














hi ,大家好,今天分享一篇后台服务器性能优化之网络性能优化,希望大家对Linux网络有更深的理解。
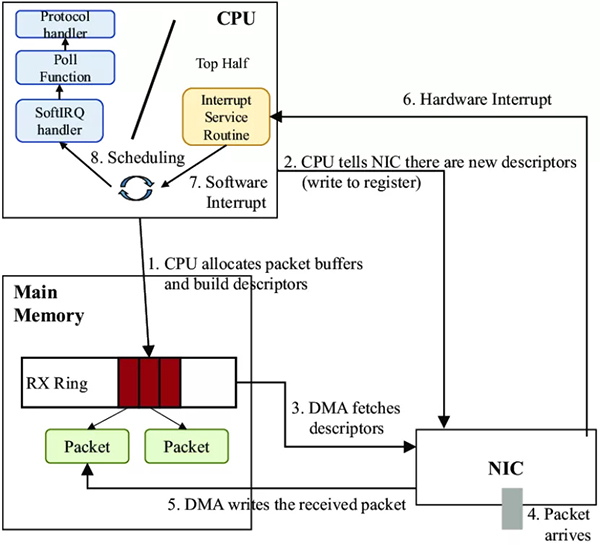
曾几何时,一切都是那么简单。网卡很慢,只有一个队列。当数据包到达时,网卡通过DMA复制数据包并发送中断,Linux内核收集这些数据包并完成中断处理。随着网卡越来越快,基于中断的模型可能会因大量传入数据包而导致 IRQ 风暴。这将消耗大部分 CPU 功率并冻结系统。
为了解决这个问题,NAPI(中断+轮询)被提议。当内核收到来自网卡的中断时,它开始轮询设备并尽快收集队列中的数据包。NAPI 可以很好地与现在常见的 1 Gbps 网卡配合使用。但是,对于10Gbps、20Gbps甚至40Gbps的网卡,NAPI可能还不够。如果我们仍然使用一个 CPU 和一个队列来接收数据包,这些卡将需要更快的 CPU。
幸运的是,现在多核 CPU 很流行,那么为什么不并行处理数据包呢?
RSS:接收端缩放
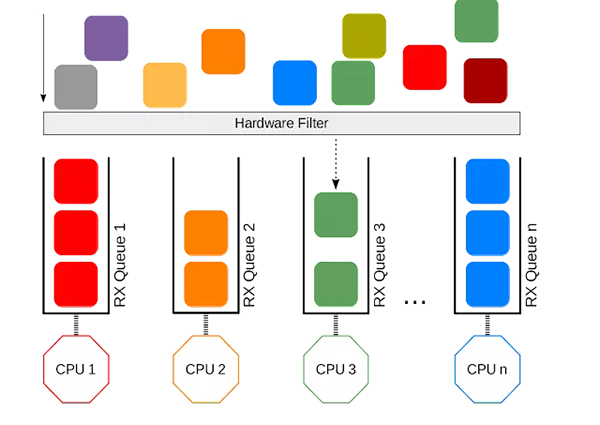
Receive Side Scaling(RSS)是所述机构具有多个RX / TX队列过程的数据包。当带有RSS 的网卡接收到数据包时,它会对数据包应用过滤器并将数据包分发到RX 队列。过滤器通常是一个哈希函数,可以通过“ethtool -X”进行配置。如果你想在前 3 个队列中均匀分布流量:
# ethtool -X eth0 equal 3- 1.
或者,如果你发现一个特别有用的魔法哈希键:
