一、ADAS/AD系统方案
(一) L0-L2级别的ADAS方案正如前所述,早期大多数L0-L2级别的ADAS系统都是基于分布式控制器架构,整个ADAS系统由4-5个ADAS子系统组成,每个子系统通常是个一体机整体方案(可以被看作是一个smart sensor),子系统独占所配置的传感器,通常相互之间是独立的。以智能前视摄像头模块(Intelligent Front Camera Module,FCM)为例,整个子系统ECU主板上包含2颗芯片:一颗是安全核(Safety Core);另一个颗是性能核(Performance Core)。安全核一般由英飞凌TC297/397之类的MCU充当,承载控制任务,因此需要较高的功能安全等级需求;性能核通常是具有更高性能算力的多核异构MPU,会承载大量的计算任务。下面是一个对L0-L2级别方案的总结:
- L0级别方案:实现各种ADAS报警功能,比如:FCW、LDW、BSW、LCA等。分布式架构,通常由FCM、FCR、SRRs、AVS、APA等几大硬件模块组成。
- L1级别方案:完成各种ADAS单纵向核单横向控制功能,比如:ACC、AEB、LKA等。也是分布式架构,硬件模块组成与L0级别方案大致相同。
- L2级别方案:完成ADAS纵向+横向组合控制功能。比如:基于FCM+FCR融合系统,融合前向视觉感知和前雷达目标感知信息,实现TJA/ICA等功能;或者基于AVS+APA的融合系统,实现自动泊车功能。
(二)L2+以上级别的ADAS方案分布式架构的ADAS系统存在两个致命缺点:1)各个子系统互相独立,无法做多传感器之间的深度融合。2)各子系统独占所配置的传感器,因此无法实现跨多个不同子系统传感器的复杂功能。当整车EE架构演进到域集中式EEA之后,ADAS域控制器中配置了集成度更高、算力性能更高的计算处理器平台,进而可以支撑更复杂的传感器数据融合算法,以实现更高级级别的ADAS功能,比如:HWP、AVP等。集中式ADAS域控制器方案从最早的四芯片方案,过渡到三芯片方案,再到当前业界主流的两芯片方案,如下图3-5所示:

ADAS域控制器方案演进历史下图是一个典型的车载ADAS域功能结构示意图,无论硬件方案如何变化,各方案所需实现的功能结构都是类似的。
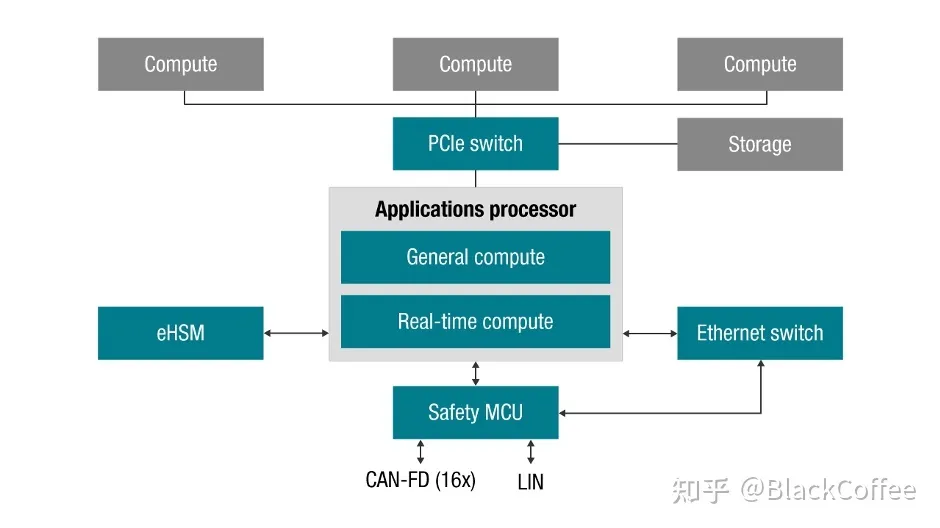 典型的车载ADAS域功能结构示意图
典型的车载ADAS域功能结构示意图
二、 Mobileye EyeQ系列芯片方案
Mobileye成立于1999年,是以色列提供基于视觉算法分析和数据处理来提供ADAS/AD解决方案的全球领先者。其EyeQ系列芯片产品截止2021年底已经总计出货接近一亿片。尽管在L3/L4领域被英伟达和高通压制,但是在主流的L2级别ADAS市场,仍然是霸主,其市场占有率高达75%。2021年出货量高达2810万片。Mobileye一直采用“传感器+芯片+算法”绑定的软硬件一体化的ADAS解决方案模式。这种“黑盒”商业模式的优点是开发周期短,客户可以快速出产品,比较受转型较晚或者软件/算法能力较弱的传统主机厂或者Tier 1厂商欢迎。但是缺点是导致客户开发灵活度下降,不能满足客户差异化定制产品的需求。越来越多的主机厂希望采用更开放的平台,把“芯片和算法剥离开,采用可编程的芯片,从而通过OTA来实现持续的算法迭代升级”。这也是软件定义汽车的思路。下面是其EyeQ4/5/6三代产品的基本情况:
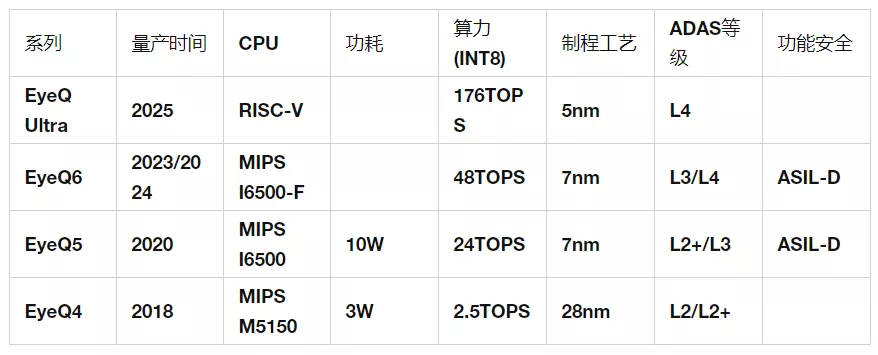
(一)EyeQ4芯片平台EyeQ4新品配置了4个MIPS CPU核、6个矢量微码处理器(VMP)以及两个可编程宏阵列(PMA)。每个CPU核拥有4个硬件线程。总计2.5TOPS的算力,可以实现以每秒36帧的处理速度处理8路摄像头的视频信息。总体性能相比EyeQ3提升8倍之多,此外,EyeQ4还引入“路网采集管理(REM)”系统,它利用纵包数据的方法将路标、车道线等进行压缩,最终聚合成路书,从而为自动驾驶汽车提供更精确的定位。下图是EyeQ4新品的功能模块图。
