从领域模型说起
回顾一下我们进行领域建模时候的流程:
- 进行需求分析
- 进行用例设计
- 针对用例进行领域建模
- 针对领域模型并行进行数据库设计和程序设计。
在经过了前面几步分析后,我们会得到领域模型以及他们之间的关系。在这之后我们要根据领域模型分别进行数据库设计与程序设计。我们会根据领域模型之间的关系将模型之间的关系映射到系统表设计之间的关系。那么我们该怎么进行对应的程序设计呢?
一般来说:
将领域模型设计转化为程序设计,有贫血模型与充血模型两种方法。
贫血模型
在之前的文章中我们举过一个订单模型的例子:
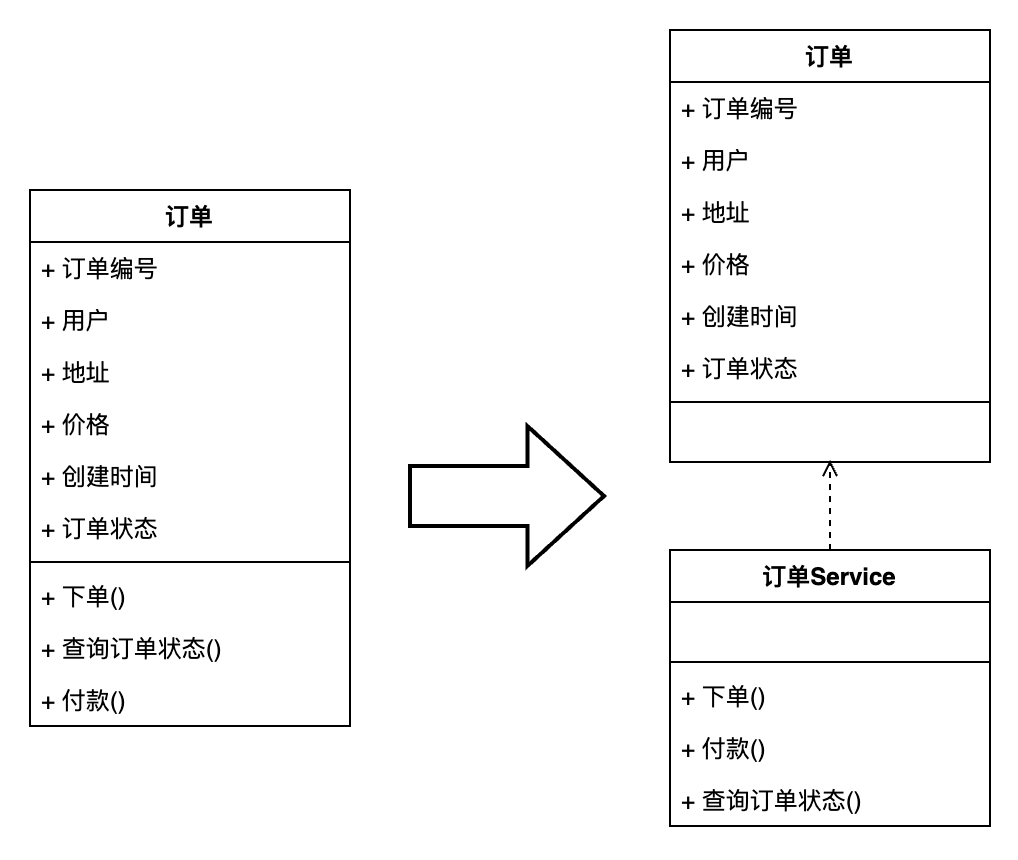
在这个例子中我们经过了设计和抽象得到了一个订单模型。而根据这个模型,我们可以直接将模型中的属性抽离成为一个模型设计,将模型中的方法能力抽取为一个服务设计。也就是说:
只由属性及其赋值器、取值器构成的对象,我们称之为贫血模型。
那么如果使用贫血模型进行领域模型的程序设计,就会像上图中的例子一样,得到一个领域模型的实体对象与服务。实体对象将包含模型对象的所有属性与数据,服务中包含领域模型中的所有方法。当我们希望使用领域模型中的方法时,是将模型实体作为参数调用服务中领域模型对应的方法。
在利用贫血模型建模后,原有的领域模型中的数据与方法被割裂到了两个对象中。而这种割裂使得原本被封装到一个对象中的内容,被分开到了两个对象中。而打破了原本领域模型的封装性。
