机器学习,俗称「炼丹」。
作为AI「黑魔法」的一种,再加点「玄学」又会如何?
最近,有位来自苏州大学的博士生就做了个「随机撞运」的项目。
这位老哥表示,机器学习要用的随机种子会影响最终的实验结果,那不如搞个增运加持吧。
开源项目:https://github.com/Spico197/random-luck
这可真是「东海西海心理攸同,南学北学道术未裂」。
生成数字有两种方法:一种是简单的填个生日日期,另一种是计算AI实验开始时间的天干地支数字,返回一个幸运数字,拿这个数字作为随机种子跑实验。
效果大概是这样:
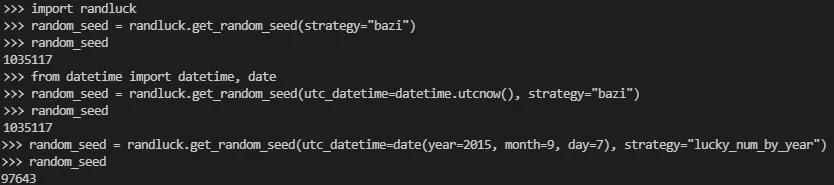
代码如下:
#installation
pip install randluck -i https://pypi.org/simple
#usage
import randluck
random_seed = randluck.get_random_seed(strategy="bazi")
print(random_seed)
from datetime import dateime, date
random_seed = randluck.get_random_seed(utc_datetime=datetime.utcnow(), strategy="bazi")
print(random_seed)
random_seed = randluck.get_random_seed(utc_datetime=date(year=2015, month=9, day=7), strategy="lucky_num_by_year")
print(random_seed)
虽然作者说这只是为了好玩,丝毫没有想附会科学证明或解释。
不过广受调参所苦的码农和学生们,在这上面寄托点美好愿望也是可以的……吧?

作者朱桐目前正在苏州大学攻读博士学位,此前在贵州大学获得学士学位。
研究方向为物联网设计,关系抽取和事件抽取。

曾在2020年获得CCKS「金融文件的事件抽取」任务团队第一名,2021年获得语言与智能竞赛三等奖(前5名团队)以及CCKS事件和关系抽取任务技术创新奖。
天干地支
虽然现在富具科学精神的码农们少有真正信天干地支是实在货色的,但并不代表热衷使用干支概念的时代人群也这么看。
按照古文字考据界的顶会作者、大宗师郭沫若的考证,古中国初现于公元前13-12世纪的「十二地支」、「太岁纪年」,来源于古西亚初现于公元前45-23世纪、成熟于公元前13世纪的「黄道十二宫」系统。
对应「十二地支」的十二个「太岁年名」,就是「十二宫」的古苏美尔语和阿卡德语单词读音转写而成。「十二宫」在古西亚泥板上的星座符号,与之后「十二地支」的甲骨文图像,也近乎完全一致。
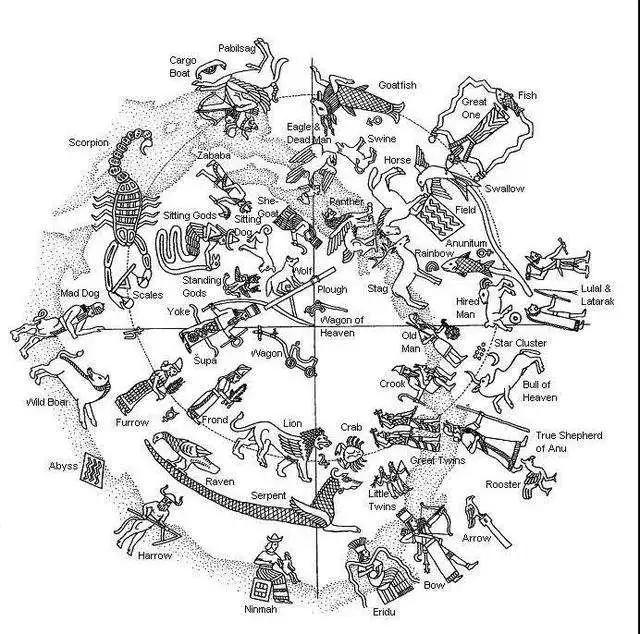
古西亚的星座图
也就是说,天干地支系统和十二星座系统的算命技术其实有差相仿佛的起源。就像CNN现在也不分国界了一样,大家都要卷一卷……
而几千年前的古西亚人和古中国人看待星宫/干支的眼光,和当代AI从业者看LeCun的差不多:都是前沿科技,就算我不懂,但是大牛说的一定很厉害。
所以拿模拟器吐个干支出来,算是上古前沿技术和当代前沿技术合流了。
毕竟科幻小说家海因莱茵有讲过:「你觉得好厉害的超自然现象,都是创造者觉得好麻烦的精密工程现象。」
随机种子
从概念上讲,种子值是用来生成随机数发生器的。而且,每次使用相同的种子值,都会得到相同的随机值。
也就是说,随机种子可以确保任何重新运行这段代码的人都会得到完全相同的输出。
通常在两个任务中会用到:
1. 将数据分割成训练/验证/测试集:随机种子确保每次运行代码时都以相同的方式分割数据
2. 模型训练:随机森林和梯度提升等算法是非确定性的(对于一个给定的输入,输出并不总是相同的),因此需要一个随机种子参数以获得可重复的结果
除了可重复性之外,随机种子对于具有参考性的结果也很重要。比如测试一个算法的多个版本,重要的是所有版本都使用相同的数据,并且尽可能的相似(除了需要测试的参数)。
尽管随机种子很重要,但它的设置往往不费吹灰之力。比如使用工作时的日期(2020年3月1日,种子就是20200301)。
有些人每次都使用同一个种子,而有些人则随机生成。
举个例子,当使用Scikit-learn训练机器学习模型时,从sklearn.model_selection模块中导入的函数train_test_split使用随机状态等参数来获取随机种子的输入。
from sklearn import datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
random_state=42这个参数在每次运行上述代码时都将随机种子设置为相同的值,也就会得到相同的验证集(X_test,y_test)。
AI写你的每日星盘
当然,AI作妖这么浪漫的点子,不会仅限于中国码农。用AI写星盘的点子,美国码农也有过。
2017年,VICE杂志就有报道过,三个兼具码力、产品开发力、和星座学爱好的纽约码农,苦于当时市面上的「智能星盘」、「自动星盘」app只会复读录入的苏珊米勒们1990年代的作品,自己做了个「星盘算法」。
基本机制倒不复杂。开发者首先录入各种天体运动在星相学上的对应算命阐释,同时开发接口自动扒来NASA公开的天体追踪数据。然后开发算法将这些数据的计算结果对应起来,同时开发自然语言生成器,让算法结果以「你的每日星盘」文章出现。