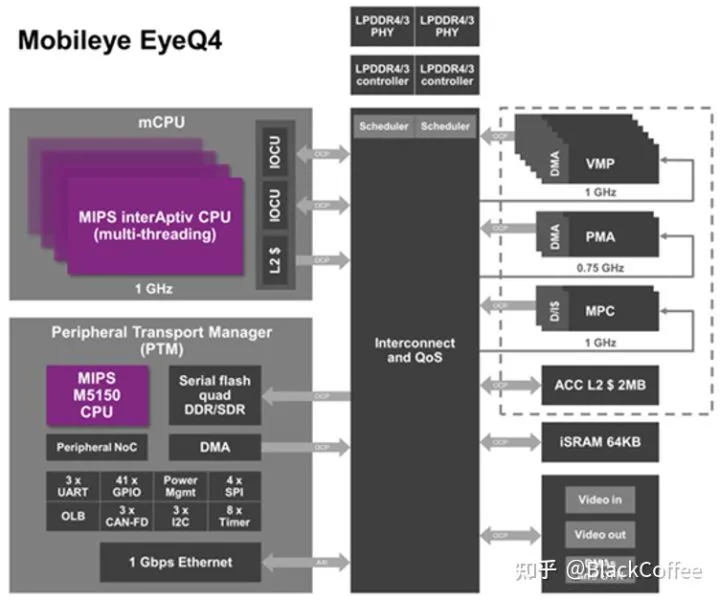
EyeQ4芯片功能模块图(二)EyeQ5芯片平台EyeQ5主要有4个模块:CPU核、计算机视觉处理器(CVP)、深度学习加速器(DLA)和多线程加速器(Multithreaded Accelerator,MA)。其中,CPU和CVP是大头。EyeQ5选择了Imagination的MIPS I6500作为CPU内核,每个MIPS I6500内核都拥有2个硬件线程。总共配置8个CPU内核,可提供高达52000 DMIPS算力。EyeQ5总共配置18个CVP内核。
CVP是Mobileye针对很多传统计算机视觉算法设计的新一代视觉处理器。Mobileye从公司成立时起就以自己的CV算法而闻名,也因为用专用的ASIC来运行这些CV算法而达到极低的功耗而闻名。EyeQ5采用了7nm的制程工艺,总计可提供高达24TOPS的算力,并且只有10W左右的TDP功耗,因此有着极为出色的能效比。EyeQ5最多支持20个外部传感器,包括:摄像头、雷达或者激光雷达等。出色的计算性能使得我们在EyeQ5上进行深度的传感器融合,以实现更复杂的L2+/L3级别ADAS功能。下图是EyeQ5的芯片功能模块图:
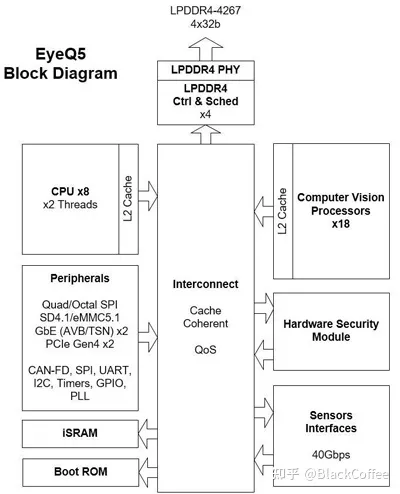
EyeQ5 Block Diagram(三)EyeQ6芯片平台EyeQ6H与Mobileye之前的芯片最大的不同就是加入了两个小算力规模的GPU,一个是ARM Mali GPU,算力为64GFLOPS,预计用于ADAS的AR图像叠加输出。另一个是Imagination的BXS 1024 MC-2,算力为1000GFLOPS,预计用于OpenCL加速引擎。CPU仍然是EyeQ5的MIPS I6500-F架构,不同之处在每个CPU内核的线程数从2个增加到4个,总共是8核32线程。EyeQ6H可以用比EyeQ5多25%的功耗,提供比3倍于EyeQ5的算力性能。

EyeQ6 ADAS域控处理器Mobileye芯片平台最大优点是产品成本低,开发周期很短,开发费用极低,绝大部分功能都经过验证,没有风险。而缺点是系统非常封闭,难以搞特色功能,迭代困难,出了问题,较难改进或提升。对于传统车厂而言,Mobileye基本是唯一选择,对于总想与众不同的新兴造车厂家来说就有点无法适应。然而新兴造车企业毕竟还是极少数。Mobileye霸主地位至少五年内稳如泰山。
三、 TI Jacinto 7芯片平台
2020年初的CES大会上,TI发布了其最新的Jacinto 7架构的系列车载芯片。上一代的Jacinto 6架构主要聚焦在车载Infotainment(信息娱乐)的功能,例如更炫的UI(用户界面)、更多的显示屏等。随着新一代Jacinto 7架构芯片的发布,可以看出TI已经基本放弃智能座舱和IVI市场,而重点转向ADAS域控和汽车网关域方向。Jacinto 7系列芯片包含两颗车规级芯片:(1)用于高级辅助驾驶(ADAS)系统的TDA4VM芯片;(2)用于网关系统的DRA829V处理器。这两款处理器都包含了用于加速数据密集型计算任务的专用加速器(如计算机视觉和深度学习等),而且它们也都集成了支持ISO26262功能安全的MCU核,使得我们可以用一颗芯片来同时承载ASIL-D高级别功能安全的控制任务和传感器数据处理这样的计算密集型任务。
(一) TDA4VM ADAS芯片