封装性的打破会带来新的问题,我举一个我在实际生产中遇到过的例子:
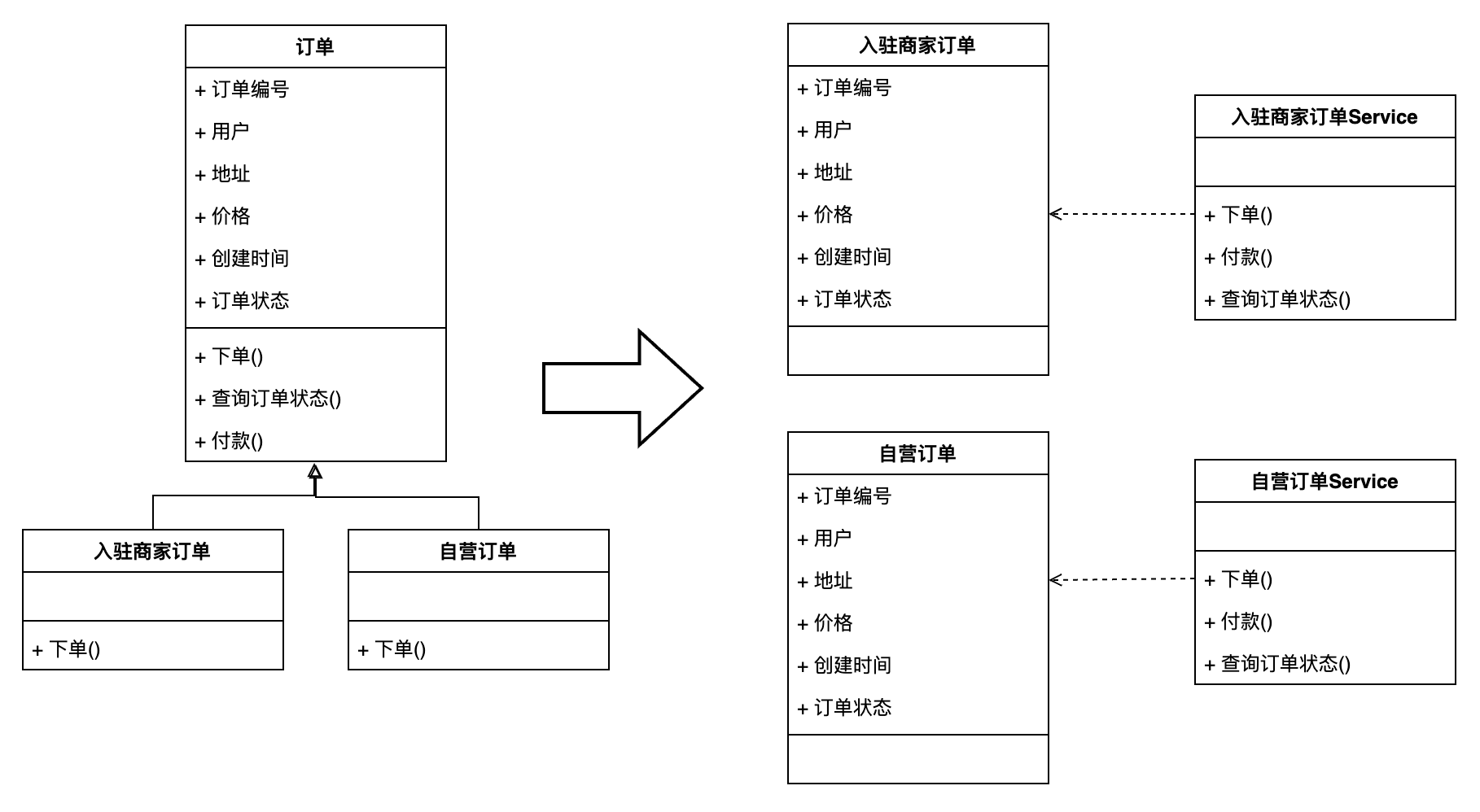
如图所示,如果对于订单来说我们出现了两种子对象:入驻商家订单、自营订单。对于这两种订单的下单方法中是有不一样的业务流程的。如果使用贫血模型设计的话,我们很容易就想到将两个不一样的下单业务流程分别通过两个服务来实现。那么对应的,为了区分服务的不同,就需要将订单也分别分割为两个对象,并且指定的对象作为入参调用对应的服务。
而当这样设计了之后,在订单上游还需要一层业务编排层来对订单数据的流转进行处理,以保证对应的对象不会错误地进入到。
按照这样的设计思想,如果在在这个基础上新增一个“分销订单”。我们就需要调整三个地方:新增分销订单对象、新增分销订单服务、调整上游编排层。显然这不符合开闭原则,同时业务开发的成本也提高。
注:我们可以通过设计模式优化最终实现的逻辑,但是设计思想是这样的。
充血模型
贫血模型的问题在于割裂了领域模型的封装,那么不对模型的封装进行割裂,而是保留领域模型的原貌进行程序设计,就是充血模型。可以描述为:
将领域模型中的方法直接在领域对象中实现,就是充血模型设计。
根据上文中的订单领域模型,如果我们换成充血模型设计,就变为了:
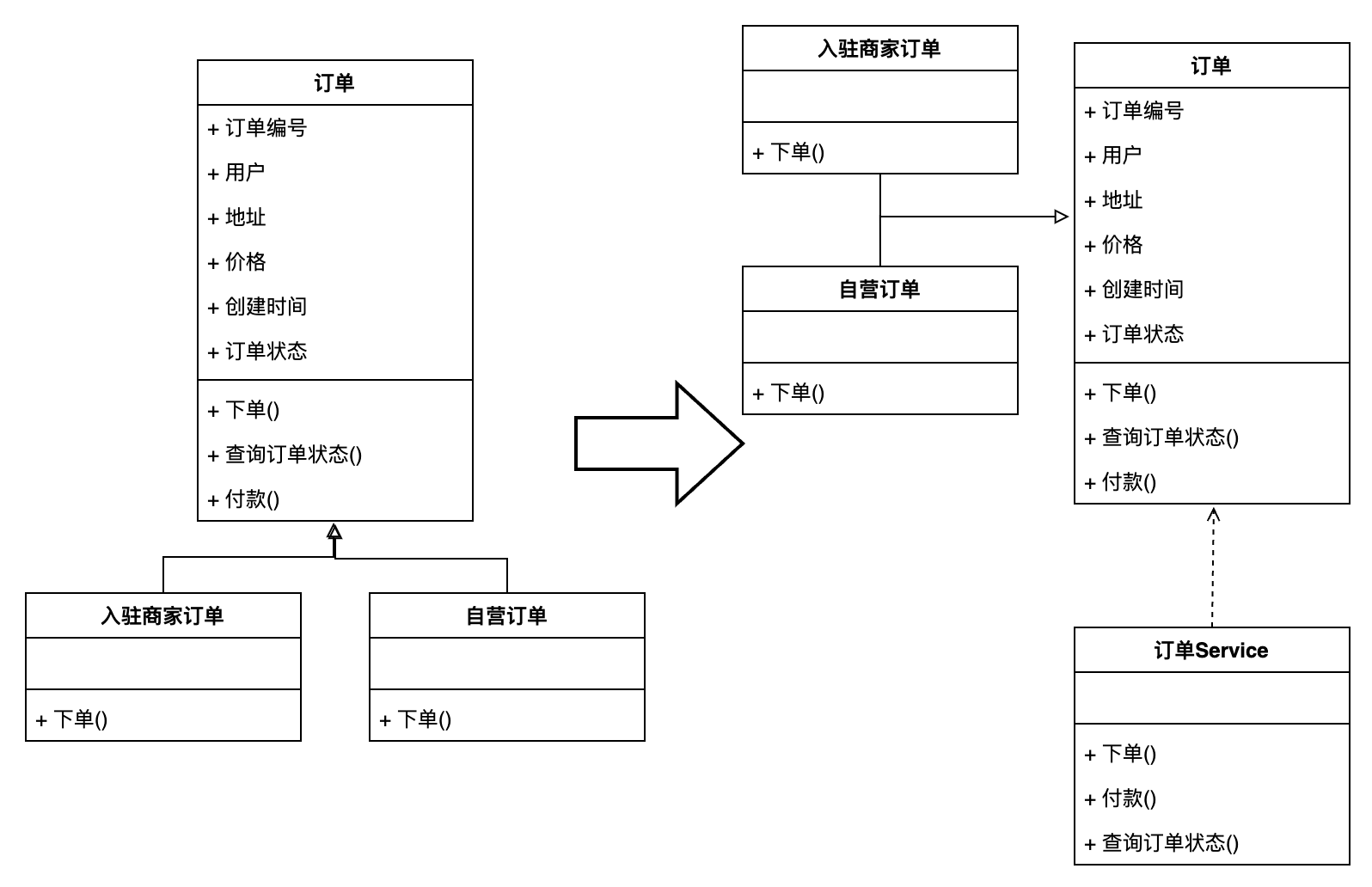
可以看到,如果采用充血模型的设计,订单的实体对象中是包含领域模型中的方法的,也就是说下单的实际逻辑由订单对象自己完成。而对于订单对象中的子对象,也仅需要继承订单对象,然后实现自己的下单方法即可。使用充血模型设计后我们发现仍然有订单对应的服务,但是这个服务仅执行一个调用订单对象中对应逻辑的作用,而这样的服务是不关心具体调用的是哪一个子类的。
所以,我们使用充血模型设计,当需要新增一个“分销订单”时,就只需要创建一个订单的新的子类,然后在类中实现对应的下单逻辑就可以了,而这是符合开闭原则的。
而由于充血模型还原的是领域模型的原貌,所以在依据领域模型进行程序设计的时候,其映射关系直观,所以对应的代码修改就更直接。
贫血模型VS充血模型
通过上文分析,充血模型是全面优于贫血模型的。但是在实际的开发应用中并非如此。
贫血模型比充血模型实现更简单
由于充血模型是还原领域模型的原貌,所以在进行程序的操作的时候,需要将模型下的所有组合、聚合对象都进行组装,以订单为例,订单需要:订单、订单明细、用户、用户地址、商品等5个对象进行封装。而由于封装的复杂性,所以还需要设计订单仓库、订单工厂等组件用于创建订单的对象。同时因为创建后的对象大小可能会比较大,订单仓库中一般还需要进行缓存设计。总的来说:
充血模型要依靠强大的技术平台来维护模型的使用。
而因为贫血模型是通过将模型之间进行分割而实现的,所以当操作订单的时候,只需根据需要操作订单、订单明细就可以。而一般的三层设计Controller、Service、Dao就可以支撑起来订单的模型设计。由于分割的模型数据不必组装成领域模型对象,所以在Dao查询完毕数据后,可以直接返回给Service进行使用,反之亦然。系统的复杂性大大降低。
贫血模型简单直接,可在经典三层中直接实现。
充血模型需要具备更强的设计能力
由于充血模型是对领域模型的直接表现,所以领域模型设计的优劣会直接影响到系统的整体性能与扩展性。这就要求开发人员有更强的对象分析、对象设计能力。同时由于充血模型中需要对不同领域中的数据进行聚合,所以可能需要在团队之间提出数据查询需求,也就需要有更强的团队协作能力。
而相反的,贫血模型所有业务处理都在service中进行操作,且对模型进行了分割,所以对于数据的外部依赖就更少,层级也更少。大部分逻辑都是直接Dao查询数据库后返回,对于开发人员的能力要求就更小。
贫血模型可面向步骤编程
在面对长串的复杂业务场景时,我们可能更倾向于将业务拆解为多个串联的步骤然后独立执行。而在使用贫血模型的情况下可以通过编写多个Service直接进行面向步骤编程。每个Service可以处理对象中的部分数据,在通过多个Service处理后得到最终结果。
