本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
华为诺亚方舟实验室开源了第一个亿级中文多模态数据集:悟空。
这个新发布的数据集不仅规模大——包含1亿组图文对,而且质量也很高。
所有图像都是筛选过的,长宽都在200个像素以上,比例从1/3-3不等。
而和图像对应的文本也根据其语言、长度和频率进行了过滤,隐私和敏感词也都考虑在内。
例如这一组数据集中的例子,内容还相当新,像进门扫码登记,社区疫苗接种的防疫内容都有。

这一波可以说是填上了大规模中文多模态数据集的缺口。
悟空数据集
自一年前OpenAI的CLIP+Dall·E组合开启新一轮多模态学习浪潮以来,算上后续的ALIGN和FILIP,都在视觉语言预训练(VLP)领域表现优异。
世界范围内的成功离不开大规模数据集的支持,但中文开源数据方面,有是有,规模大的不多。
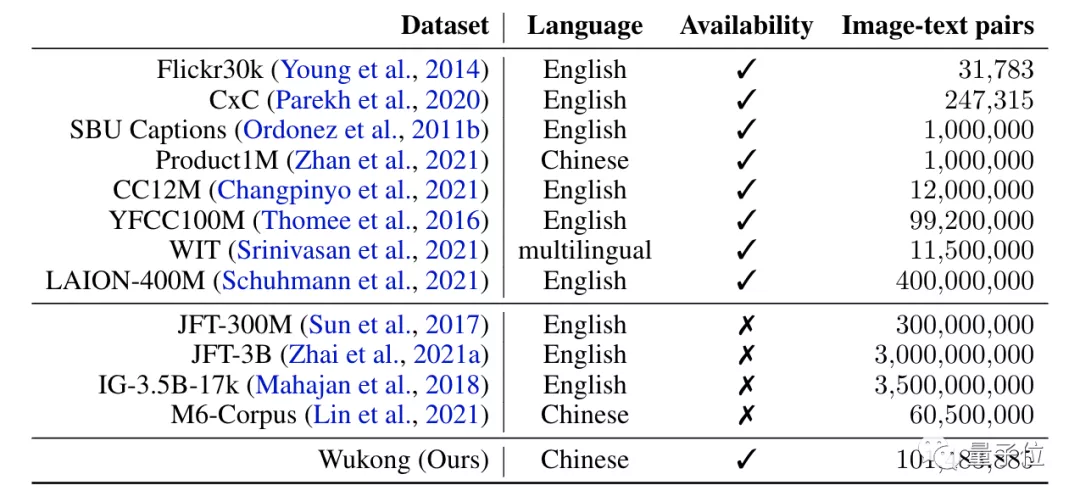
有了“悟空”数据集之后,就可以支持更多预训练模型用于下游任务。
数据集之外,团队还附赠了一款基本模型,参考了流行的文本图像双编码器架构:
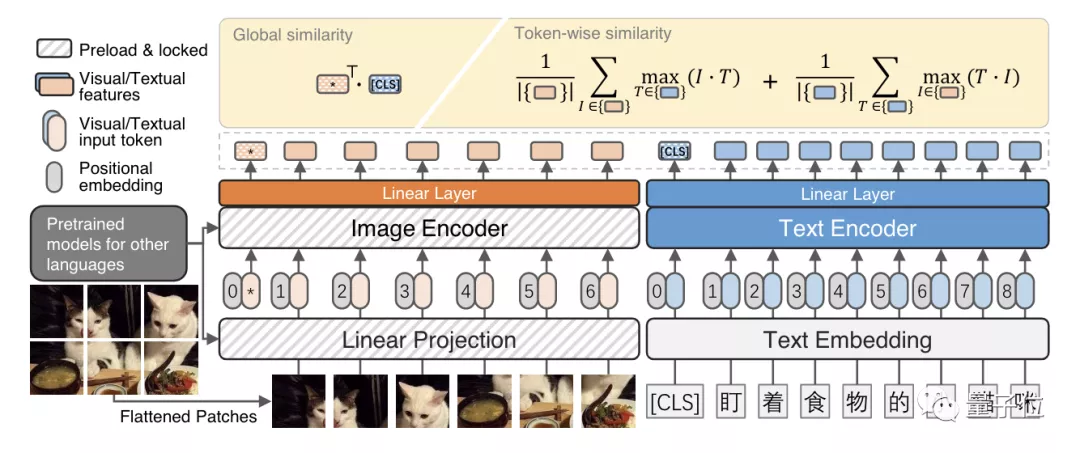
其中视觉标记和文本标记作为输入。然后,将两种模式的输入标记连接起来,并用位置嵌入来显示标记位置。
有意思的一点是,这里的图像编码器是从英文数据集上训练的,上面预加载并锁定了从外部模型中训练的英文数据集中的权重。
但是仍然可以中文文本进行跨模态预训练,在下游任务中也表现得很好。
除此之外,华为诺亚还提供了不同下游任务的基准测试。
