前言
在源码剖析 - 公众号采集阅读器 Liuli 一文中提到了 ruia,这篇文章就简单记录一下 ruia。
为啥要看?主要是在阅读 Liuli 的过程中,顺手看了一下 ruia 的仓库,发现代码量很少,其宣传中又强调除爬虫核心功能外的所有功能都通过插件的方式实现,我便对其插件系统的实现感到好奇,是像 Flask 那种动态引入呢?还是其他我不知道的方式?
老规矩,看前先理一下兴趣点,不然一头扎入细节,最后啥也带不走,我主要对以下 2 点感兴趣:
- ruia 的设计架构是怎么样的?
- ruia 如何使用插件系统?
观前提示,ruia 并没有实现插件系统,而是利用中间件的形式来实现所谓的插件,跟我自己理解的插件有所差异。
ruia 设计架构
如果你熟悉 Scrapy,那么 ruia 的使用方式和架构你会非常熟悉,因为我在自己开设的进阶爬虫课里手把手带领大家剖析过 Scrapy 框架的代码,所以我比较熟悉Scrapy,如果你不熟悉,本文你可能会比较懵逼。
ruia 相比于 Scrapy 轻量很多,它没有调度器相关的逻辑,而是直接通过 Spider 完成完整的爬取逻辑,先以一个 Demo 为例,看看 ruia 的基本使用,部分代码如下:
class DoubanSpider(Spider):
# 爬虫名称
name = "DoubanSpider"
# 入口url
start_urls = ["https://movie.douban.com/top250"]
# 爬虫相关配置
request_config = {"RETRIES": 3, "DELAY": 0, "TIMEOUT": 20}
concurrency = 10
# aiohttp config
aiohttp_kwargs = {}
# 异步方法
async def parse(self, response):
# 异步阻塞等待
html = await response.text()
etree = response.html_etree(html=html)
pages = ["?start=0&filter="] + [
# 通过css选择器,获得需要进一步爬虫的url
i.get("href") for i in etree.cssselect(".paginator>a")
]
for index, page in enumerate(pages):
url = self.start_urls[0] + page
# 构建新的请求
# 回调方法为parse_item
yield self.request(
url=url, metadata={"index": index}, callback=self.parse_item
)
async def parse_item(self, response):
async for item in DoubanItem.get_items(html=await response.text()):
yield item
async def process_item(self, item: DoubanItem):
self.logger.info(item)
if __name__ == "__main__":
# 启动爬虫
DoubanSpider.start()
从上述代码中,通过 Spider 的 start 方法启动爬虫,该方法代码如下:
@classmethod
def start(
cls,
middleware: typing.Union[typing.Iterable, Middleware] = None,
loop=None,
after_start=None,
before_stop=None,
close_event_loop=True,
**spider_kwargs,
):
# 获取事件循环
loop = loop or asyncio.new_event_loop()
# 实例化当前类,即类方法中的spider_ins变量为当前类的实例 - Scrapy也是这样做的
spider_ins = cls(middleware=middleware, loop=loop, **spider_kwargs)
# 启动事件循环,执行爬虫实例的_start方法
spider_ins.loop.run_until_complete(
spider_ins._start(after_start=after_start, before_stop=before_stop)
)
# 关闭事件循环中的异步生成器对象(asynchronous generator)
spider_ins.loop.run_until_complete(spider_ins.loop.shutdown_asyncgens())
if close_event_loop:
# 关闭事件循环
spider_ins.loop.close()
return spider_ins
从上述代码可知,爬虫的完全流程为:
- 创建事件循环
- 实例化爬虫
- 将爬虫爬取逻辑放入事件循环中异步执行
- 关闭事件循环中异步生成器对象,简单理解即关闭事件循环中的任务
- 关闭事件循环本身
run_until_complete 方法是 asyncio 中比较底层的方法,用于将协程函数或任务对象(task)添加到事件循环中并启动,其基本用法如下:
In [1]: import asyncio
In [2]: # 定义协程函数
In [3]: async def fun(a):
...: print(a)
...:
In [4]: # 调用协程函数,生成一个协程对象,此时协程函数并未执行
In [5]: coroutine = fun('hello world')
In [6]: # 创建事件循环
In [7]: loop = asyncio.get_event_loop()
In [8]: # 将协程函数添加到事件循环,并启动
In [9]: loop.run_until_complete(coroutine)
hello world
关于 Python 事件循环更多信息,可以阅读文档:https://docs.python.org/zh-cn/3/library/asyncio-eventloop.html
从 start 方法可知,爬虫主逻辑其实在_start 方法中,该方法代码比较长,我们拆分来看,首先是添加 signal 的逻辑,相关代码如下:
# Add signal
for signal in (SIGINT, SIGTERM):
try:
self.loop.add_signal_handler(
signal, lambda: asyncio.ensure_future(self.stop(signal))
)
except NotImplementedError:
self.logger.warning(
f"{self.name} tried to use loop.add_signal_handler "
"but it is not implemented on this platform."
