














作者丨徐杰承
近日,曾推出过轰动一时的 AlphaGo 围棋机器人的 DeepMind 再次放出大招,公开发布了一款名为 AlphaCode 的代码生成系统。
据 DeepMind 介绍,AlphaCode 在正式亮相前,就已通过知名编程竞赛网站 Codeforces 所举办的 10 场算法竞赛检测了自身实力。在这 10 场比赛中 AlphaCode 成功击败了几乎一半的参赛选手,最终成绩排名 54%。

论文链接:https://storage.googleapis.com/deepmind-media/AlphaCode/competition_level_code_generation_with_alphacode.pdf
有 AI 研究科学家在社交媒体上表示,AlphaCode 达到人类水平还需要几年时间,它在 codeforce 上的排名是有限制的,如许多参与者是高中生或大学生;还有就是 AlphaCode 生成的绝大多数程序都是错误的,正是使用示例测试进行过滤才使得 AlphaCode 实际解决了某些问题。
也有研究人员表示,这像是 AlphaStar 大力出奇迹的结果。
当然,这已远非人工智能与人类智能的第一次交手。截止目前,在人工智能技术的发展历程中,已有众多 AlphaCode 的“老前辈”在与不同领域人类顶级选手的对阵中取得了斐然成绩,而它们的每次胜利,都对人工智能技术的发展产生了深远影响。
Deep Blue✦

在人机交锋的历史中,AI 的首胜发生在 1997 年。IBM 公司的 Deep Blue 超级计算机以 3.5:2.5 战胜了当时世界排名第一的国际象棋大师卡斯帕罗夫。
技术方面,Deep Blue 采用混合决策,将通用超级计算机处理器与象棋加速器芯片相结合,利用 α-β 剪枝算法对棋局中的所有路数进行穷举,通过对比每一步的得分选择最佳执行策略。在算力与算法的支持下,Deep Blue 拥有每秒 2 亿步的计算速度,这对于当时的技术而言已是天花板。赛后,Deep Blue 的设计者许峰雄表示,Deep Blue 依靠硬算可以预判棋局的 12 步,而卡斯帕罗夫可以预判 10 步。
虽然从如今的角度来看,Deep Blue 能够战胜棋王更多的是依靠算力而非智能,但作为 AI 战胜人类的开端,Deep Blue 的成功为人工智能从业者带来了极大的想象空间。
Watson✦

2011 年 IBM 再度发力,Deep Blue 的同门师弟 Watson 在美国老牌智力问答节目《危险边缘》中对两位人类冠军发起了挑战并最终取胜。
与师兄 Deep Blue 相比,Watson 最大的亮点在于它的应用自然语言处理能力, IBM 称之为 Deep QA,它代表着一整套问答系统。Watson 成功的关键,在于它能靠语境来搜索答案,而不仅仅是靠关键词联想。且 Watson 所用的软件是分布式系统的整合,Hadoop 和 UIMA 通力合作,共同指引数据,使得 Watson 的各个节点协同运作。
如果说 Deep Blue 代表着人工智能在计算能力上对人类的超越,那么 Watson 则标志着人工智能在自然语言处理能力上的突破。时至今日,已有众多基于自然语言处理技术所开发的 Watson 的“后辈”出现在了我们的生活中,这其中就包括近期大火的冬奥会 AI 手语翻译官“聆语”。
AlphaGo✦