基于Jacinto™ 7架构的TDA4VM处理器专为L2+或以上级别的集中式ADAS域控制器平台而设计的,它集成了各种加速器、深度学习处理器和片上内存,具有强大的数据分析和处理能力,是一个全功能、可编程的高集成度ADAS域控处理器平台。这种多级处理能力使得TDA4VM能够胜任ADAS域的各种中心处理单元角色。比如:TDA4VM处理器支持接入8MP(800万像素)高分辨率的摄像头,更强大的前视摄像头可以帮助车辆看得更远,因此可以开发出更强的辅助驾驶增强功能。用户也可以用TDV4VM处理器同时操作4到6个300万像素的摄像头,并还可以将毫米波雷达、超声波雷达和激光雷达等其它多种传感器数据处理在一个芯片平台上进行深度融合(后融合)。还可以将TDA4VM处理器用作自动泊车系统中的中心处理器,实现360度的环视感知能力,从而可以开发出用户体验更好的360度全屏泊车系统。以下框图的左边是当前典型的ADAS 系统框图,主要数据处理部分是由GPU或NPU完成,在这颗应用处理器外,会集成MCU、外部ISP、以太网交换机和PCIe交换机等。右边是使用TDA4VM后的ADAS系统框图。TDA4把原来外部需要的上述模块集成到芯片中,其中包含通用处理部分的CPU、实时MCU、功能安全MCU、C7x DSP、MMA深度学习加速器、VPAC DMPAC视觉加速器、内部的ISP和以太网交换机,以及PCIe交换机等等。显然使用TDA4VM可以大大简化ADAS系统的硬件复杂度。
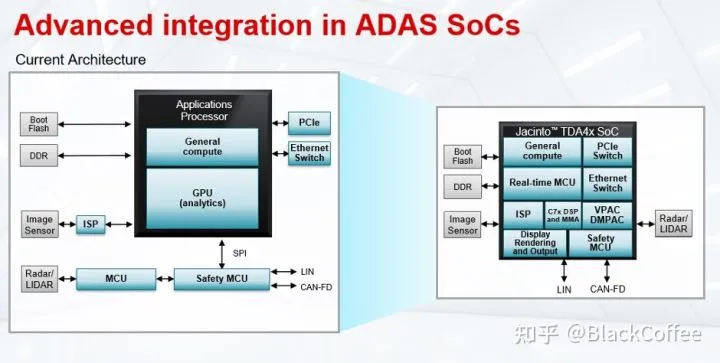
TDA4x域控处理器简化ADAS系统架构下图是TDA4VM处理器的Block Diagram。其芯片中关键特性如下:1)具有两个64位 Arm® Cortex®-A72微处理器子系统,工作频率高达1.8GHz,22K DMIPS;
- 每个Cortex®-A72核集成了32KB L1 D-Cache和48KB L1 I-Cache。
- 每个双核Cortex-A72 Cluster共享一个1MB大小的L2 Cache。
2)有六个Arm® Cortex®-R5F MCU,工作频率高达1.0GHz,12 K DMIPS;
- 每个核存储器为64K L2 RAM
- 隔离安全岛中的MCU子系统有两个Arm® Cortex®-R5F MCU
- 通用计算部分有四个Arm® Cortex®-R5F MCU
3)两个C66x浮点DSP,工作频率高达1.35 GHz, 40 GFLOPS, 160 GOPS;4)C7x浮点,矢量DSP,高达1.0 GHz, 80 GFLOPS, 256 GOPS;5)深度学习矩阵乘法加速器(MMA),1.0GHz高达8 TOPS (INT8);6)视觉处理加速器(VPAC)和图像信号处理器(ISP)和多个视角辅助加速器;7)深度和运动处理加速器(DMPAC)
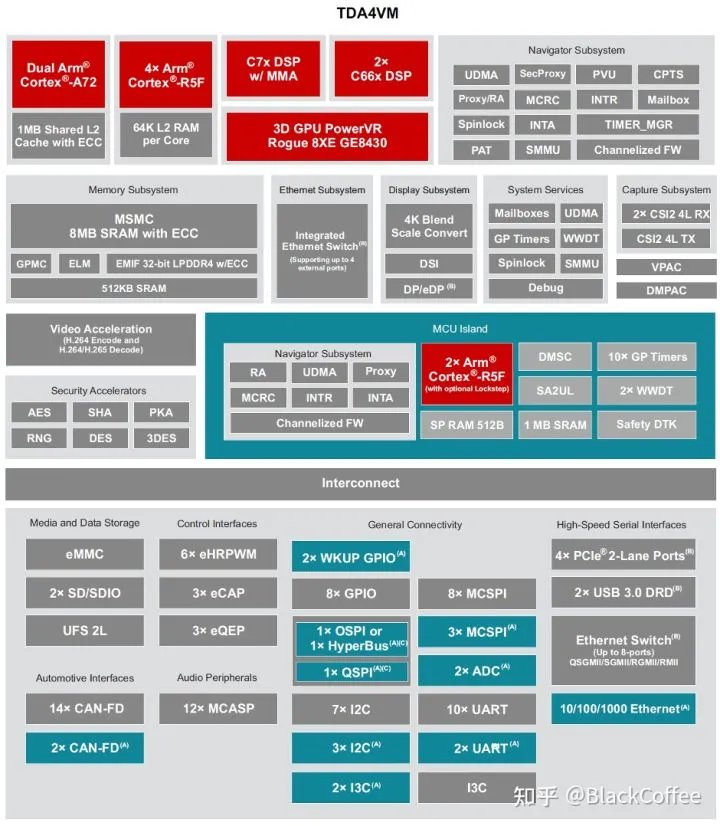
TI TDA4x处理器功能模块图“C7x”是TI的下一代DSP,它将TI 行业领先的DSP 和EVE 内核整合到单个性能更高的内核中并增加了浮点矢量计算功能,从而实现了对旧代码的向后兼容性,同时简化了软件编程。新型“MMA”深度学习加速器可在业界最低功率包络内实现高达8TOPS 的性能。专用的ADAS/AV 硬件加速器可提供视觉预处理以及距离和运动处理。TDA4VM处理器还能很好地满足整个系统的功耗要求,当胜任这些ADAS域控所需的高性能计算,TDA4VM处理器仅需5到20W的功耗,因此无需主动冷却。比如:Momenta曾在2020年CES有一个演示,在现场有客户触摸TDA4 的芯片外壳,发现芯片外壳上没有做任何的散热,可见功耗是非常低的。TDA4VM处理器內的功能安全设计包括两部分:1)隔离的功能安全岛中集成了两个支持双核锁步模式的Cortex-R5F核,可以实现ASIL-D级别的功能安全;2)其余主处理器部分可以达到ASIL-B功能安全。
- 功能安全岛中的两个ARM Cortex-R5F核带有浮点协处理器,支持双核锁步运行模式。
- 512字节的Scratchpad RAM内存
- 高达1MB、带有ECC支持的片上SRAM
- 安全岛內专用的电压与时钟域(独立于主处理器)
- 安全岛內专用的内存和接口设计(独立于主处理器)
- 隔离的功能安全岛中集成了两个支持双核锁步模式的Cortex-R5F核,可以实现ASIL-D级别的功能安全;
- 主处理器的其余部分可以达到ASIL-B功能安全:
