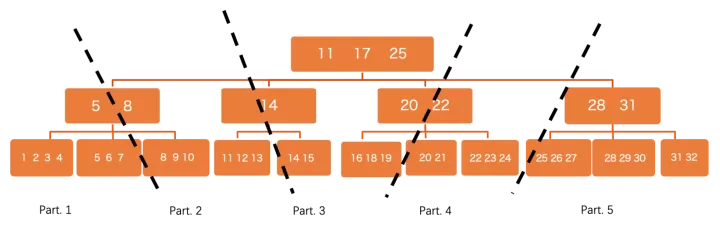
在btree这个level,会将数据切分成很多小分片,不同worker负责不同分片来触发并行执行,这里有一些优化点:
尽量做细粒度的切分,使分片数 >> worker数,然后worker之间通过round robin的方式去“抢”分片来执行,这样自然做到了能者多劳,避免由于数据分布skew导致的负载不均衡问题,这是shared storage系统的一个天然优势。
切分时可以不用dive到叶子节点,也就是以page作为最小分区单位,来加速初始分区速度。
parallel hash join
hash join是社区8.0为加速分析型查询所引入的功能,并随着版本演进对semi hash/anti hash/left hash join均做了支持,PolarDB也引入了这些patch来实现完整的hash join功能,并实现了多种并行执行策略。
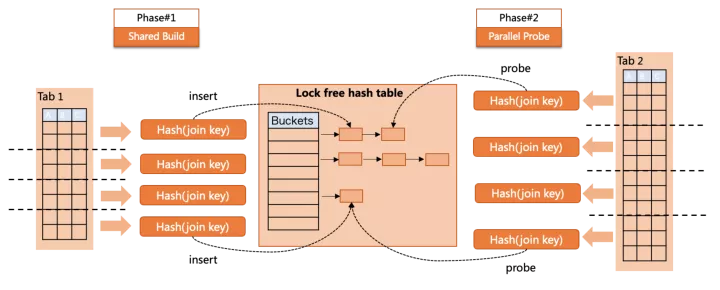
parallel hash join在build/probe两个阶段均做了并行支持
build阶段,多个worker向同一个共享的lock-free hash table中插入数据。
probe阶段,多个worker并行到hash table做搜索。
两个阶段没有重叠,这样就实现了全阶段的并行,但parallel hash join也有自身的问题,例如共享hash table过大导致spill to disk问题,并行插入虽然无锁,但仍有“同步”原语带来的cache invalidation。
partition hash join
partition hash join则可以避免以上问题,但代价则是引入数据shuffle的开销:
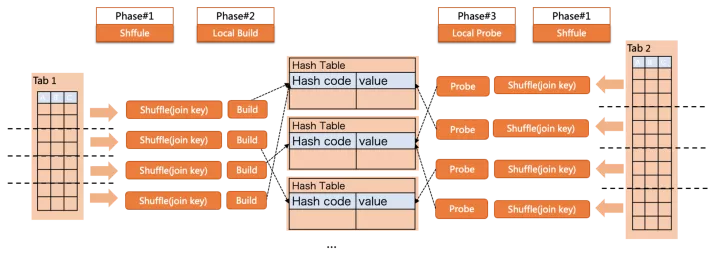
如图所示,查询的执行过程分为了3个阶段
- build/probe两侧都根据join key做shuffle,将数据分发到目标partition;
- 在每个partition内,build侧各自构建小hash table;
- 在每个partition内,probe侧各自查找对应的hash table;
这样就在各个partition内,完成了co-located join,每个hash table都更小来避免落盘,此外也没有了build中的并发问题。
以上两个方案哪个更优?由并行优化器基于Cost决定。
子查询并行 - pushdown exec
这里子查询是表达式中的一部分,可以存在于select list / where / having等子句中。对于相关子查询,唯一的并行方式是随外层依赖的数据(表)下推到worker中,在每个worker内完整执行,但由于外层并行了,每个worker中子查询执行次数还是可以等比例减少。
例如如下查询:
SELECT c1 FROM t1
WHERE EXISTS (
SELECT c1 FROM t2 WHERE t2.a = t1.a <= EXISTS subquery
)
ORDER BY c1
LIMIT 10;