)
上述代码中,将 SIGINT 和 SIGTERM 这两个信号添加当前事件循环中,除了这两个外,SIGKILL 也是我们常见的信号,注意,这 3 个信号只实现于类 Unix 平台,即 Linux、MacOS 中有,Windows 没有,Windows 有自己的一套类似实现。
SIGINT、SIGTERM 和 SIGKILL 作用是啥?
当我们按 ctrl+c 来停止进程时,Linux 系统其实就向进程发送 SIGINT 信号,进程接收到 SIGINT 信号后,会停止当前进程,也会停止子进程,注意,SIGINT 信号只能结束前台进程。
在 Linux 中,通过 kill 命令可以干掉某个进程,如果 kill 命令不加任何参数的话,该命令的底层,Linux 系统会向进程发 SIGTERM 信号,注意,当前进程会收到该信号,但子进程不会,即如果进程被 kill 了,那么当前进程的父进程比如是 init,即 PID 为 1 的进程,如果是有用户进程创建出的进程,SIGTERM 是无法关闭的。
对于需要强制关闭的情况,我们会使用 kill -9 来 kill 进程,此时 Linux 会向进程发送 SIGKILL 信号,该信号是无法被捕捉的,进程收到 SIGKILL 信号后,当前进程以及相关的子进程都会被 kill 掉。
为了校验上面我说的是否合理,可以构建一段简单的代码来判断一下,代码如下:
import sys
import asyncio
from signal import SIGINT, SIGTERM
import traceback
# 不同Python版本不同
if sys.version_info >= (3, 9):
async_all_tasks = asyncio.all_tasks
async_current_task = asyncio.current_task
else:
async_all_tasks = asyncio.Task.all_tasks
async_current_task = asyncio.tasks.Task.current_task
async def fun(a):
# 添加信号
for signal in (SIGINT, SIGTERM):
try:
loop.add_signal_handler(
signal, lambda: asyncio.ensure_future(stop(signal))
)
except Exception as e:
traceback.print_exc()
await asyncio.sleep(600)
async def stop(_signal):
print("Stopping async")
# 取消事件循环中所有的任务
await cancel_all_tasks()
# 关停事件循环
loop.stop()
async def cancel_all_tasks():
tasks = []
for task in async_all_tasks():
if task is not async_current_task():
tasks.append(task)
task.cancel()
await asyncio.gather(*tasks, return_exceptions=True)
coroutine = fun('hello world')
loop = asyncio.get_event_loop()
loop.run_until_complete(coroutine)
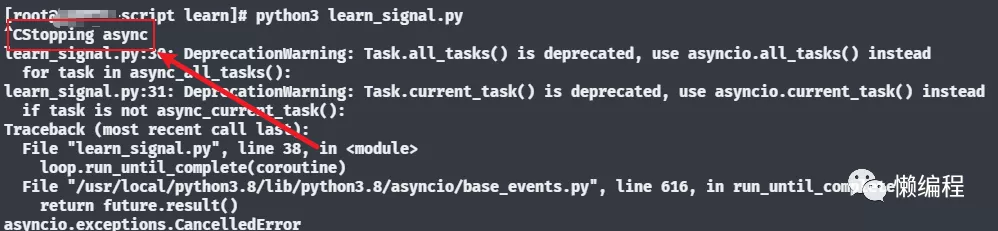
上述代码中,使用 ruia 相似的逻辑弄了一个简单脚本,在 Linux 中运行,然后通过 ctrl+c 将其关闭,效果如下图,可以发现 Stopping async 被打印了出来。
回到_start 方法,添加完信号量后,其代码如下:
# hook - 爬取前需要执行的逻辑
await self._run_spider_hook(after_start)
try:
# 爬虫主逻辑
await self.start_master()
finally:
# hook - 爬取结束前要执行的逻辑
await self._run_spider_hook(before_stop)
await self.request_session.close()
先看到 start_master 方法,代码如下:
async def start_master(self):
"""
Actually start crawling
"""
# 获得Request类实例对象
async for request_ins in self.process_start_urls():
# 完成了请求,获得了response和callback方法处理的结果
self.request_queue.put_nowait(self.handle_request(request_ins))
workers = [
# asyncio.ensure_future方法将start_worker协程方法构建成task
asyncio.ensure_future(self.start_worker())
for i in range(self.worker_numbers)
]
for worker in workers:
self.logger.info(f"Worker started: {id(worker)}")
# 阻塞至队列中所有的元素都被接收和处理完毕
await self.request_queue.join()
if not self.is_async_start:
await self.stop(SIGINT)
else:
if self.cancel_tasks:
await self.cancel_all_tasks()
start_master 方法有两大块逻辑,一块是构建异步任务逻辑,一块是并发执行构建好的异步任务。一步步看一下,先看 process_start_urls 方法,代码如下:
async def process_start_urls(self):
for url in self.start_urls:
# 获得Request类实例
yield self.request(url=url, callback=self.parse, metadata=self.metadata)
process_start_urls 方法的作用就是 start_urls 列表中填写的 url 构建成 Request 类对象,此时并没有完成对网页数据的请求,这里需要注意的是 callback 参数,直接使用 parse 方法作为 callback 的值。
请求的具体逻辑在 handle_request 方法中,该方法代码如下(只摘取了关键代码展示):
