作者丨Soledad Galli
译者丨赵青窕
策划丨孙淑娟、梁策
你可能曾试过在网上检索“特征选择”,随之找到海量文章,这些文章把特征选择概括为三种,即“过滤法(Filter Methods)”,“包装法 (Wrapper Methods)”和“嵌入法(Embedded Methods)”。
在“过滤法(Filter Methods)”中,我们使用统计测试的方法,这种方法是根据特征分布来进行特征选择。该方法计算速度非常快,但在实践中,它并不能为模型选取较佳的特征。此外,当我们有大量数据集时,统计测试的 p 值往往非常小,放大为分布中并不重要的显著微小差异。
“包装法 (Wrapper Methods)”类别包括贪婪算法,它将基于向前、向后或穷举搜索尝试所有可能的特征组合。对于每个特征组合,通常使用交叉验证(cross-validation)训练出机器学习模型,准确测定模型性能。因此,包装法在计算上成本高昂,通常很难实现。
另一方面,“嵌入法(Embedded Methods)”训练出单个机器学习模型,并根据该模型返回的特征重要性来进行特征选择。它们在实践中非常出色,计算速度也更快。但该方法主要有三个缺点:
- 我们不能从所有的机器学习模型中得出特征重要值。
- 共线性会影响线性模型返回的系数值,或基于决策树算法返回的重要值,从而可能掩盖其真正的重要性。
- 基于决策树的算法在非常大的特征空间中可能无法很好地执行,因此,其重要值可能不可靠。
过滤法(Filter Methods)比较晦涩,在实践中不常用;包装法 (Wrapper Methods) 在计算上昂贵,通常不可能实现;嵌入法(Embedded Methods)并不适用于所有场景或所有机器学习模型。那么,对此我们还能如何选择预测性特征呢?
好在为监督学习选择特征还有更多方法。我在这篇文章中将详细介绍其中三种基于模型性能的选择特征算法,因为同时具备了包装法和嵌入法的特征,它们通常被称为“混合法(Hybrid Methods)”,其中一些因为需要依赖多个训练的机器学习模型有点像包装法。一些选择流程依赖特征的重要性,有点像嵌入法。
特征选择替代方法✦
这些方法已在行业或数据科学竞赛中成功应用,并且已经提供了方法,用来训练出特定的机器模型,从而进行特征预测。
在整篇文章中,我将展示其中一些特性选择方法的逻辑和流程,并展示如何使用开源库 Feature-engine 在 Python 中实现它们。
我们将讨论以下三种特征选择方法:
- 特征重排
- 特征性能
- 目标平均性能
特征重排✦
特征重排 (Feature shuffle),即按照特征重要性的排列 (permutation Feature importance),是指针对某单个特性,按照模型性能得分的降序方式进行重新排列。改变特征值的顺序(在数据集的各个行中)会改变特征和目标之间的原始关系,因此模型性能分数的降序方向表明了模型对该特征的依赖程度。
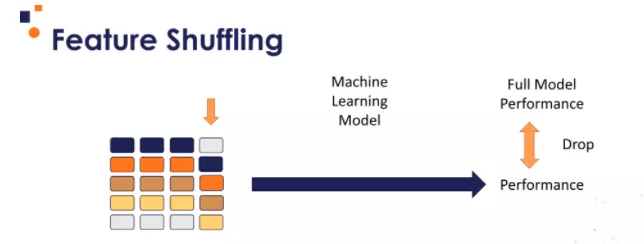
具体的流程如下:
- 训练机器学习模型并确定其性能。
- 选择一个特征进行重新排序。
- 用步骤 1 中训练的模型进行预测,并得出步骤 2 种所选特征的性能值。
- 如果在步骤 3 种得出的特征性能值低于阈值,则保留该特征,否则删除该特征。
- 从第 2 步开始重复操作,直到检查完所有的特征。
通过变换特征进行选择有几个优点。首先,我们只需要训练一个机器学习模型,随后利用该机器学习模型对特征值进行重排;其次,我们可以选择有监督机器学习模型特征。第三,可以利用开放源码来实现这个选择过程,在接下来的段落中将介绍其具体方法。
优点:
- 只训练一个机器学习模型,所以速度很快。
- 适用于任何有监督的机器学习模型。
- 可以使用 Python 开源库 Feature-engine。
缺点是,如果两个特征是相关的,当其中一个特征被打乱时,机器学习模型仍然可以通过其相关变量获取到相应的信息,这可能会导致这两个相关特征的重要性值都偏低,即使它们实际上可能很重要。此外,为了选择特征,我们需要定义一个重要阈值,低于该阈值特征将被删除。阈值越高,选择的特征就越少。最后,特征重排引入了一个随机性元素,所以对于重要性值接近阈值的特征,不同的算法运行可能会返回不同的特征子集。
注意事项:
- 相关性的特征可能会影响特征重要性的解释。
- 用户需要定义一个阈值。
- 随机性的因素使得选择过程出现不确定性。
考虑到这一点,特征重排突出了那些直接影响模型性能的变量,是一个很好的特征选择方法,我们可以用 Scikit-learn 手工推导排列重要性,然后选择那些重要性显示高于某个阈值的变量。或者,我们可以使用 Feature-engine 来自动化地实现整个过程。
Python 实现✦
让我们看看如何使用 Feature -engine 通过特征重排来进行选择。我们选取 Scikit-learn 附带的糖尿病数据集。首先,加载数据:
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from feature_engine.selection import SelectByShuffling
# load dataset
diabetes_X, diabetes_y = load_diabetes(return_X_y=True)
X = pd.DataFrame(diabetes_X)
y = pd.DataFrame(diabetes_y)
接着,建立感兴趣的机器学习模型:
# initialize linear regression estimator
linear_model = LinearRegression()
我们将基于 scoring = ‘’r2“的下降,使用 3 折交叉验证(3 fold cross-validation)来进行特征选择:
# initialize the feature selector
tr = SelectByShuffling(estimator=linear_model, scoring="r2", cv=3)
转换器使用 fit() 方法找到重要的变量(即那些在重排时导致 r2 下降的变量)。默认情况下,如果性能下降大于所有特征导致的平均下降,则选择该特性。
# fit transformer
tr.fit(X, y)
使用 transform() 方法,从数据集中删除未选择的特征:
Xt = tr.transform(X)
我们可以通过转换器的一个属性来查询各个特征的重要性:
tr.performance_drifts_
{0: -0.02368121940502793,
1: 0.017909161264480666,
2: 0.18565460365508413,
3: 0.07655405817715671,
4: 0.4327180164470878,
5: 0.16394693824418372,
6: -0.012876023845921625,
7: 0.01048781540981647,
8: 0.3921465005640224,
9: -0.01427065640301245}
我们可以通过另一个属性来访问将被删除的特征名称:
tr.features_to_drop_
[0, 1, 3, 6, 7, 9]
就这样简单操作,我们在 Xt 中有一个缩减后的数据帧。
特征性能✦
确定一个特征重要性的一种直接方法是只用该特征训练机器学习模型。在这种情况下,特征的“重要性”是由模型的性能评分给出的。也就是说,在单一特征训练出来模型的对目标预测的效果如何。低性能评分表示特征较弱或无法预测。
流程如下:
- 为每个特征训练一个机器学习模型。
- 对每个模型进行目标预测并确定模型性能。
- 选择性能指标高于阈值的特征。
在这个选择过程中,我们为每个特征训练一个机器学习模型。该模型使用单个特征来预测目标变量。然后,采用交叉验证计算模型的性能,最后选择性能超过设定阈值的特征。
一方面,因为需要训练的模型个数,同数据集中特征的个数多,这种方法的计算成本更高。另一方面,在单一特征训练的模型速率往往相当快。
使用这种方法,我们可以针对感兴趣特征学习模型,因为其重要性是由性能指标决定的。缺点是,我们需要为特性选择提供一个阈值。阈值越高,选择特征组越少。有些阈值是相当直观的,例如,如果性能指标是 roc-auc,我们可以选择性能高于 0.5 的特性。对于其他指标,比如准确性,我们并不清楚阈值设置为多少是比较合理的。
优点:
- 适用于任何有监督的机器学习模型。
- 可以单独地探索特征,从而避免相关性问题。
- 可以使用 Python 开源项目 Feature-engine。
注意事项:
- 为每个特征训练一个模型的计算成本很高。
- 用户需要自定义阈值。
- 无法识别相关联的特征。
我们可以利用 Feature-engine 实现单特征性能的选择。
Python 实现✦
加载 Scikit-learn 中的糖尿病数据集:
mport pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from feature_engine.selection import SelectBySingleFeaturePerformance
# load dataset
diabetes_X, diabetes_y = load_diabetes(return_X_y=True)
X = pd.DataFrame(diabetes_X)
y = pd.DataFrame(diabetes_y)
利用线性回归和 3 倍交叉验证,选择 r2 > 0.01 的特征。
# initialize the feature selector
sel = SelectBySingleFeaturePerformance(