尽管充血模型也可以在方法中进行拆分,但是并不如贫血模型来的直接。
贫血模型AND充血模型
尽管上文中对充血模型与贫血模型进行了直接的区分,但是这两种设计并非二元论的。简单来说,我们可以根据充血模型与贫血模型的特点,选取我们需要的部分进行使用。例如:
- 将需要封装的业务逻辑到领域对象中,按照充血模型去设计
- 将不需要封装的业务逻辑放到Service中,按照贫血模型去设计
那么针对上文中的订单模型来说设计就变成了:
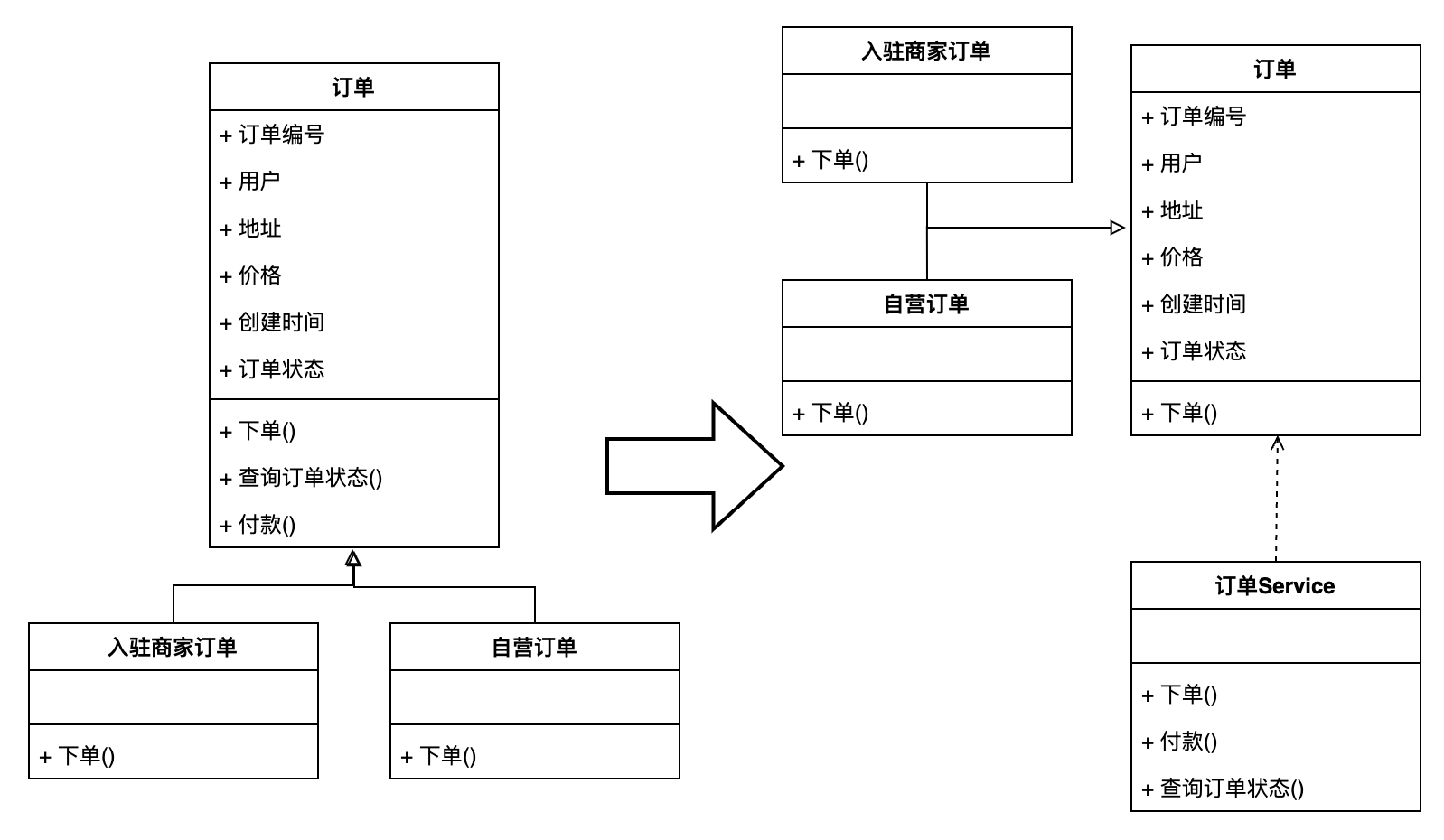
也就是仅将需要封装的下单逻辑放到了“入驻商家订单”、“自营订单”中,而付款、查询订单状态逻辑则仍然放到Service进行主要处理。
事实上,需要封装的这个概念也是比较模糊的,但是基本上可以参考:
- 存在继承、多态关系:例如订单与自营订单
- 需要编码转换:例如根据数值返回对应的枚举对象
- 需要体现出必要领域关联性:例如订单与订单明细的关系。
最后
尽管经过了合理的分析后,得到的结论是应该根据特性进行贫血和充血模型的混用。但是在实际企业中,如何评判哪些方法可以放到模型中的这个标准是相对模糊的。也就是说更多的还是需要依靠架构设计、开发的个人能力、代码review,而上述三个都对小团队、年轻团队不是很友好。所以我认为如果为了提高下限,则使用贫血模型更加稳妥。