1.序篇-先说结论
本文主要记录小伙伴萌在使用 DataStream API 实现事件时间窗口类应用时会遇到的窗口不触发问题的坑以及其排查过程。
博主希望你在看完本文后一定要养成这个编程习惯:使用 DataStream API 实现 Flink 任务时,Watermark Assigner 能靠近 Source 节点就靠近 Source 节点,尽量前置。
要想问为啥,接着往下看!!!
我从以下几个章节说明上述的问题以及为什么这样建议,希望能抛砖引玉,带给大家一些启发。
- ⭐ 踩坑场景篇-这个坑是啥样的
- ⭐ 问题排查篇-坑的排查过程
- ⭐ 问题原理解析篇-导致问题的机制是什么
- ⭐ 避坑篇-如何避免这种问题
- ⭐ 总结篇
2.踩坑场景篇-这个坑是啥样的
2.1.需求场景
首先介绍一下这个坑对应的一个需求场景以及第一版本的实现代码。
需求:在电商平台中,需要根据网页在线用户的心跳日志(每 30s 上报一次用户心跳日志)计算当前这一分钟在购物车页面(Shopping-Cart)停留的在线人数。
数据源:每 30s 上报一次的用户心跳日志(user_id、page、time 三个字段分别对应 用户 id、用户所在页面、日志上报时间)
数据处理:先过滤出购物车按照时间戳对用户心跳日志进行滚动窗口(Tumble)聚合计算
数据汇:每分钟聚合的结果数据(uv、time两个字段分别对应 购物车页面的当前这一分钟的同时在线人数、当前这一分钟的时间戳)
Flink DataStream API 具体实现代码如下:
public class WatermarkTest {
public static void main(String[] args) throws Exception {
// 获取到 Flink 环境,博主自己封装的接口 FlinkEnv
FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
// 设置并发度
flinkEnv.env().setParallelism(100);
flinkEnv.env()
// 数据源:上报的日志
.addSource(xxx)
// 过滤出 购物车页面(Shopping-Cart)的数据
.filter(new FilterFunction<SourceModel>() {
@Override
public boolean filter(SourceModel value) throws Exception {
return value.getPage().equals("Shopping-Cart");
}
})
// 分配 Watermark
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SourceModel>(Time.minutes(1)) {
@Override
public long extractTimestamp(SourceModel element) {
return element.getTime();
}
})
// 为了进行合并计算,shuffle 到一个算子中,所以此处返回结果固定为 0
.keyBy(new KeySelector<SourceModel, Long>() {
@Override
public Long getKey(SourceModel value) throws Exception {
return 0L;
}
})
// 开一分钟的滚动时间时间窗口
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
// 计算 uv 的处理逻辑
.process(new ProcessWindowFunction<SourceModel, SinkModel, Long, TimeWindow>() {
@Override
public void process(Long aLong, Context context, Iterable<SourceModel> elements,
Collector<SinkModel> out) throws Exception {
long windowStart = context.window().getStart();
Set<Long> s = new HashSet<>();
elements.forEach(new Consumer<SourceModel>() {
@Override
public void accept(SourceModel sourceModel) {
s.add(sourceModel.userId);
}
});
out.collect(
SinkModel
.builder()
.uv(s.size())
.time(windowStart)
.build()
);
}
})
// 输出
.addSink(xxx);
}
// 输入数据 Model
@Data
@Builder
private static class SourceModel {
private long userId;
private String page;
private long time;
}
// 输出数据 Model
@Data
@Builder
private static class SinkModel {
private long uv;
private long time;
}
}
2.2.问题场景
当我们把这个任务部署到集群环境运行时,却发现一直没有数据产出,但是输入数据(用户心跳日志)是一直有大量数据过来的。
3.问题排查篇-坑的排查过程
通过 Flink web ui 定位了下发现每个算子的表现如下:
- ⭐ Source 算子:一直能够消费到数据,而且从 web ui 的输入输出流量看数据量非常大
- ⭐ Filter 算子:Filter 算子有输入也有输出,输入非常大,但是输出数据极少(这里是由于业务原因导致的,从购物的业务上来说只有非常少一部分的人会在购物车页面停留)
- ⭐ 滚动窗口算子:有极少的输入数据,但是一直没有输出,并且从 web ui 查看算子的 Watermark 也是没有的
从这里开始问题就清晰了。
至少从 Flink web ui 上来看是由于窗口算子没有 Watermark 导致的窗口数据没有触发计算。
这时的第一个猜想就是:窗口算子单并发上面的 Watermark 没有对齐导致的!!!