这些星座学爱好者还有非常合格的产品经理能力,「星盘算法」app特别强调加好友的社交功能。不仅可以对照各人的星盘表,还能生成各人之间的星相契合性。
各种天体与十二黄道星座互动的「入宫」,对各人和各人好友的命运影响和互动,在app上也有呈现。加的好友越多,呈现的结果就越具体。
「星盘算法」的开发者很开心地对VICE说:「我们当然知道这不是科学算命。但这是一种有趣的故事阐述方式,既基于古神话学、又基于当代人性格,很好玩的。」
不过不仅浪漫是普世的,理科生靠实力单身的性格好像也是普世的。2020年就有码农去推特上采样星盘推特回复的表情图频率作为原始数据,写了个项目来跑统计。以回复者的准确与否表态,来验证星座学是否真能有效算命……
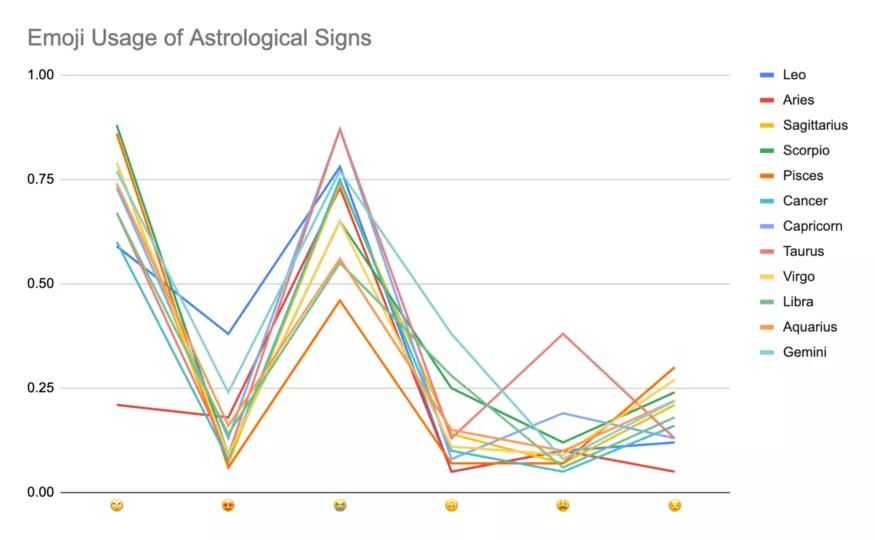
废话,当然不能了,真是不解风情,做这个项目的人一定不会有女朋友。