# ethtool -X eth0 hkey <magic hash key>- 1.
对于低延迟网络,除了过滤器之外,CPU 亲和性也很重要。最佳设置是分配一个 CPU 专用于一个队列。首先通过检查/proc/interrupt找出IRQ号,然后将CPU位掩码设置为/proc/irq/<IRQ_NUMBER>/smp_affinity来分配专用CPU。为避免设置被覆盖,必须禁用守护进程irqbalance。请注意,根据内核文档,超线程对中断处理没有任何好处,因此最好将队列数与物理 CPU 内核数相匹配。
RPS:接收数据包控制
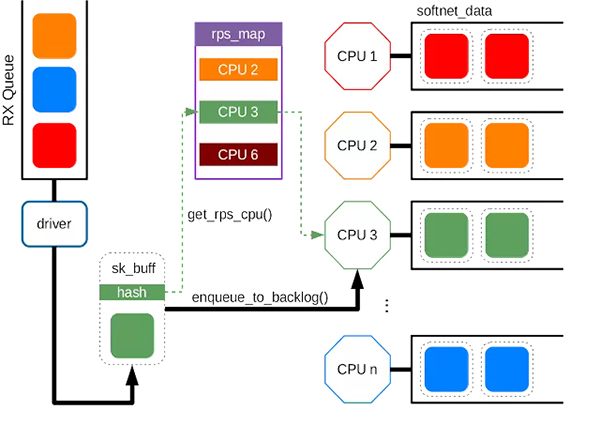
RSS提供硬件队列,一个称为软件队列机制Receive Packet Steering (RPS)在Linux内核实现。
当驱动程序接收到数据包时,它会将数据包包装在套接字缓冲区 ( sk_buff ) 中,其中包含数据包的u32哈希值。散列是所谓的第 4 层散列(l4 散列),它基于源 IP、源端口、目的 IP 和目的端口,由网卡或__skb_set_sw_hash() 计算。由于相同 TCP/UDP 连接(流)的每个数据包共享相同的哈希值,因此使用相同的 CPU 处理它们是合理的。
RPS 的基本思想是根据每个队列的 rps_map 将同一流的数据包发送到特定的 CPU。这是 rps_map 的结构:映射根据 CPU 位掩码动态更改为/sys/class/net/<dev>/queues/rx-<n>/rps_cpus。比如我们要让队列使用前3个CPU,在8个CPU的系统中,我们先构造位掩码,0 0 0 0 0 1 1 1,到0x7,然后
#echo 7 > /sys/class/net /eth0/queues/rx-0/rps_cpus- 1.
这将保证从 eth0 中队列 0 接收的数据包进入 CPU 1~3。驱动程序在 sk_buff 中包装一个数据包后,它将到达netif_rx_internal()或netif_receive_skb_internal(),然后到达 get_rps_cpu()
struct rps_map {
unsigned int len;
struct rcu_head rcu;
u16 cpus[0];
};- 1.
- 2.
- 3.
- 4.
- 5.
将被调用以将哈希映射到 rps_map 中的条目,即 CPU id。得到CPU id后,enqueue_to_backlog()将sk_buff放到特定的CPU队列中进行进一步处理。每个 CPU 的队列在 per-cpu 变量softnet_data 中分配。
使用RPS的好处是可以在 CPU 之间分担数据包处理的负载。但是,如果RSS 可用,则可能没有必要,因为网卡已经对每个队列/CPU 的数据包进行了排序。但是,如果队列中的CPU数更多,RPS 仍然可以发挥作用。在这种情况下,每个队列可以与多个 CPU相关联并在它们之间分发数据包。
RFS: Receive Flow Steering

尽管 RPS 基于流分发数据包,但它没有考虑用户空间应用程序。应用程序可能在 CPU A 上运行,而内核将数据包放入 CPU B 的队列中。由于 CPU A 只能使用自己的缓存,因此 CPU B 中缓存的数据包变得无用。Receive Flow Steering(RFS)进一步延伸为RPS的应用程序。
代替每个队列的哈希至CPU地图,RFS维护全局flow-to-CPU的表,rps_sock_flow_table:该掩模用于将散列值映射成所述表的索引。由于表大小将四舍五入到 2 的幂,因此掩码设置为table_size - 1。
struct rps_sock_flow_table {
u32 mask;
u32 ents[0];
};- 1.
- 2.
- 3.
- 4.
