强化学习 (RL) 与深度学习的结合带来了一系列令人印象深刻的成果,许多人认为(深度)强化学习提供了通向通用智能体的途径。然而,RL 智能体的成功通常对训练过程中的设计选择高度敏感,可能需要繁琐且容易出错的手动调整。这使得将 RL 用于新问题具有挑战性,同时也限制了 RL 的全部潜力。
在机器学习的许多其他领域,AutoML 已经表明可以自动化此类设计选择,并且在应用于 RL 时也产生了有希望的初步结果。然而,自动强化学习 (AutoRL) 不仅涉及 AutoML 的标准应用,还包括 RL 独有的额外挑战,这使得研究者自然而然地产生了一些不同的方法。
AutoRL 已成为 RL 研究的一个重要领域,为从 RNA 设计到围棋等游戏的各种应用提供了希望。由于 RL 中考虑的方法和环境具有多样性,因此许多研究都是在不同的子领域进行的。来自牛津大学、弗莱堡大学、谷歌研究院等机构的十余位研究者撰文试图统一 AutoRL 领域,并提供了通用分类法,该研究详细讨论了每个领域并提出未来研究人员可能感兴趣的问题。

论文地址:https://arxiv.org/pdf/2201.03916.pdf
AutoRL 方法
强化学习理论上可以用于任何任务,包括世界模型未知的环境。然而,这种通用性也是有代价的,其最大的缺点就是智能体往往不能获得环境的真实模型。如果智能体想在一个场景下使用模型,那它必须完全从经验中学习,这会带来很多挑战。智能体探索出来的模型和真实模型之间存在误差,而这种误差会导致智能体在学习到的模型中表现很好,但在真实的环境中表现得不好(甚至很差)。
该研究调查的目的是介绍 AutoRL 领域,AutoRL 可以应对各种挑战:一方面,RL 算法的脆弱性阻碍了其在新领域的应用,尤其是那些从业者缺乏大量资源来搜索最佳配置的领域。在许多情况下,对于完全不可见的问题,手动找到一组中等强度的超参数可能会非常昂贵。AutoRL 已被证明可以在这种情况下帮助解决重要问题,例如设计 RNA。另一方面,对于那些受益于更多计算的人来说,显然增加算法的灵活性可以提高性能。著名的 AlphaGo 智能体已经展示了这一点,该智能体通过使用贝叶斯优化得到了显着改进。
早在 1980 年代,AutoRL 算法就被证明是有效的。然而,最近 AutoML 的流行导致了更先进技术的新生应用。与此同时,最近元学习的流行导致了一系列旨在自动化 RL 过程的工作。
该论文试图提供这些方法的分类,他们希望通过思想的交叉融合来开辟一系列未来的工作,同时也向 RL 研究人员介绍一套技术来提高他们的算法性能。该研究相信 AutoRL 在提高强化学习潜在影响方面发挥着重要作用,无论是在开放式研究和还是在现实应用中。