接下看一下这个猜想的整体验证过程:
- ⭐ 由于我们的 Watermark Assigner 是写在 Filter 算子之后的,因此 Watermark 的生成也是基于 Filter 算子之后的数据的。所以想要定位是不是由于上述猜想导致的,我们就需要估算 Filter 算子产出的数据量来验证。
- ⭐ 经过验证,发现 Filter 算子之后产出的数据,每一分钟总数据量产出到下游算子的不到 60 条。也就是说在我们 100 并发的任务上面,每一分钟最多只有 60 个并发的 Filter 算子会产出数据到下游滚动窗口算子,剩下至少的 40 个并发的算子没有发任何数据到下游滚动窗口算子。
- ⭐ 最终,对于下游的滚动窗口算子来说,就没法做到 Watermark 对齐!因此窗口无法触发。
问题原因找到。
4.问题原理解析篇-导致问题的机制是什么
想要理解 Watermark 对齐 到底是怎么一回事,我们首先要看一下 Flink 中的 Watermark 传输及计算机制:
- Watermark 传输方式:广播。这里的广播是指 上游算子的一个并发 会往 能够连接到的下游算子的所有并发 广播,这与上下游算子并发之间的 Shuffle 机制有关。这里的广播不是说 Flink 提供的 BroadCast 编程 API!!!
举例:如果一个任务 100 并发,上下游算子之间 Shuffle 策略是 Forward,那么上游算子的一个并发的 Watermark 会只往下游算子的连接到的那一个并发发送 Watermark;如果策略是 Hash\Rebalance,则上游算子的一个并发的 Watermark 会往下游算子的所有并发上发送 Watermark。
- Watermark 计算方式:下游算子的一个并发接受到上游算子并发的 Watermark 之后下游算子当前并发的 Watermark 计算方式(这里的上下游是指有 Channel 连接的),计算公式:
下游算子并发 Watermark = min(上游算子并发 1 发送的 Watermark,上游算子并发 2 发送的 Watermark......)
即
下游算子并发 Watermark = 所有上游算子并发发到下游算子 Watermark 的最小值。
- Watermark 对齐:下游算子并发的 Watermark 依赖上游算子并发的 Watermark 差异很大时,这就是 Watermark 没有对齐,举例:上有算子一个并发传输的 Watermark 是 23:59 分,另一个并发传输的 Watermark 是 23:00 分,中间查了 59 分钟,这种情况一般都是异常情况,所以叫做没有对齐。反之如果 Watermark 差异很小,则叫做Watermark 对齐。
再来一张图看看 Watermark 的传输过程,加深理解:
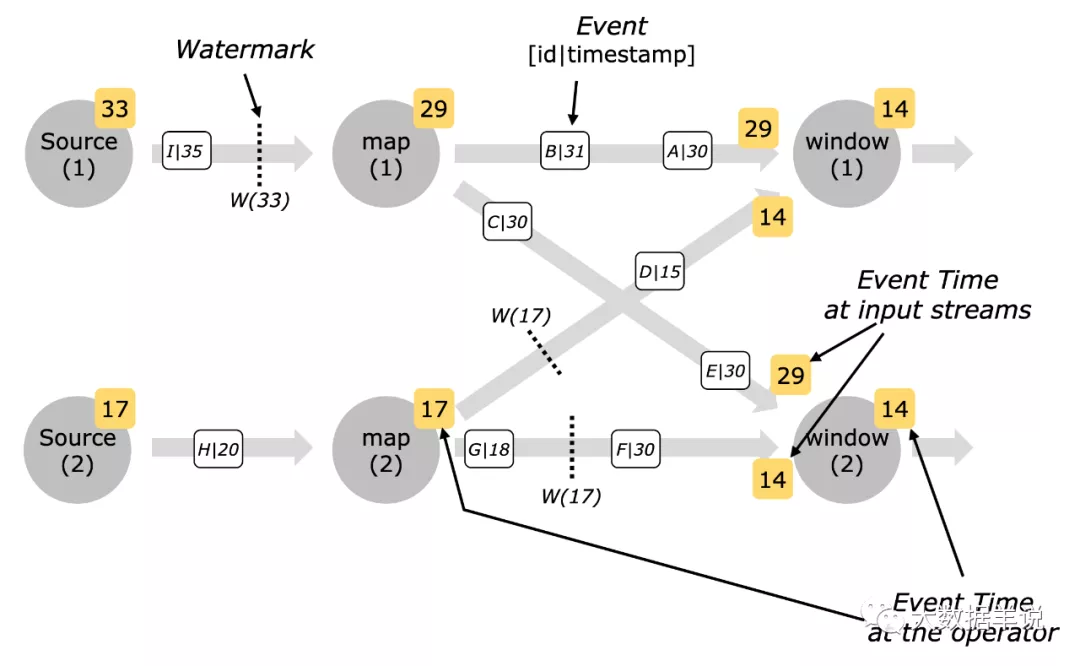
Watermark 传播
回到上述案例中,一分钟上游算子只有 60 个并发有数据,发送了 Watermark 到下游窗口算子,其余 40 个毛都没有。
所以下游窗口算子的 Watermark 就没有,因此窗口也就不触发了。
5.避坑篇-如何避免这种问题
在上述场景中,其实问题的根本原因就是数据经过(购物车页)条件过滤之后,数据量变得非常少了。
Watermark Assigner 从极少量的数据中去生成极少量 Watermark,有 40 个并发都没有 Watermark 生成,下游算子就出现了Watermark 对不齐 的情景。
那么解决方案也很简单,就是多生成一些 Watermark,确保:
虽然 Filter 之后的数据很少,Filter 算子处理过后,每个并发上面都有足够的 Watermark 来传递到下游窗口算子,来持续的触发窗口的计算和结果产出。
具体解决方案:将 Watermark Assigner 重写到 Source 算子之后,Filter 算子之前。代码如下:
public class WatermarkTest {
public static void main(String[] args) throws Exception {
// 获取到 Flink 环境,博主自己封装的接口 FlinkEnv
FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
flinkEnv.env().setParallelism(100);
flinkEnv.env()
// 数据源
.addSource(xxx)
// 分配 Watermark,移到 Filter 之前