async def handle_request(
self, request: Request
) -> typing.Tuple[AsyncGeneratorType, Response]:
callback_result, response = None, None
await self._run_request_middleware(request)
# 完成请求
callback_result, response = await request.fetch_callback(self.sem)
await self._run_response_middleware(request, response)
await self._process_response(request=request, response=response)
# response结果
return callback_result, response
handle_request 方法中,有中间件效果逻辑的调用,即请求前,通过_run_request_middleware 方法调用相关的中间件逻辑处理请求前的 Request 类实例,请求后是类似的,通过_run_response_middleware 方法处理,最后调用_process_response 方法处理最终的 Reponse 类实例。
看到 fetch_callback 方法,该方法完成了请求并获得了相应的结果。
async def fetch_callback(
self, sem: Semaphore
) -> Tuple[AsyncGeneratorType, Response]:
try:
async with sem:
# 请求逻辑
response = await self.fetch()
except Exception as e:
response = None
self.logger.error(f"<Error: {self.url} {e}>")
if self.callback is not None:
if iscoroutinefunction(self.callback):
# 调用callback方法处理后的结果
callback_result = await self.callback(response)
else:
callback_result = self.callback(response)
else:
callback_result = None
return callback_result, response
fetch_callback 方法其实就一层封装,该方法内通过 fetch 方法完成对网页的请求,通过 callback 方法完成对 response 的处理。
看到 fetch 方法,它调用了_make_request 方法实现请求,然后将请求的结果封装成 Response 类实例,相关代码如下(只展示相关代码):
async def fetch(self, delay=True) -> Response:
async with async_timeout.timeout(timeout):
# 发送请求
resp = await self._make_request()
try:
resp_encoding = resp.get_encoding()
except:
resp_encoding = self.encoding
# 使用请求获得的结果构建Response对象
response = Response(
url=str(resp.url),
method=resp.method,
encoding=resp_encoding,
metadata=self.metadata,
cookies=resp.cookies,
headers=resp.headers,
history=resp.history,
status=resp.status,
aws_json=resp.json,
aws_text=resp.text,
aws_read=resp.read,
)
关键的_make_request 方法其实就是利用 aiohttp 相关的方实现了异步请求,代码如下:
async def _make_request(self):
self.logger.info(f"<{self.method}: {self.url}>")
if self.method == "GET":
request_func = self.current_request_session.get(
self.url, headers=self.headers, ssl=self.ssl, **self.aiohttp_kwargs
)
else:
request_func = self.current_request_session.post(
self.url, headers=self.headers, ssl=self.ssl, **self.aiohttp_kwargs
)
resp = await request_func
return resp
fetch 方法看完后,来看 callback 相关的逻辑,在 spider.py 的 process_start_urls 方法中,callback 参数的入参为 parse 方法,所以这里会调用 parse 方法的逻辑来处理网页返回的数据,而 parse 方法通常会实现在最外部的子类中(我们自己实现对网页的解析逻辑)。
回到 start_master 方法,该方法第一步的逻辑就讲完了,这部分逻辑的效果就是将 callback_reuslt 和 response 添加到了 request_queue 队列中,但需要注意,因为这里是异步操作,所以 requests_queue 是异步对象实例,而不是 callback_reuslt 与 response。
然后看到其第二部分的逻辑,因为第一部分逻辑都是异步操作,第二部分逻辑,主要是并发执行第一部分异步逻辑,然后获得 callback_reuslt 与 response,其主要逻辑实现在 start_worker 方法中。
start_worker 方法代码如下:
async def start_worker(self):
"""
Start spider worker
:return:
"""
while True:
# 获得Request类实例
request_item = await self.request_queue.get()
# 添加到任务列表中
self.worker_tasks.append(request_item)
if self.request_queue.empty():
# 并发运行 self.worker_tasks 序列中的可等待对象
results = await asyncio.gather(