此外,该研究希望将对 AutoML 感兴趣的研究人员吸引到 AutoRL 社区,特别地,RL 具有非平稳性(non-stationarity),因为智能体正在训练的数据是当前策略的函数。此外,该研究还介绍了 AutoRL 针对特定 RL 问题的环境和算法设计。
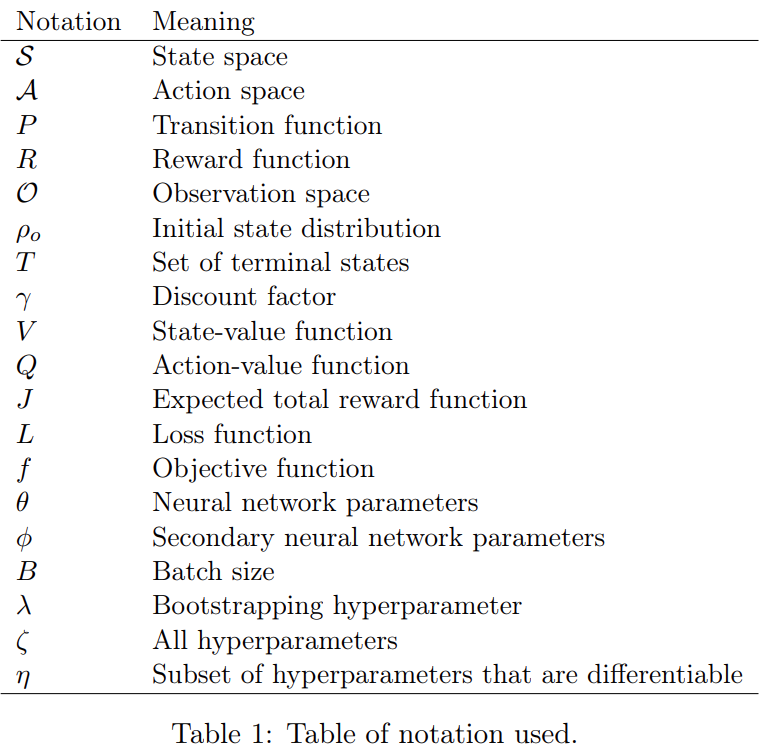
该研究调查了 AutoRL 社区以及技术等内容。一般来说,AutoRL 方法大多数都可以通过组合内部循环和外部循环组织起来。每个循环都可以通过黑箱或基于梯度的方法进行优化,然而外部循环的梯度和内部循环的黑箱不能组合在一起,因为内部循环黑箱设置将使梯度不可用,如表 2 和图 2 所示:

如下表 3 所示,该研究按照大类总结了 AutoRL 方法的分类,方法分类将体现在第四章的每一小节

随机 / 网格搜索驱动方法
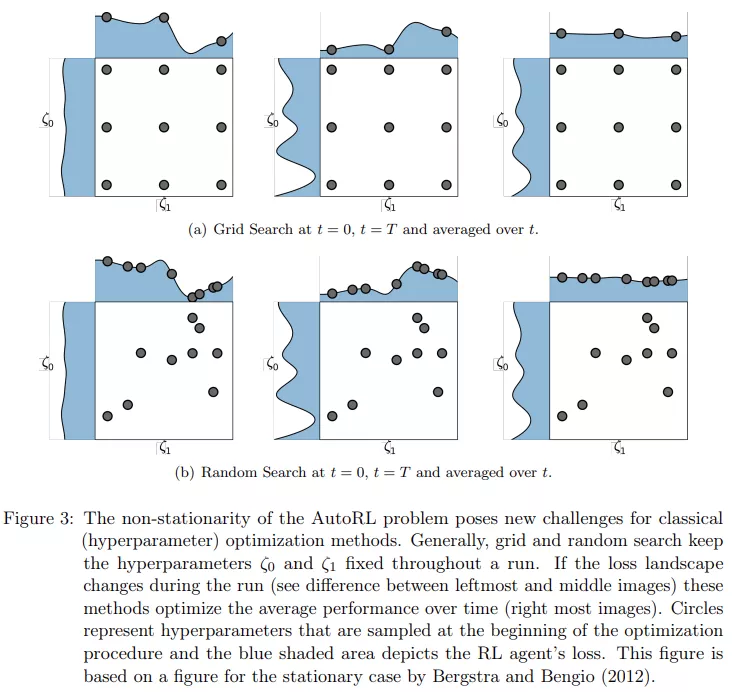
该研究首先讨论了最简单的方法:随机搜索和网格搜索。随机搜索从搜索空间中随机采样超参数配置,而网格搜索将搜索空间划分为固定的网格点,并对其进行评估。由于其简单性,随机搜索和网格搜索可用于选择超参数列表,评估超参数并选择最佳配置。事实上,网格搜索仍然是 RL 中最常用的方法,网格搜索在绝大多数情况下都会调整超参数,但不应将其视为最有效的方法。但是这些经典方法没有考虑优化问题的潜在非平稳性,下图 3 描述了这个问题:
提高随机搜索性能的一种常见方法是使用 Hyperband,这是一种用于超参数优化的配置评估。它专注于通过自适应资源分配和早停(early-stopping)来加速随机搜索。特别的,Hyperband 使用「Successive Halving」将预算分配给一组超参数配置。Zhang 等人使用随机搜索和 Hyperband 来调整其 MBRL 算法的超参数。
贝叶斯优化
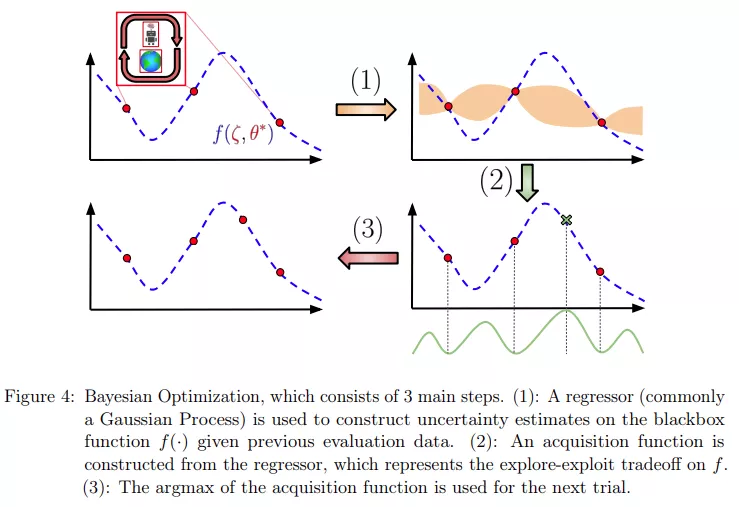
贝叶斯优化(Bayesian Optimization ,BO)是迄今为止最流行的方法之一,主要用于工业应用和各种科学实验。对于 RL 应用程序,BO 最突出的用途之一是调整 AlphaGo 超参数,其中包括蒙特卡洛树搜索 (MCTS) 超参数和时间控制设置。这导致 AlphaGo 在自我对弈中的胜率从 50% 提高到 66.5%。图 4 展示了 RL 案例中贝叶斯优化的一般概念:
演化算法
演化算法被广泛应用于各种优化任务,其机制如图 5 所示:
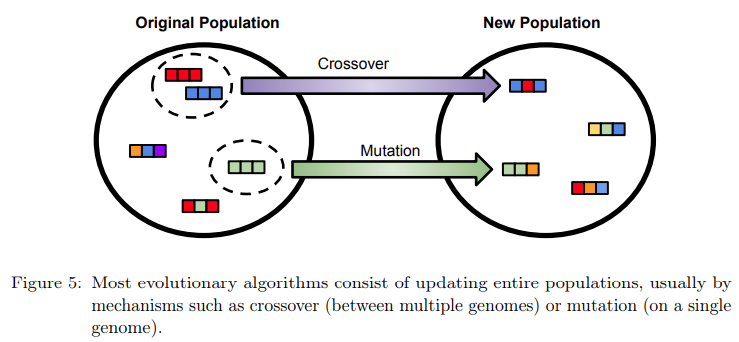