estimator=LinearRegression(), scoring="r2", cv=3, threshold=0.01)
转换器使用 fit() 方法对每个特征拟合一个模型,计算其性能,并选择重要的特征。
# fit transformer
sel.fit(X, y)
我们可以查看将被丢弃的特征:
我们可以查看将被丢弃的特征:
sel.features_to_drop_
[1]
我们也可以检查每个特征的性能:
sel.feature_performance_
{0: 0.029231969375784466,
1: -0.003738551760264386,
2: 0.336620809987693,
3: 0.19219056680145055,
4: 0.037115559827549806,
5: 0.017854228256932614,
6: 0.15153886177526896,
7: 0.17721609966501747,
8: 0.3149462084418813,
9: 0.13876602125792703}
通过 transform() 方法,我们从数据集中移除特征:
# drop variables
Xt = sel.transform(X)
这样我们就得到一个缩减后的数据集。
目标平均性能✦
我现在要讨论的选择方法是 Miller 和他的同事在 KDD 2009 数据科学竞赛中引入的。作者没有为该技术指定任何名称,但由于它使用每组数据的平均目标值作为预测指标,所以我喜欢将这种技术称为“目标平均性能选择(Target mean performance)”。
这种选择方法也会为每个特性分配一个“重要性”值。这个重要性值是根据性能指标来决定的。有趣的是,该模型不训练任何机器学习模型。相反,它使用一个非常简单的指标值来预测。
简而言之,该选择方法是使用每个类别或每个区间(如果变量是连续的)的平均目标值作为预测指标。通过这个预测,可以得到一个性能指标,如 r2、准确性或任何其他根据事实评估预测的指标。
那这种选择方法到底是如何工作的?
针对类别变量:
- 将数据帧拆分为训练集和测试集。
- 对于每个类别项来说,计算每一项的平均目标值(使用训练集)。
- 将测试集中的每一个类别项替换为该类别的目标平均值。
- 使用编码的特征和目标值(在测试集中)来计算性能指标。
- 选择性能高于阈值的特征。
对于每一个类别项,根据训练集为每个类别确定其目标的平均值。然后,将测试集中的每一个类别项替换为刚习得的目标平均值,这些值被用来确定性能指标。
对于连续变量,其过程同类别变量的情况相似:
- 将数据帧拆分为训练集和测试集。
- 对于每个连续的特征,它将值排序成离散的区间(该步骤使用训练集)。
- 确定每个区间的平均目标值(使用训练集)。
- 将测试集中的变量按照步骤 2 中确当的区间进行分组排序。
- 使用相应区间的目标均值替换测试集对应区间的值。
- 针对测试集,使用特定的编码特征和目标来计算之间的性能指标。
- 选择性能高于阈值的特征。
对于连续变量,作者首先将所有项分成不同的组,这个过程也被称为离散化。他们使用 1% 的分位数,然后计算训练集中每组的目标平均值,并使用相应区间的目标均值替换测试集对应区间的值,并进行性能的评估。
这种特征选择方法非常简单;它会计算每个区间(类别或间隔)的平均值,并利用这些值来获得性能指标。虽然简单,但优点不少:
首先,它不需要训练机器学习模型,所以计算起来非常快。其次,它能捕捉与目标的非线性关系。第三,它适用于分类变量,不像大多数现有的选择算法。它也适用对离群值的处理,因为这些极端数值将被分配到一个极端组中。根据作者的描述,该方法可以为分类或者数值变量提供比较客观的性能。而且,它与模型无关。从理论上讲,按这种操作选择的特征应该适用于任何机器学习模型。
优点:
- 因为不需要训练机器学习模型,速度比较快。
- 适用于分类变量和数值变量。
- 可以处理离群值的情况。
- 可以捕捉特征和目标之间的非线性关系。
- 不受模型的限制。
这种选择方法也存在一些局限性。首先,对于连续变量,用户需要定义一个任意数量的区间来对数值进行排序。这给倾斜变量带来了一个问题,其中大多数倾斜变量数据可能只属于同一组。第二,不频繁的标签分类变量可能会导致不可靠的结果,因为对这些类别的数据很少,这种类别的平均目标值是不可靠的。在极端情况下,如果训练集中没有某类别,那么我们将无法得到一个平均目标值来计算性能。
注意事项:
- 它需要为倾斜变量调整区间数。
- 稀有类别会提供不可靠的性能指标,或者无法适用该方法。
考虑到这些因素,我们可以使用 Feature-engine 选择基于目标平均性能的变量。
Python 实现✦