2016 年,在深度学习发展的高峰时期,AI 迎来了迄今为止最具含金量的高光时刻。号称世界围棋历史第二人的李世石与谷歌围棋人工智能程序 AlphaGo 在全球媒体的关注下展开五番棋比赛,最终 AlphaGo 以 4:1 战胜了李世石。
为解决更为复杂的围棋问题,DeepMind 放弃了 Deep Blue 中曾使用的暴力穷举法,并为 AlphaGo 设计了两种神经网络:决策网络与价值网络。其中有监督学习决策网络是一个 13 层的卷积神经网络,其主要功能是:输入当前盘面特征参数,输出下一步落子行动的概率分布,预测下一步落子位置。训练样本采用 3 千万个人类棋手产生的盘面数据,使用随机梯度下降算法进行调优,仅通过策略网络,AlphaGo 能够以 57% 的准确率预测对手的下一步落子位置。
价值网络同样是一个 13 层的卷积神经网络,与决策网络具有相同的结构,主要功能是:输入当前的盘面参数,输出下一步棋盘某处落子的估值,以此评判走子的优劣。在训练过程中,为克服训练数据相关性带来的过拟合,价值网络从决策网络产生的 3 千万局对弈中抽取样本,并组成 3 千万不相关的盘面作为训练样本,最终在测试集上获得了 0.224 的均方误差。
这两种神经网络的主要作用是降低博弈树的搜索空间规模,而在搜索算法的选择上 AlphaGo 采用了蒙特卡洛树搜索算法:先随机走子,随后通过最终数据更新走子价值。如此进行大量随机模拟,让最优方案得以自动涌现。
相较于 Deep Blue 与 Watson,AlphaGo 在数据学习能力上的突破性探索在人工智能发展的历程中具有里程碑的意义。值得一提的是,在本场比赛后,DeepMind 再次对 AlphaGo 进行了版本升级。全新的 AlphaGo Zero 摒弃了对人类比赛数据的学习,完全依靠强化学习进行自我博弈升级,仅通过 3 天训练就以 100:0 的成绩完爆了 AlphaGo。
AlphaStar✦
在 AlphaGo 取得围棋领域的制霸权后不久,AI 又再次攻克了更为复杂的 RTS 类游戏。2019 年,Google 新一代人工智能 AlphaStar 向被认为是对计算能力、反应能力和操作速度要求最高的电子游戏“星际争霸”发起挑战,分别与两位职业选手进行了十场比赛,最终以 10 比 0 的比分获得了全部比赛的胜利。
与棋类游戏不同的是,RTS 游戏存在着不完全信息博弈、长期战略规划与实时性操作等难点。正如强化学习之父 David Silver 所说:AI = DL + RL,面对这些问题 AlphaStar 选择了深度监督学习 + 强化学习的基本框架。而其中最关键的技术在于群体训练策略,AlphaStar 同时训练了三个策略集合:主代理、主暴露者、联盟暴露者。
由于游戏的复杂性过大,策略集合必须先通过深度监督学习利用人类数据完成初始化,随后主代理会利用强化学习与其余集合进行对抗训练。与 AlphaGo 不同的是,主代理被设定为使用有优先级的自学策略,寻找能够对抗历史上某个分布的策略,在两个玩家的零和游戏中该策略会趋向纳什均衡。而主暴露者的对手只是当前的主代理,主要目的是找到当前主代理的弱点。联盟暴露者同样使用深度学习方法,对手为主代理的历史版本,目标是发现主代理的系统性弱点。并且主代理与联盟暴露者都会每隔一段时间重置为深度监督学习的得到集合,以增加对抗人类策略的稳定性。
正如 AlphaStar 研发团队赛后所表示的,群体训练策略是一种更加可靠的训练策略,是通往安全、鲁邦的 AI 的一条路径。如今,AlphaStar 中所使用的群体训练策略已被广泛运用到了天气预测、气候建模、语言理解等众多领域的不完全信息的长序列建模任务之中。
AlphaCode✦
虽然与众多“前辈”相比,AlphaCode 目前的实力与战绩只能算是差强人意。但作为有望在未来以助手身份融入广大开发人员工作中 AI 新星,AlphaCode 的工作原理还是很值得了解与梳理的。
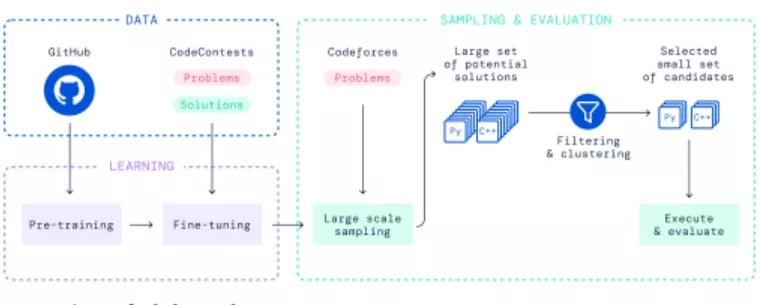
从 DeepMind 所公布的博客介绍与论文中,我们可以发现 AlphaCode 的执行流程大致可以分为四个部分。
预训练:利用标准语言建模目标在 Github 的数据集上预训练 Transformer 语言模型。
微调:在竞争性编程数据集上进行模型微调,使用 GOLD 与 tempering 作为训练目标,进一步减少搜索空间。
生成结果:利用训练后的模型生成所有可能实现任务要求的样本。
筛选提交:对样本进行过滤,删除无法通过样例的代码样本,并通过测试数据模型对剩余样本进行聚类,从聚类最大的样本中按序选取 10 个进行提交。
总体来看,AlphaCode 将 Transformer 模型与采样过滤结合,创造了更为新颖的解决方案。虽远未赢得比赛,但 AlphaCode 所呈现的结果代表了人工智能在解决问题能力上重大的飞跃。DeepMind 表示,将继续该领域的探索,并希望进一步研究生产更为强大的编程工具。
写在最后✦
在如今人工智能技术发展的盛况之下,我们可以大胆预测,未来人工智能还将继续在更多不同的领域刷新人类极限,并为人类的进步提供更多帮助。那么在现阶段,有哪些前沿技术有望推动人工智能的进一步突破,帮助人工智能实现更好的泛化与应用落地?人工智能从感知智能到认知智能的路途还有多长?未来人工智能技术的发展趋势又将如何?
关于以上的一切问题,你都可以在 WOT 全球技术创新大会中得到解答。在即将于 4 月 9 日 -10 日举办的 WOT 全球技术创新大会中,多位来自产业界与学术界的人工智能领域技术专家,将于“认知智能发展新趋势”专场中为广大听众分享他们对人工智能技术发展的真知灼见。感兴趣的同学可扫描下图二维码了解更多详细信息。
目前大会 8 折购票中,现在购票立减 1160 元,团购还有更多优惠!有任何问题欢迎联系票务小姐姐秋秋:15600226809(电话同微信)






