并且很容易找到索引:a sk_buff与hash & scok_table->mask。
该条目由 rps_cpu_mask划分为流 id 和 CPU id。低位用于CPU id,而高位用于流id。当应用程序对套接字进行操作时(inet_recvmsg()、inet_sendmsg()、inet_sendpage()、tcp_splice_read()),将调用sock_rps_record_flow()来更新sock 流表。
当数据包到来时,将调用get_rps_cpu()来决定使用哪个 CPU 队列。下面是get_rps_cpu()如何决定数据包的 CPU
ident = sock_flow_table->ents[hash & sock_flow_table->mask];
if ((ident ^ hash) & ~rps_cpu_mask)
goto try_rps;
next_cpu = ident & rps_cpu_mask;- 1.
- 2.
- 3.
- 4.
使用流表掩码找到条目的索引,并检查散列的高位是否与条目匹配。如果是,它会从条目中检索 CPU id 并为数据包分配该 CPU。如果散列不匹配任何条目,它会回退到使用 RPS 映射。
可以通过rps_sock_flow_entries调整 sock 流表的大小。例如,如果我们要将表大小设置为 32768:
#echo 32768 > /proc/sys/net/core/rps_sock_flow_entries- 1.
sock流表虽然提高了应用的局部性,但也带来了一个问题。当调度器将应用程序迁移到新 CPU 时,旧 CPU 队列中剩余的数据包变得未完成,应用程序可能会得到乱序的数据包。为了解决这个问题,RFS 使用每个队列的rps_dev_flow_table来跟踪未完成的数据包。
下面是该结构rps_dev_flow_table:到袜子流表中,类似的rps_dev_flow_table也使用table_size - 1作为掩模而表的大小也必须被向上舍入到2的幂当流量分组被入队,last_qtail被更新
struct rps_dev_flow {
u16 cpu;
u16 filter; /* For aRFS */
unsigned int last_qtail;
};
struct rps_dev_flow_table {
unsigned int mask;
struct rcu_head rcu;
struct rps_dev_flow flows[0];
};- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
到 CPU 队列的尾部。如果应用程序迁移到新 CPU,则 sock 流表将反映更改,并且get_rps_cpu()将为流设置新 CPU。在设置新 CPU 之前,get_rps_cpu() 会检查当前队列的头部是否已经通过 last_qtail。如果是这样,这意味着队列中没有更多未完成的数据包,并且可以安全地更改 CPU。否则,get_rps_cpu()仍将使用rps_dev_flow->cpu 中记录的旧 CPU 。
每个队列的流表(rps_dev_flow_table)的大小可以通过 sysfs 接口进行配置:
/sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt- 1.
建议将rps_flow_cnt设置为 ( rps_sock_flow_entries / N) 而 N 是 RX 队列的数量(假设流在队列中均匀分布)。
ARFS:加速接收流量转向
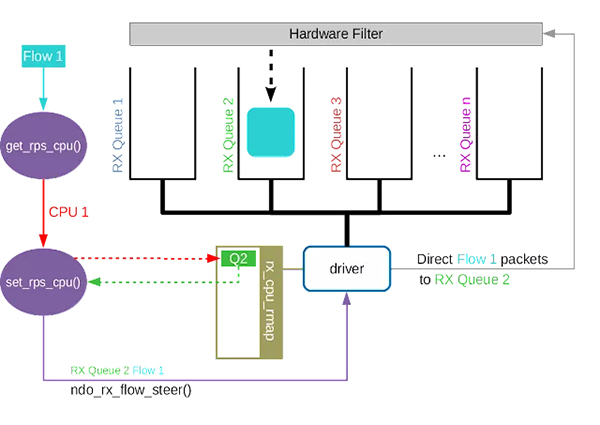
Accelerated Receive Flow Steering(aRFS)进一步延伸RFS为RX队列硬件过滤。要启用 aRFS,它需要具有可编程元组过滤器和驱动程序支持的网卡。要启用ntuple 过滤器。