我们将使用这种方法从泰坦尼克数据集内选择变量,该数据集混合了数值变量和分类变量。加载数据时,我将进行一些预处理以方便演示,然后将其分为训练和测试集。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from feature_engine.selection import SelectByTargetMeanPerformance
# load data
data = pd.read_csv('https://www.openml.org/data/get_csv/16826755/phpMYEkMl')
# extract cabin letter
data['cabin'] = data['cabin'].str[0]
# replace infrequent cabins by N
data['cabin'] = np.where(data['cabin'].isin(['T', 'G']), 'N', data['cabin'])
# cap maximum values
data['parch'] = np.where(data['parch']>3,3,data['parch'])
data['sibsp'] = np.where(data['sibsp']>3,3,data['sibsp'])
# cast variables as object to treat as categorical
data[['pclass','sibsp','parch']] = data[['pclass','sibsp','parch']].astype('O')
# separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['survived'], axis=1),
data['survived'],
test_size=0.3,
random_state=0)
我们将基于 roc-auc,使用 2 折交叉验证进行特征选择。首先要注意的是 Feature-engine 允许我们使用交叉验证,相对于作者描述的原始方法来说,这是一种改进。
Feature-engine 还允许我们决定如何确定数值变量的间隔。我们可以选择等频或等宽的间隔。作者使用了 1% 的分位数,这适用于具有合理值分布的连续变量,但通常不适用于倾斜变量。在本示例中,我们将把数值变量分成相等的频率间隔。最后,我们希望选择 roc-auc 大于 0.6 的特征。
# Feature-engine automates the selection of
# categorical and numerical variables
sel = SelectByTargetMeanPerformance(
variables=None,
scoring="roc_auc_score",
threshold=0.6,
bins=3,
strategy="equal_frequency",
cv=2,# cross validation
random_state=1, # seed for reproducibility
)
使用 fit() 方法,转换器可以:
- 用目标平均值替换类别
- 将数值变量按相同的频率分类
- 按目标平均值来替换区间中的变量
- 使用目标均值编码变量返回 roc-auc
- 选择 roc-auc > 0.6 的特性
我们可以计算每个特性的 ROC-AUC:
sel.feature_performance_
{'pclass': 0.6802934787230475,
'sex': 0.7491365252482871,
'age': 0.5345141148737766,
'sibsp': 0.5720480307315783,
'parch': 0.5243557188989476,
'fare': 0.6600883312700917,
'cabin': 0.6379782658154696,
'embarked': 0.5672382248783936}
我们可以从数据中找到将被删除的特征:
sel.features_to_drop_
['age', 'sibsp', 'parch', 'embarked']
通过 transform() 方法,我们可以从数据集中删除特征:
# remove features
X_train = sel.transform(X_train)
X_test = sel.transform(X_test)
到此为止,现在我们有了精简版的训练集和测试集。
总结✦
要在 Python 中实现过滤法、包装法、嵌入法和混合特征选择方法,请查看 Scikit-learn、MLXtend 和 Feature-engine 中的选择模块。这些库附带了大量文档,可以帮助您理解基础方法论。
译者介绍✦
赵青窕,51CTO 社区编辑,从事多年驱动开发。研究兴趣包含安全 OS 和网络安全领域,曾获得陕西赛区数学建模奖,发表过网络相关专利。