- 片上内存和互联都带有ECC保护
- 内置自检机制(Built-in Self-Test,BIST)
(二)DRA829V网关芯片
传统汽车过去一直在使用低速网络(比如:CAN/LIN等)进行通信,因此如果要对整车所有电控单元进行软件升级将会是非常缓慢的(如下图的左边部分)。当现代汽车演进到域集中式EEA之后,比如常见的三域EE架构(ADAS域、座舱域、整车控制域),域与域之间的通信就需要非常高速的通信总线(如下图右边),因此就需要中央网关跨域通信的网络协议转换和包转发功能。DRA829V处理器就是用于这个场景。

DRA829V作为汽车域和域之间的通信网关
DRA829V 处理器是业界第一款集成了片上 PCIe 交换机的处理器,同时,它还集成了支持 8 端口千兆支持 TSN 的以太网交换机,进而能够实现更快的高性能计算和整车通信。下图的左边是TI理解的整个车身运算平台的框架,在这个框架应用处理器外需要接上外部的PCIe交换机、以太网交换机,也需要外部的信息安全模块(eHSM),外部的MCU。而下图的右边用DRA829V处理器把上述外部需要集成的IP模块全部集成进来,因此大大降低了硬件复杂度,提高了可靠性。TI汽车网关处理器最核心的一点是高性能处理器,同时需要功耗非常低。
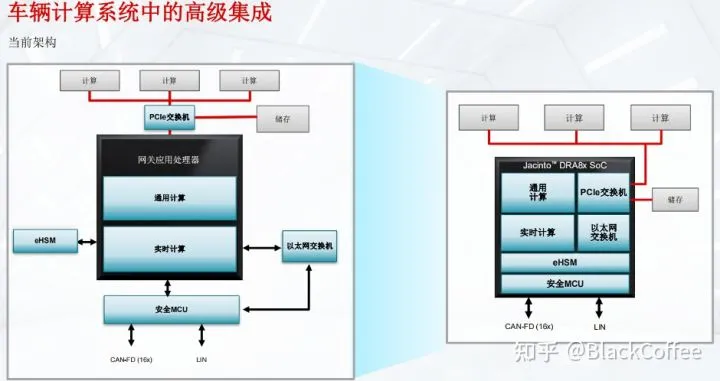
TI DRV8x系列网关芯片简化网关系统架构DRA829V SoC 通过提供计算资源、在车辆计算平台中高效移动数据以及在整个车辆网络中进行通信,解决了新型车辆计算架构带来的难题,可以看到DRA829V 主要是处理数据交换和安全的问题。与NXP S32G2/S32G3相比,虽然这两款芯片都是针对汽车中央网关场景,但是设计特点是不同。
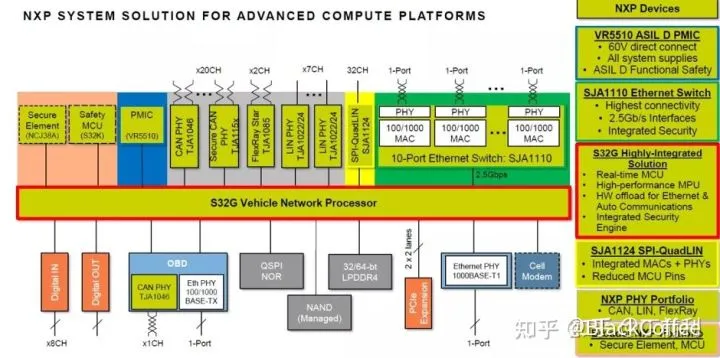
NXP S32G中央网关处理器NXP的S32G是作为一个成熟的网络处理器设计的,最大的特色是通过网络卸载引擎来加速3层的协议转换和包转发。它完全是作为汽车域集中式EE架构中的中央网关场景量身设计的,可以有效处理各控制器的OTA升级、数据网关的交互,安全信息的传输等任务。而DRA829V 更多是车内高速信号的集联和转发,这些能力使DRA829V更适合充当域内的高速信号的集联和转发节点(注意:这不同于NXP S32G的中央网关角色,可以认为是域主控处理器所需要的网关功能)。当然,DRA829V也可以作为中央网关的角色,但是因为缺乏类似于NXP S32G网关中包转发引擎,因此这并不是DRA829V的主打功能。
四、 NVIDIA Xavier/Orin的方案
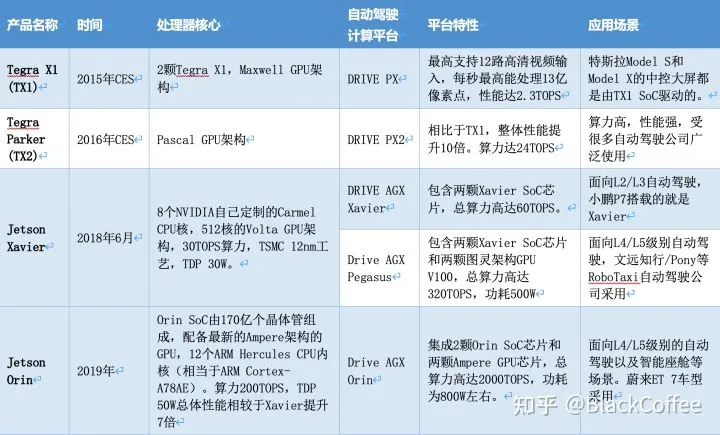
英伟达是全球最大的智能计算平台公司。公司早期专注于PC图形计算,后来利用其适合大规模并行计算的GPU架构,逐步将业务重点拓展到云端的AI加速、HPC高性能计算、AR/VR等领域。除了优秀的硬件平台架构和性能之外,NVIDIA在软件和生态上也具有巨大的优势。基于NVIDIA GPU架构的CUDA软件开发平台,是业界事实标准的异构计算框架。NVIDIA在CUDA计算框架的基础上,开发出了DNN加速库、编译器、开发调试工具以及TensorRT推理引擎等。NVIDIA 2015年正式发布其面向移动端/机器人/自动驾驶等领域的智能处理器Tegra X1,它内置集成了当时NVIDIA最先进的Maxwell架构的GPU核。这颗SoC处理器的发布也在全球开启了嵌入式领域的AI计算时代。
借助于它在云端积累的CUDA+TensorRT生态优势,NVIDIA在自动驾驶领域提供“芯片+完全自动驾驶软件栈”端到端解决方案,包括:Drive AV软件平台、Drive IX软件平台、Drive Sim等完整的软件生态。
(一) Xavier自动驾驶计算平台