演化算法经常被用于搜索 RL 算法的超参数。Eriksson 等人使用实数遗传算法 (GA),通过种群中每个个体的基因编码 RL 算法的超参数,以调整 SARSA 超参数,研究者将该方法应用于控制移动机器人。Cardenoso Fernandez 和 Caarls 使用 GA 在简单设置中调整 RL 算法的超参数,并通过结合自动重启策略以摆脱局部最小值,取得了良好的性能。Ashraf 等人使用 Whale 优化算法(WOA),其灵感来自座头鲸的狩猎策略,在各种 RL 任务中优化 DDPG 超参数以提高性能。
用于在线调优的元梯度
元梯度提供了一种替代方法来处理 RL 超参数的非平稳性。元梯度公式的灵感来自元学习方法,例如 MAML,它使用梯度优化了内部和外部循环。特别是,元梯度方法将其(可微分)超参数的子集指定为元参数 η。在内部循环中,智能体使用固定的 η 进行优化,采用梯度 step 来最小化(通常是固定的)损失函数。在外部循环中,通过采取梯度 step 来优化 η,以最小化外部损失函数。内部和外部损失函数的每个特定选择都定义了一个新的元梯度算法。
黑盒在线调优
PBT 和元梯度的优势在于动态调整超参数的能力,然而,这并不是唯一的方法。事实上,研究者已经考虑了各种其他方法,从黑盒方法到在线学习启发方法。本节重点介绍在超参数不是可微的设置中动态适应的单智能体方法。
自适应选择超参数的方法自 20 世纪 90 年代以来一直很重要。Sutton 和 Singh (1994) 提出了 TD 算法中自适应加权方案的三种替代方法,Kearns 和 Singh (2000) 推导出时序差分算法误差上限,并使用这些边界推导出 λ 的时间表。Downey 和 Sanner (2010) 使用贝叶斯模型平均来为 TD 方法选择 λ bootstrapping 超参数。最近, White (2016) 提出了 λ-greedy 来适应 λ 作为状态的函数,并实现近似最优的偏差 - 方差权衡,Paul 等人 (2019) 提出了 HOOF,它使用带有非策略数据的随机搜索来周期性地为策略梯度算法选择新的超参数。
环境设计
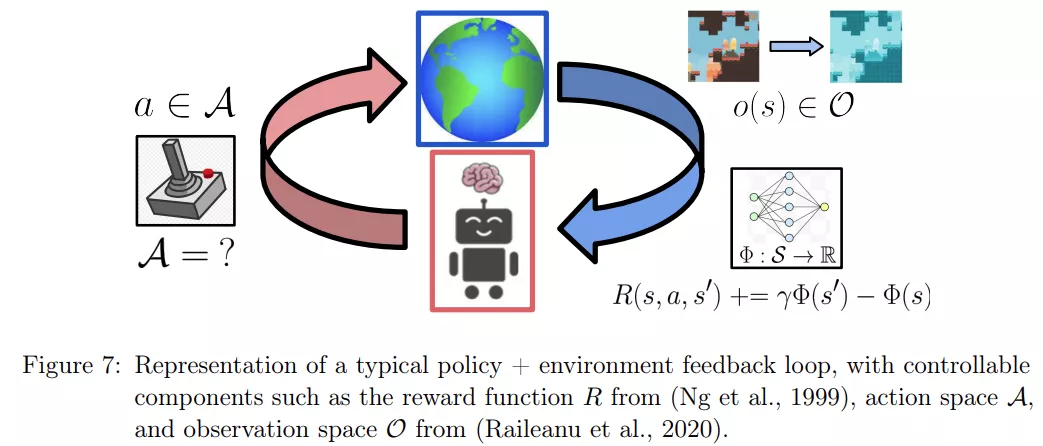
环境设计是强化学习智能体自动学习的重要组成部分。从课程学习到合成环境学习和生成,到将课程学习与环境生成相结合,这里的目标是加快机器学习智能体通过环境设计的学习速度。如图 7 所示:
混合方法
不可避免的是,一些方法不属于单一类别。事实上,许多方法都试图利用不同方法的优势,可称之为混合方法。在该研究中,这些混合方法被定义为使用表 3 中不止一类技术的方法,例如 BOHB、DEHB 等。