*self.worker_tasks, return_exceptions=True
)
for task_result in results:
if not isinstance(task_result, RuntimeError) and task_result:
callback_results, response = task_result
if isinstance(callback_results, AsyncGeneratorType):
await self._process_async_callback(
callback_results, response
)
self.worker_tasks = []
self.request_queue.task_done()
这部分逻辑没啥好讲的,主要就是通过 asyncio.gather 并发执行 worker_tasks 中的任务,然后获得 callback_results 和 response。
在 start_master 方法中,通过 join 方法等待 request_queue 队列中的任务都完成执行。
至此,ruia 中的主逻辑就阅读完了,不太复杂,是学习 Python asyncio 很好的参考代码。
ruia 插件系统
ruia 其实没有设计所谓的插件系统,而是利用中间件的概念来作为所谓的插件,与 scrapy 类似,ruia 中间件会在请求前以及请求后两个时间点调用,在上文的代码中也提及了:_run_request_middleware 方法与_run_response_middleware 方法。
为了进一步理解 ruia 的插件,这里拉取 ruia-ua 项目的代码,该项目是 ruia 作者实现的用于替换请求头中 User-Agent 的插件,使用 ruia-ua 以及 ruia 来爬取 HackerNews 网站数据,代码如下:
from ruia import AttrField, TextField, Item, Spider
from ruia_ua import middleware
class HackerNewsItem(Item):
target_item = TextField(css_select='tr.athing')
title = TextField(css_select='a.storylink')
url = AttrField(css_select='a.storylink', attr='href')
class HackerNewsSpider(Spider):
start_urls = ['https://news.ycombinator.com/news?p=1', 'https://news.ycombinator.com/news?p=2']
async def parse(self, response):
# Do something...
print(response.url)
if __name__ == '__main__':
# 使用ruia-ua插件
HackerNewsSpider.start(middleware=middleware)
从上述代码可知,所谓使用 ruia-ua 插件,其实就是使用 ruia-ua 提供的中间件。
翻阅 ruia-ua 代码,其中关键的逻辑如下:
middleware = Middleware()
@middleware.request
async def add_random_ua(spider_ins, request):
ua = await get_random_user_agent()
if request.headers:
request.headers.update({'User-Agent': ua})
else:
request.headers = {
'User-Agent': ua
}
上述代码很简单,就是用 middleware.request 装饰器处理了 add_random_ua 方法,而 add_random_ua 方法实现了替换 User-Agent 的逻辑。
middleware.request 装饰器的代码在 ruia/middleware.py 中,相关代码如下:
def request(self, *args, **kwargs):
"""
Define a Decorate to be called before a request.
eg: @middleware.request
"""
middleware = args[0]
@wraps(middleware)
def register_middleware(*args, **kwargs):
self.request_middleware.append(middleware)
return middleware
return register_middleware()
middleware.request 方法的逻辑也非常简单,就是向 request_middleware 列表中添加相应的方法对象,然后在_run_request_middleware 方法中被调用。
_run_request_middleware 方法的代码如下:
async def _run_request_middleware(self, request: Request):
if self.middleware.request_middleware:
# 顺序调用中间件
for middleware in self.middleware.request_middleware:
if callable(middleware):
try:
aws_middleware_func = middleware(self, request)
if isawaitable(aws_middleware_func):
await aws_middleware_func
else:
self.logger.error(
f"<Middleware {middleware.__name__}: must be a coroutine function"
)
except Exception as e:
self.logger.exception(f"<Middleware {middleware.__name__}: {e}")
这便是 ruia 中所谓的插件,即利用装饰器,将需要使用的方法添加到某个 list 对象中,在 ruia 请求网站的过程中,在请求前和请求后都给相应 list 对象中的方法调用的机会,从而实现所谓的插件。
结尾
总的来说,ruia 是很好的 Python Asyncio 学习资料,里面关于 asyncio 的用法是可以直接抄,至于其插件系统,其实是中间件的换一种说法,离真正的插件还有差距。