NVIDIA在2018年CES上推出了Xavier平台,作为Driver PX2 的进化版本。NVIDIA称Xavier 是“世界上最强大的SoC(片上系统)”,Xavier可处理来自车辆雷达、摄像头、激光雷达和超声波等传感器的自主驾驶感知数据,能效比市场上同类产品更高,体积更小。“NVIDIA® Jetson AGX Xavier™ 为边缘设备的计算密度、能效和 AI 推理能力树立了新的标杆。”2020年4月上市的小鹏汽车 P7,成为首款搭载 NVIDIA DRIVE AGX Xavier 自动驾驶平台的量产车型,小鹏 P7 配备了13 个摄像头、5 个毫米波雷达、12 个超声波雷达,集成开放式的 NVIDIA DRIVE OS 操作系统。Xavier SoC基于台积电12nm FinFET工艺,集成90亿颗晶体管,芯片面积350平方毫米,CPU采用NVIDIA自研8核ARM64架构(代号Carmel), 集成了Volta架构的GPU(512个CUDA核心),支持FP32/FP16/INT8,20W功耗下单精度浮点性能1.3TFLOPS,Tensor核心性能20TOPs,解锁到30W后可达30TOPs。Xavier是一颗高度异构的SoC处理器,集成多达八种不同的处理器核心或者硬件加速单元。使得它能同时、且实时地处理数十种算法,以用于传感器处理、测距、定位和绘图、视觉和感知以及路径规划等任务负载。
- 八核CPU:八核 “Carmel” CPU 基于ARMv8 ISA
- 深度学习加速器(DLA):5 TOPS (FP16) | 10 TOPS (INT8)
- Volta GPU:512 CUDA cores | 20 TOPS (INT8) | 1.3 TFLOPS (FP32)
- 视觉处理器:1.6 TOPS
- 立体声和光流引擎(SOFE):6 TOPS
- 图像信号处理器(ISP):1.5 Giga Pixels/s
- 视频编码器:1.2 GPix/s
- 视频解码器:1.8 GPix/s
Xavier的主处理器可以达到ASIL-B级别的功能安全等级需求。下面是Xavier SoC的Block Diagram: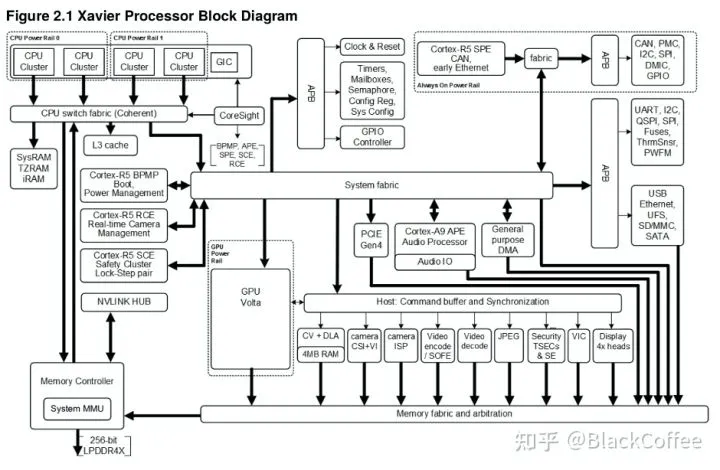
NVIDIA Xavier处理器功能模块图除了强大的计算资源外,Xavier SoC拥有丰富的IO接口资源:
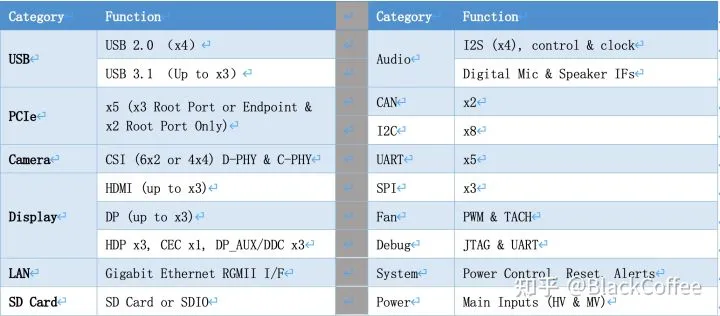
Xavier有两个版本的片上系统(System On Module),分别是Jetson AGX Xavier 8GB和Jetson AGX Xavier:
- Jetson AGX Xavier 8GB:是一款价格实惠的低功耗版的Jetson AGX Xavier,在软硬件上与现有的 Jetson AGX Xavier 完全兼容。其整个模块最高消耗 20W 功率,同时提供高达 20 TOPS 的 AI 性能。
- Jetson AGX Xavier:作为世界上第一个专为自主机器人设计的智能计算平台,Jetson AGX Xavier可以提供很高的计算性能,同时保持较低的功耗。Jetson AGX Xavier平台可以预设10W、15W和30W三种运行模式,Jetson AGX Xavier Industrial(工业版)则提供两种可选的功耗模式:20W和40W。
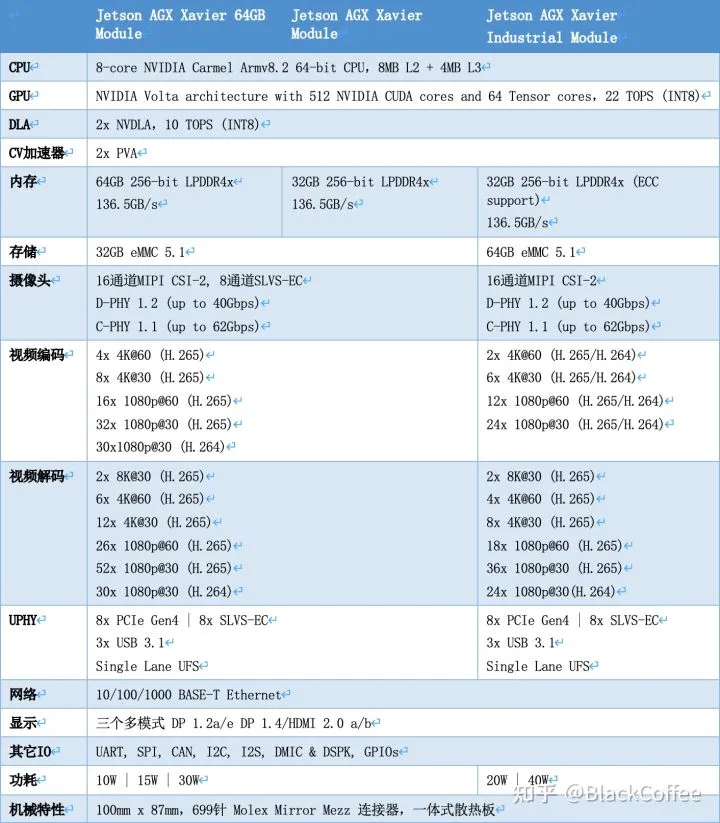
下面是各不同版本的Jetson AGX Xavier片上系统的性能参数对比:
Ecotron(ecotron.ai/)是美国一家专注于ADAS DCU(ADCU)的制造商。它于2019年9月发布了EAXVA03型ADAS域控制器,这是一款采用NVIDIA Xavier SoC和Infineon TC297 MCU打造、面向L3/L4级别自动驾驶领域的高性能中央计算平台。按照设计方案考虑,Xavier智能处理器用于环境感知、图像融合、路径规划等,TC297 MCU用于满足ISO26262功能安全需求(ASIL-C/D级别)的控制应用场景(也即作为Safety Core),比如安全监控、冗余控制、网关通讯及整车控制。目前最新的型号已经发展到EAXVA04和EAXVA05。EAXVA04是EAXVA03的升级版,还是一颗Xavier+一颗TC297的方案,而EAXVA05则采用了两颗Xavier+TC297的方案,因而可以提供更大的算力。下面是EAXVA04 ADAS域控制器的结构图:
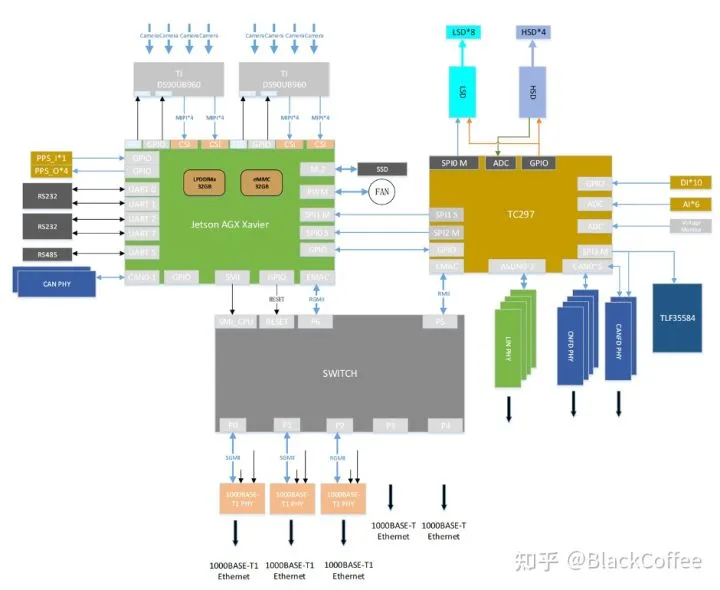
EAXVA04的方案结构图下面是EAXVA05 ADAS域控制器双Xavier+TC297 MCU的方案结构图:
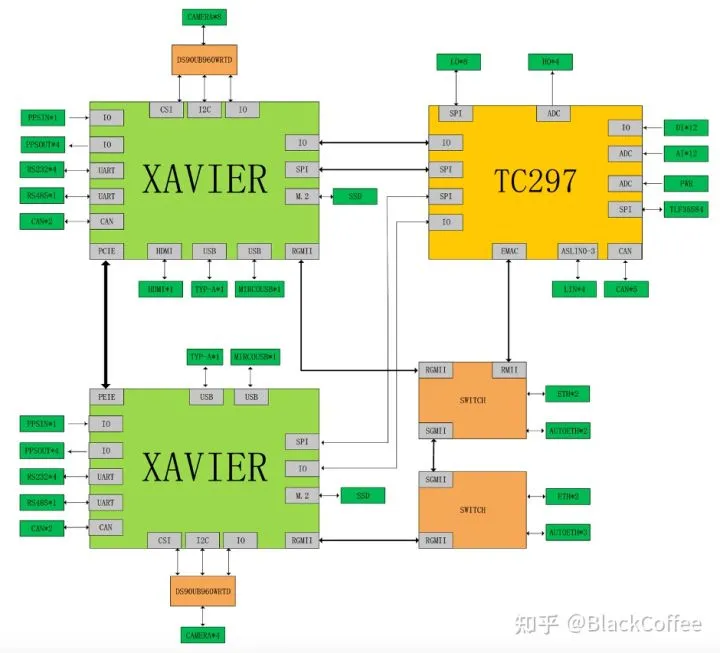
EAXVA05 ADAS域控制器结构图
(二) Orin自动驾驶计算平台
2019年12月英伟达发布了新一代面向自动驾驶和机器人领域Orin芯片和计算平台。具有ARM Hercules CPU内核和英伟达下一代GPU架构。Orin SoC包含170亿晶体管,晶体管的数量几乎是Xavier SoC的两倍,具有12个ARM Hercules内核,将集成Nvidia下一代Ampere架构的GPU,提供200 TOPS@INT8性能,接近Xavier SoC的7倍,Orin SOC将在2021年提供样片,2022年正式面向车厂量产。2020年5月GTC上,英伟达介绍了即将发布的新一代自动驾驶Drive AGX Orin平台,它可以搭载两个Orin SoC和两块NVIDIA Ampere GPU,可以实现从入门级ADAS解决方案到L5级自动驾驶出租车(Robotaxi)系统的全方位性能提升,平台最高可提供2000TOPS算力。未来L4/L5级别的自动驾驶系统将需要更复杂、更强大的自动驾驶软件框架和算法,借助强劲的计算性能,Orin计算平台将有助于并发运行多个自动驾驶应用和深度神经网络模型算法。作为一颗专为自动驾驶而设计的车载智能计算平台,Orin可以达到ISO 26262 ASIL-D 等级的功能安全标准。借助于先进的7nm制程工艺,Orin拥有非常出色的功耗水平。在拥有200TOPS的巨大算力时,TDP仅为50W。下图是Orin SoC的Block Diagram:
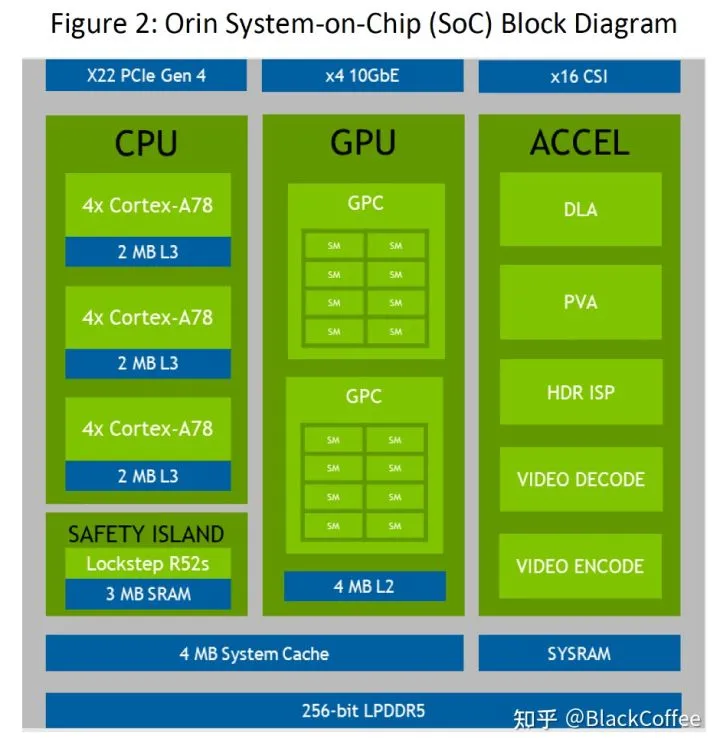
NVIDIA Orin处理器功能模块图下表是Jetson AGX Orin的片上系统的性能参数:

五、 高通Snapdragon Ride自动驾驶平台
2020年12月30日,长城汽车召开智能驾驶战略升级发布会,正式发布全新的咖啡智驾“331战略”。会上,长城还与高通达成战略合作关系,决定在量产车上搭载高通Snapdragon Ride自动驾驶平台。长城汽车计划在2022年推出全球首个基于高通Snapdragon Ride平台的L4级量产车。搭载IBEO的4D全半导体真固态激光雷达,也就是Flash激光雷达,最远有效距离可达300米。高通Snapdragon Ride自动驾驶平台在硬件方面由两块芯片构成:1)SA8540主处理器(作为ADAS域应用主处理器,满足系统级安全需求);2)SA9000B加速器,提供自动驾驶系统所需的算力。全部达到ASIL-D,可支持L1~L5级别的自动驾驶。单板的AI算力是360TOPS(INT8),整体功耗65瓦,计算能效比约为5.5TOPS/W,通过PCIe交换机可以增加到4套计算平台,四加速器的AI算力总计达1440TOPS。1)ADAS应用处理器:Kryo CPU、Adreno GPU、神经处理器、嵌入式视觉处理器2)自动驾驶专用加速器(ASIC):神经网络处理器阵列
- L1/L2级ADAS:面向具备AEB、TSR和LKA等驾驶辅助功能的汽车。硬件支持:1个ADAS应用处理器,可提供30 TOPS的算力
- L2+级ADAS:面向具备HWA(高速辅助)、自动泊车APA以及TJA(低速辅助)功能的汽车。所需硬件支持:2个或多个ADAS应用处理器,期望所需算力要求60~125 TOPS的算力