# ethtool -K eth0 ntuple on- 1.
要使驱动程序支持aRFS,它必须实现ndo_rx_flow_steer以帮助set_rps_cpu()配置硬件过滤器。当get_rps_cpu()决定为流分配一个新 CPU 时,它会调用set_rps_cpu()。set_rps_cpu()首先检查网卡是否支持 ntuple 过滤器。如果是,它将查询rx_cpu_rmap为流找到合适的 RX 队列。
rx_cpu_rmap是驱动维护的特殊映射。该映射用于查找哪个 RX 队列适合 CPU。它可以是与给定 CPU 直接关联的队列,也可以是处理 CPU 在缓存位置最接近的队列。获取 RX 队列索引后,set_rps_cpu()调用ndo_rx_flow_steer()以通知驱动程序为给定的流创建新过滤器。ndo_rx_flow_steer()将返回过滤器 id,过滤器 id 将存储在每个队列的流表中。
除了实现ndo_rx_flow_steer() 外,驱动程序还必须调用rps_may_expire_flow() 定期检查过滤器是否仍然有效并删除过期的过滤器。
SO_REUSEPORT
linux man文档中一段文字描述其作用:
The new socket option allows multiple sockets on the same host to bind to the same port, and is intended to improve the performance of multithreaded network server applications running on top of multicore systems.
简单说,SO_REUSEPORT支持多个进程或者线程绑定到同一端口,用以提高服务器程序的性能。我们想了解为什么这个特性这么火(经常被大厂面试官问到),到底是解决什么问题。
Linux系统上后台应用程序,为了利用多核的优势,一般使用以下比较典型的多进程/多线程服务器模型:
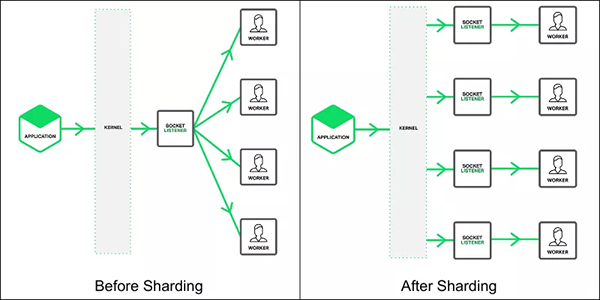
- 单线程listen/accept,多个工作线程接收任务分发,虽CPU的工作负载不再是问题,但会存在:
1. 单线程listener,在处理高速率海量连接时,一样会成为瓶颈;
2. CPU缓存行失效(丢失套接字结构socket structure)现象严重;
- 所有工作线程都accept()在同一个服务器套接字上呢,一样存在问题:
1. 多线程访问server socket锁竞争严重;
2. 高负载下,线程之间处理不均衡,有时高达3:1不均衡比例;
3. 导致CPU缓存行跳跃(cache line bouncing);
4. 在繁忙CPU上存在较大延迟;
上面模型虽然可以做到线程和CPU核绑定,但都会存在以下问题:
- 单一listener工作线程在高速的连接接入处理时会成为瓶颈
- 缓存行跳跃
- 很难做到CPU之间的负载均衡
- 随着核数的扩展,性能并没有随着提升
SO_REUSEPORT支持多个进程或者线程绑定到同一端口:
- 允许多个套接字 bind()/listen() 同一个TCP/UDP端口
1.每一个线程拥有自己的服务器套接字。
2.在服务器套接字上没有了锁的竞争。
- 内核层面实现负载均衡。
- 安全层面,监听同一个端口的套接字只能位于同一个用户下面。
其核心的实现主要有三点:
- 扩展socket option,增加
- SO_REUSEPORT选项,用来设置 reuseport。
- 修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口。
- 修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择
带来意义
- CPU之间平衡处理,水平扩展,模型简单,维护方便了,进程的管理和应用逻辑解耦,进程的管理水平扩展权限下放给程序员/管理员,可以根据实际进行控制进程启动/关闭,增加了灵活性。这带来了一个较为微观的水平扩展思路,线程多少是否合适,状态是否存在共享,降低单个进程的资源依赖,针对无状态的服务器架构最为适合。