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SourceModel>(Time.minutes(1)) {
@Override
public long extractTimestamp(SourceModel element) {
return element.getTime();
}
})
// 过滤出 购物车页面(Shopping-Cart)的数据
.filter(new FilterFunction<SourceModel>() {
@Override
public boolean filter(SourceModel value) throws Exception {
return value.getPage().equals("Shopping-Cart");
}
})
// 为了 shuffle 到一个算子中进行合并计算,所以返回结果 key 固定为 0
.keyBy(new KeySelector<SourceModel, Long>() {
@Override
public Long getKey(SourceModel value) throws Exception {
return 0L;
}
})
// 开一分钟的滚动时间时间窗口
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
// 计算 uv 的处理逻辑
.process(new ProcessWindowFunction<SourceModel, SinkModel, Long, TimeWindow>() {
@Override
public void process(Long aLong, Context context, Iterable<SourceModel> elements,
Collector<SinkModel> out) throws Exception {
long windowStart = context.window().getStart();
Set<Long> s = new HashSet<>();
elements.forEach(new Consumer<SourceModel>() {
@Override
public void accept(SourceModel sourceModel) {
s.add(sourceModel.userId);
}
});
out.collect(
SinkModel
.builder()
.uv(s.size())
.time(windowStart)
.build()
);
}
})
// 输出
.addSink(xxx);
}
// 输入数据 Model
@Data
@Builder
private static class SourceModel {
private long userId;
private String page;
private long time;
}
// 输出数据 Model
@Data
@Builder
private static class SinkModel {
private long uv;
private long time;
}
}
解决方案的原理:在上述业务场景中,Source 的数据是非常多的,我们可以利用大量的 Source 数据,从而使 Watermark Assigner 能够持续不断的产生 Watermark 传输到下游。
虽然经过 Filter 算子之后,到下游窗口算子的数据量很少,但是 Watermark 不会被 Filter 算子的过滤,大量的 Watermark 依然能够正常传输到窗口算子,使得 Watermark 对齐,从而保障窗口算子的持续触发和结果输出。
解决方案虽好,但是有极低几率会产生乱序丢数问题::举例,Watermark 是在 Source 算子之后产生的,有可能一条 23:50:50 的 购物车页日志的数据在 23:52:00 的 网站主页面 日志数据后到达,那么 Watermark 已经升高到 23:51:00 秒了,23:50 分的窗口已经被触发了,从而这条 23:50:50 的 购物车页 数据就被窗口算子丢弃了。
6.总结篇
本文主要记录小伙伴萌在使用 DataStream API 由于将 Watermark Assigner 设置的太靠后,导致的 Watermark 无法对齐,从而事件时间窗口不触发的问题。
博主建议的编程习惯:使用 DataStream API 实现 Flink 任务时,Watermark Assigner 能靠近 Source 节点就靠近 Source 节点,能前置尽量前置。