- L4/L5级自动驾驶:面向在城市交通环境中的自动驾驶乘用车、机器人出租车和机器人物流车;所需硬件支持:2个ADAS应用处理器 + 2个自动驾驶加速器(ASIC),可提供700TOPS算力,功耗为130W
到目前为止,高通还未公开其SA8540P和SA9000B两款芯片的信息,高通单独为L3/L4自动驾驶开发全新芯片的可能性极小,所以我们可以根据高通的其它相关芯片产品来大致推测一下。高通在2021年上半年正式商业化一款AI 100边缘计算套件,采用骁龙865做应用处理器,AI 100做加速器,在M.2 edge接口下,算力为70TOPS,在PCIe接口16核心下,算力可达400TOPS。根据长城的宣传图片,8540和9000都是7纳米,AI 100和骁龙865也是7纳米,PCIe也在长城的宣传图片上可以看到。当然为了车规,必须牺牲一点性能,通过降频来降低功耗,达到车规,因此性能降到了360TOPS。骁龙865是高通7纳米芯片中最顶级的,870的频率更高,最高达3.2GHz,功耗势必更高,因此8540最有可能是骁龙865的车规版芯片,当然X55的Modem可以去掉。高通只有一款加速器,SA9000B很可能就是AI 100的车规版。

高通Cloud A100 AI加速处理器高通AI 100的核心走的是DSP路线,单芯片最多有16个AI核心。每个AI核的SRAM是9MB,16个就是144MB,特斯拉FSD是64MB,基本上AI 100是特斯拉的两倍。高通套件用的是12GB的LPDDR5,特斯拉FSD只能对应LPDDR4。高通当然不会只提供硬件,而是会提供全套软硬件解决方案,包括软件SDK、工具和仿真等。
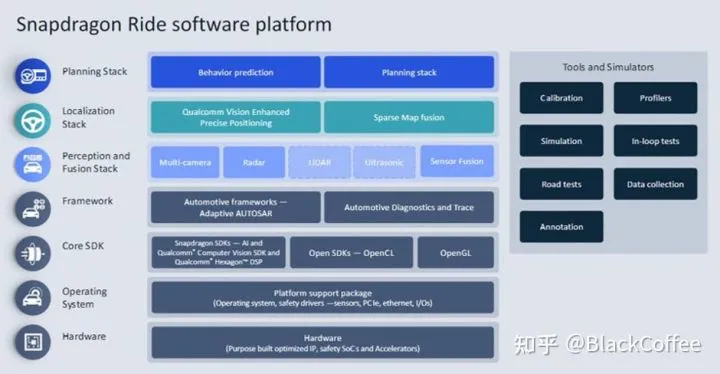
高通Snapdragon Ride自动驾驶软件栈架构高通自动驾驶平台的合作伙伴,重点是其视觉感知和驾驶策略软件栈Arriver。实际Arriver就是Veoneer的软件品牌,泊车方面主要是法雷奥,Park4u是法雷奥泊车系统的名称。DMS方面主要合作伙伴是Seeing Machines,即凯迪拉克DMS供应商。总体来看,高通的策略是自己提供端到端的完整软硬件解决方案,并同时积极布局上下游相应的生态合作伙伴。
六、 ADAS/AD芯片的关键指标
作为整个汽车的大脑,自动驾驶域控制器通常要连接多个摄像头、毫米波雷达、激光雷达以及IMU等传感器设备,并对来自这些传感器的大量数据进行处理和计算。尤其是摄像头和激光雷达所产生的数据量非常大,因此需要配置一个核心运算性能越来越强劲的自动驾驶主处理器。下面我们总结一下自动驾驶主处理器所应具有的关键指标:(一)CPU核心在汽车电子领域,通常以DMIPS(Dhrystone MIPS)来测量CPU核心的整数计算能力。Dhrystone标准的测试方法很简单,就是单位时间内跑了多少次Dhrystone程序,其指标单位为DMIPS/MHz。MIPS是Million Instructions Per Second的缩写,每秒处理的百万级的机器语言指令数。DMIPS中的D是Dhrystone的缩写,它表示了在Dhrystone标准的测试方法下的MIPS。除了Dhrystone Benchmark之外,CoreMark是另一套在嵌入式领域常见的CPU核心性能的测试基准。CoreMark是由嵌入式微处理器基准评测协会EEMBC的Shay Gla-On于2009年提出的一项基准测试程序,其主要目标是测试处理器核心性能,这个标准被认为比陈旧的Dhrystone标准更有实际价值。(二)Memory带宽自动驾驶芯片平台因为要接入大量的传感器数据,因此内存的压力非常大。整个系统往往呈现出Memory-Bound系统的特点,因此内存带宽通常决定了系统性能的理论上限。比如常见的256-bit LPDDR4@4266,其带宽为:(256 * 4266)/ (8 * 1000)= 136.5GB/s。