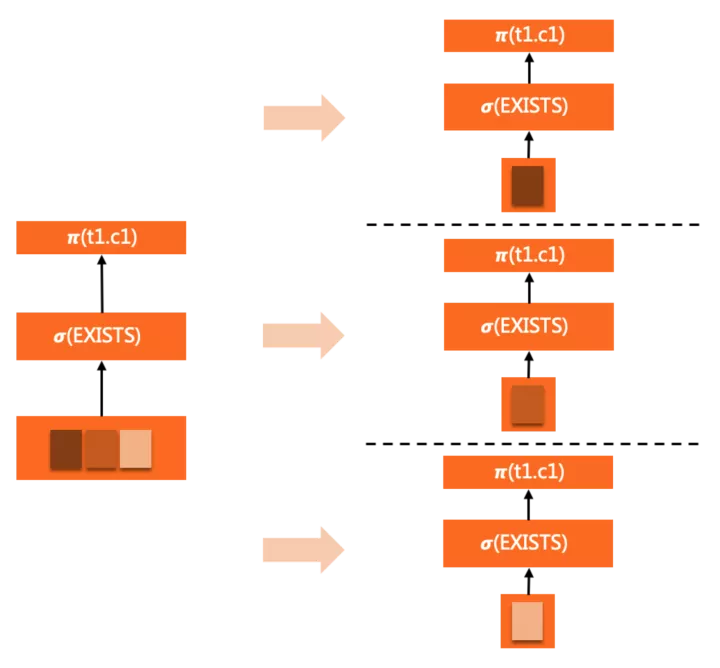
EXISTS子查询完整的clone到各个worker中,随着WHERE条件的evaluation反复触发执行。
子查询并行 - pushdown shared
这种并行方式的子查询可以是表达式的一部分,也可以是派生表(derived table)。
概略的来说,这种并行方式适用于非相关子查询,因此可以提前并行物化掉,形成一个临时结果表,后续外层在并行中,各worker引用该子查询时可以直接从表中并行读取结果数据。
例如如下查询
SELECT c1 FROM t1
WHERE t1.c2 IN (
SELECT c2 FROM t2 WHERE t2.c1 < 15 <= IN subquery
)
ORDER BY c1
LIMIT 10;
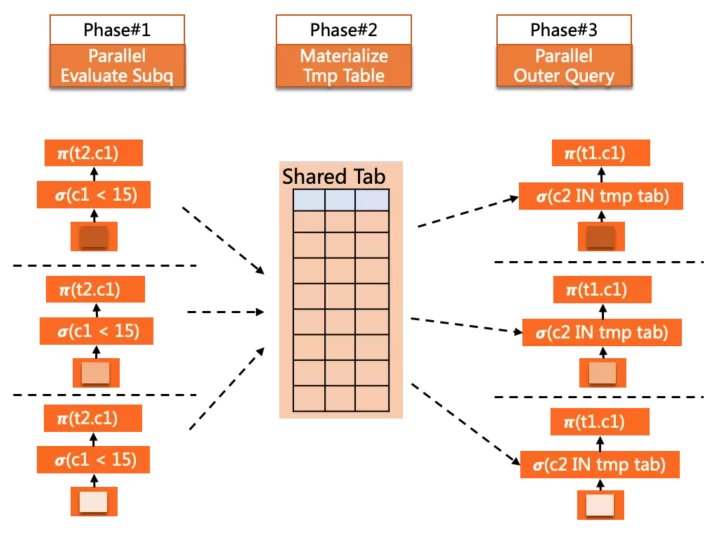
另外线上用户的报表类查询中,一种非常常见的Query模式就是derived table的多层嵌套,对于这类SQL,pushdown shared策略可以很好的提升并行执行的性能,例如如下示例:

上图中每个颜色的方块,代表了一层query block,这里就构成了多层derived table的嵌套逻辑,有些层中通过UNION ALL做了汇总,有些层则是多个表(包括derived table)的join,对于这样的查询,MySQL会对每个derived table做必要的物化,在外层形成一个临时结果表参与后续计算,而PQ2.0对这种常见的查询模式做了更普遍的支持,现在每一层查询的执行都是并行完成的,力争达到线性的加速效果。
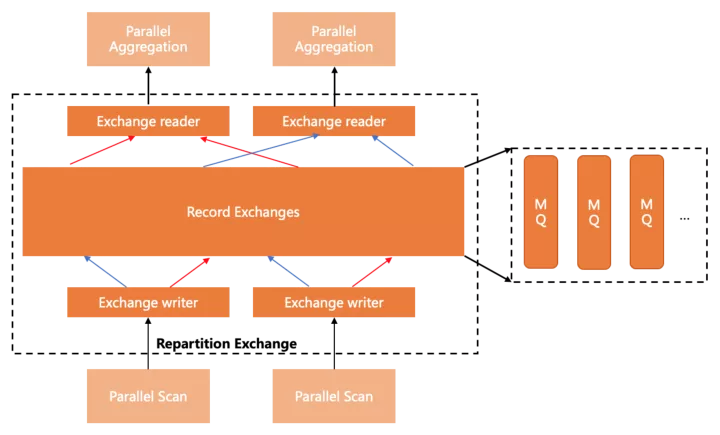
Exchanges
要生成高效灵活的执行计划,数据分发组件是必不可少的,目前PolarDB支持了Shuffle/Broadcast/Gather三种分发方式,实现上利用lock-free shared ring buffer,做到流水线模式的高效数据传输。
下图展示了Shuffle(Repartition)的基本形态
到这里,并行查询的线上版本功能及实现已经大体介绍完了。
作为一款成熟的企业级功能特性,团队还实现了一整套完善的辅助工具集,来配合提升产品的易用性,实现功能的可监控、可干预、可反馈,但这里篇幅已经很大了,就先不介绍了。
四 未来规划
这里说是未来规划并不确切因为团队已经在跨节点并行上做了大量的工作并进入了开发周期的尾端,跨节点的并行会把针对海量数据的复杂查询能力提升到另一个水平:
- 打通节点间计算资源,实现更高的计算并行度
- 突破单节点在IO / CPU上的瓶颈,充分利用分布式存储的高吞吐能力
- 结合全局节点管理与资源视图,平衡调度全局计算资源,实现负载均衡的同时保证查询性能
- 结合全局一致性视图,保证对事务性数据的正确读取
[1]https://www.allthingsdistributed.com/files/p1041-verbitski.pdf
[2]https://www.scinapse.io/papers/2160963784#fullText