- 针对对客户端而言,表面上感受不到其变动,因为这些工作完全在服务器端进行。
- 服务器无缝重启/切换,热更新,提供新的可能性。我们迭代了一版本,需要部署到线上,为之启动一个新的进程后,稍后关闭旧版本进程程序,服务一直在运行中不间断,需要平衡过度。这就像Erlang语言层面所提供的热更新一样。
SO_REUSEPORT已知问题
- SO_REUSEPORT分为两种模式,即热备份模式和负载均衡模式,在早期的内核版本中,即便是加入对reuseport选项的支持,也仅仅为热备份模式,而在3.9内核之后,则全部改为了负载均衡模式,两种模式没有共存,虽然我一直都希望它们可以共存。
- SO_REUSEPORT根据数据包的四元组{src ip, src port, dst ip, dst port}和当前绑定同一个端口的服务器套接字数量进行数据包分发。若服务器套接字数量产生变化,内核会把本该上一个服务器套接字所处理的客户端连接所发送的数据包(比如三次握手期间的半连接,以及已经完成握手但在队列中排队的连接)分发到其它的服务器套接字上面,可能会导致客户端请求失败。
如何预防以上已知问题,一般解决思路:
1.使用固定的服务器套接字数量,不要在负载繁忙期间轻易变化。
2.允许多个服务器套接字共享TCP请求表(Tcp request table)。
3.不使用四元组作为Hash值进行选择本地套接字处理,比如选择 会话ID或者进程ID,挑选隶属于同一个CPU的套接字。
4. 使用一致性hash算法。
与其他特性关系
1. SO_REUSEADDR:主要是地址复用
1.1 让处于time_wait状态的socket可以快速复用原ip+port
1.2 使得0.0.0.0(ipv4通配符地址)与其他地址(127.0.0.1和10.0.0.x)不冲突
1.3 SO_REUSEADDR 的缺点在于,没有安全限制,而且无法保证所有连接均匀分配。
2.与RFS/RPS/XPS-mq协作,可以获得进一步的性能
2.1.服务器线程绑定到CPUs
2.2.RPS分发TCP SYN包到对应CPU核上
2.3.TCP连接被已绑定到CPU上的线程accept()
2.4. XPS-mq(Transmit Packet Steering for multiqueue),传输队列和CPU绑定,发送 数据
2.5. RFS/RPS保证同一个连接后续数据包都会被分发到同一个CPU上,网卡接收队列 已经绑定到CPU,则RFS/RPS则无须设置,需要注意硬件支持与否,目的是数据包的软硬中断、接收、处理等在一个CPU核上,并行化处理,尽可能做到资源利用最大化。
SO_REUSEPORT的演进
- 3.9之前内核,能够让多个socket同时绑定完全相同的ip+port,但不能实现负载均衡,实现是热备。
- Linux 3.9之后,能够让多个socket同时绑定完全相同的ip+port,可以实现负载均衡。
- Linux4.5版本后,内核引入了reuseport groups,它将绑定到同一个IP和Port,并且设置了SO_REUSEPORT选项的socket组织到一个group内部。目的是加快socket查询。
总结
Linux网络堆栈所存在问题
- TCP处理&多核
- 一个完整的TCP连接,中断发生在一个CPU核上,但应用数据处理可能会在另外一个核上
- 不同CPU核心处理,带来了锁竞争和CPU Cache Miss(波动不平衡)
- 多个进程监听一个TCP套接字,共享一个listen queue队列
- 用于连接管理全局哈希表格,存在资源竞争
- epoll IO模型多进程的惊群现象
- Linux VFS的同步损耗严重
- Socket被VFS管理
- VFS对文件节点Inode和目录Dentry有同步需求
- SOCKET只需要在内存中存在即可,非严格意义上文件系统,不需要Inode和Dentry
- 代码层面略过不必须的常规锁,但又保持了足够的兼容性
RSS、RPS、RFS 和 aRFS,这些机制是在 Linux 3.0 之前引入的,SO_REUSEPORT选项在Linux 3.9被引入内核,因此大多数发行版已经包含并启用了它们。深入了解它们,以便为我们的服务器系统找到最佳性能配置。
性能优化无极限,我们下期再继续分享!