256-bit LPDDR5@6400的带宽为:(256 * 6400) / (8 * 1000) = 204.8 GB/s。(三)AI算力自动驾驶系统因为要处理各种各样的传感器数据,因此对算力需求很大。其中当属对来自摄像头的视觉图像数据的处理最为消耗算力。自动驾驶级别每升高一个级,其所需算力至少增加数倍。比如:L2级别需要10+ TOPS的算力,L3需要100 TOPS左右的算力,L4级别可能需要500 TOPS左右的算力,L5级别甚至需要1000+ TOPS以上的算力。除了理论硬件算力之外,实际的算力利用率也至关重要。不同AI加速器的架构设计通常会导致不同的硬件算力实际利用率,因而相同的神经网络模型在两款具有相同硬件理论算力的AI加速器上跑出不同的实测性能。(四)能效比能效比是算力与TDP功耗之比,也即每瓦功耗所能贡献的理论算力值,这是衡量AI加速器设计好坏的一个非常重要指标。比如:NIVIDA Orin芯片的算力为200TOPS,TDP是50W,其能效比约为4TOPS/W。(五)车规与功能安全与消费电子产品相比,汽车芯片在安全性和可靠性上有这个最高的要求。汽车芯片长年工作在“-40℃到125℃”高低温以及剧烈震动的恶劣环境下,为了保证汽车电子产品达到对工作温度、可靠性与产品寿命的高标准质量要求,国际汽车电子协会(Automotive Electronics Council,AEC)建立了相关的质量认证标准,其中AEC-Q100是针对于车载集成电路压力测试的认证标准。AEC-Q100标准经过多年发展,已经成为汽车电子产品在可靠性和产品寿命等方面的工业事实标准。除了满足车规级要求之外,自动驾驶芯片也需要满足由ISO 26262标准定义的“功能安全(Function Safety,简称Fusa)”的认证要求。功能安全对芯片上的设计要求是要尽可能找出并纠正芯片的失效(分为:系统失效和随机失效)。系统失效本质上是产品设计上的缺陷,因此主要依靠设计和实现的流程规范来保证,而随机失效则更多依赖于芯片设计上的特殊失效探测机制来保证。ISO 26262对安全等级做了划分,常见的是ASIL-B和ASIL-D级别。ASIL-B要求芯片能覆盖90%的单点失效场景,而ASIL-D则要求能达到99%。芯片面积越大,晶体管越多,相应的失效率越高。(六)视觉接口与处理能力摄像头接入目前通常采用MIPI-CSI2接口标准。MIPI CSI(Camera Serial Interface)是由MIPI联盟下 Camera 工作组指定的接口标准。CSI-2 是 MIPI CSI 第二版,主要由应用层、协议层、物理层组成,最大支持4通道数据传输、单线传输速度高达1Gb/s。同时接入的摄像头路数是自动驾驶芯片的一个重要指标。比如:NVIDIA的Xavier/Orin都允许同时接入16路摄像头。ISP作为视觉成像处理的核心芯片,也是非常重要的。自动驾驶芯片通常内置集成的ISP模块。通过MIPI-CSI-2接口所连接的摄像头Sensor,先把Raw图像数据送给ISP进行处理,ISP处理过后的RGB/YUV图像数据再送给其它模块,比如:CODEC或CV加速器等。为了得到更好的图像效果,自动驾驶汽车上对ISP的要求非常高。此外,跟视觉处理相关的重要特性还包括:图像绘制加速GPU,显示输出接口以及视频编解码等。(七)丰富的IO接口资源自动驾驶的主控处理器需要丰富的接口来连接各种各样的传感器设备。目前业界常见的自动驾驶传感器主要有:摄像头、激光雷达、毫米波雷达、超声波雷达、组合导航、IMU以及V2X模块等。
- 对摄像头的接口类型主要有:MIPI CSI-2、LVDS、FPD Link等。
- 激光雷达一般是通过普通的Ethernet接口来连接。
- 毫米波雷达都是通过CAN总线来传输数据
- 超声波雷达基本都是通过LIN总线
- 组合导航与惯导IMU常见接口是RS232
- V2X模块一般也是采用Ethernet接口来传输数据
除了上述传感器所需IO接口外,常见的其它高速接口与低速接口也都是需要的,比如:PCIe、USB、I2C、SPI、RS232等等。