例如零样本图像分类,下图中除了WukongViT-500M,其他的悟空模型变体都是在这个一亿的数据库上训练的:
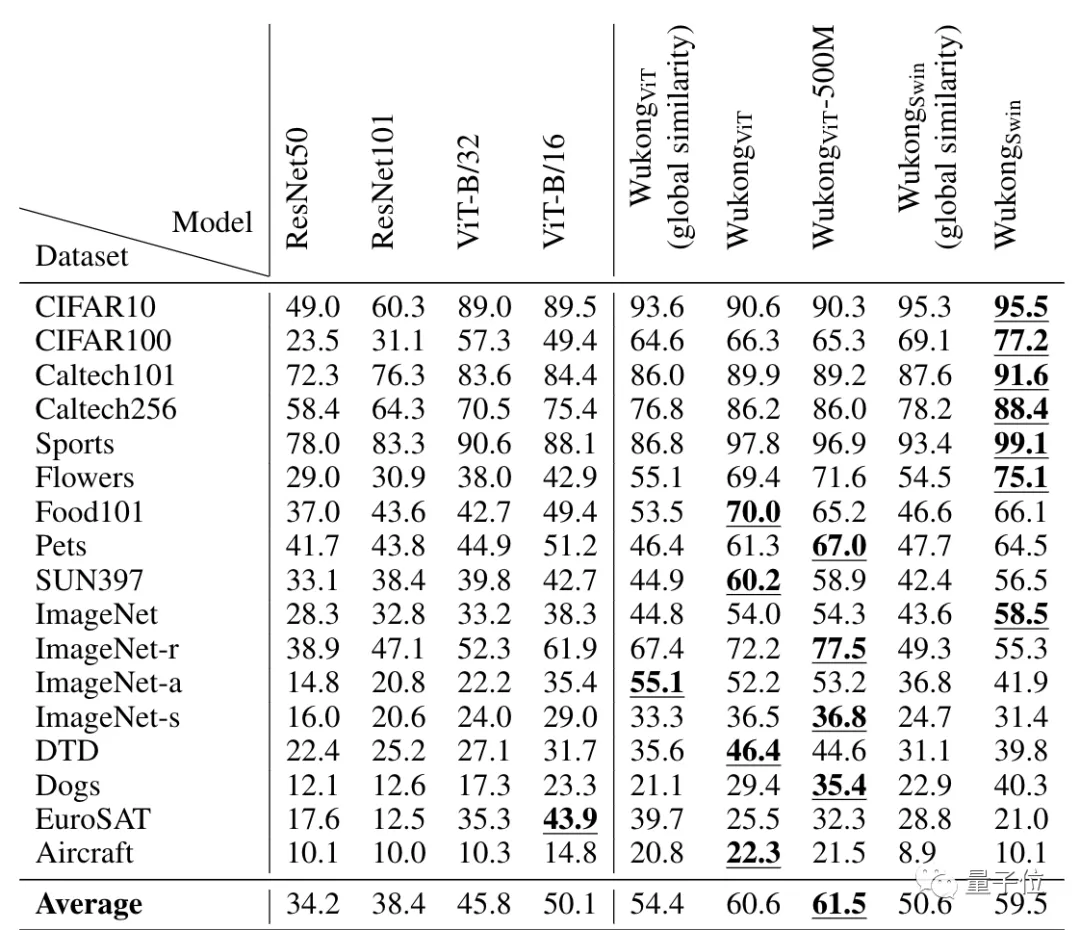
再比如在图像检索文本和文本检索图像这两个任务上,在五个不同的数据集上的测试结果如下:
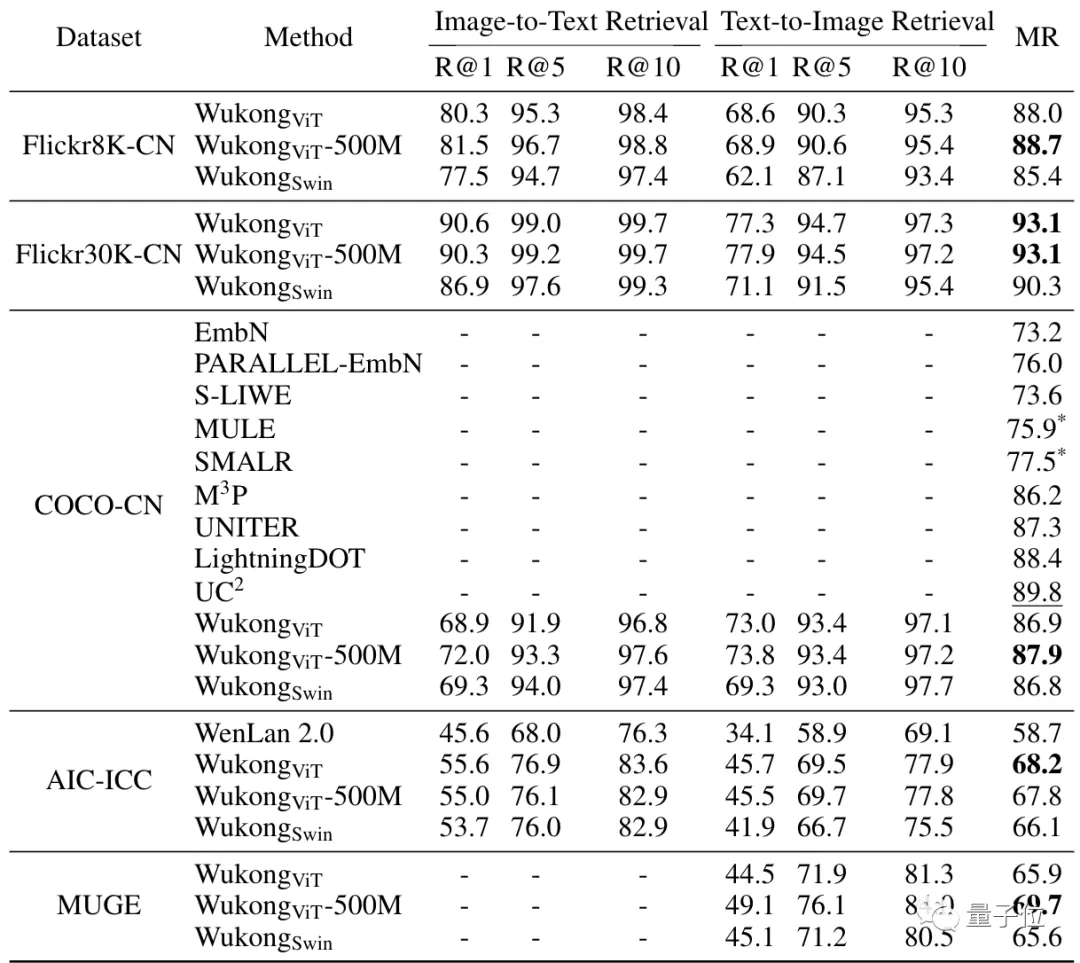
而这也证明了将在英语数据集上预训练的图像编码器应用于中文多模态预训练的良好效果。未来也可能会探索更多的解决方案,利用悟空数据集训练多语言跨模态模型。
目前悟空数据集在官网即可下载(链接在文末),赶快用起来吧~
数据集地址:
https://wukong-dataset.github.io/wukong-dataset/benchmark.html
论文地址:
https://arxiv.org/abs/2202.06767