最早的时候页面是服务端渲染的,也就是 PHP、JSP 那些技术,服务端通过模版引擎填充数据,返回生成的 html,交给浏览器渲染。那时候表单会同步提交,服务端返回结果页面的 html。
后来浏览器有了 ajax 技术,可以异步的请求,服务端返回 xml 或者 json。ajax 最早是基于 xml 的,这也是它名字的由来。因为 xml 多了很多没必要的标签,内容比较多,所以后来 json 流行开来。
网页和服务端的数据交互变成了异步的,可以服务端返回 json 数据,浏览器里拼接 html,之后渲染(浏览器里面生成 dom 就等同于渲染)。页面基本没啥刷新的必要了,于是后来就逐渐演变出了单页应用 SPA(single page application)。
早期开发页面的时候就是基于浏览器的 dom api 操作 dom 来做渲染和交互,但是 dom api 比较啰嗦,而且当时浏览器的兼容性问题也比较麻烦,不同浏览器有不同的写法。
为了简化 dom 操作和更方便的兼容各种浏览器,出现了 jquery 并且迅速流行开来,那个时代 jquery 是如日中天的。
我一直习惯把网页分为物理层和逻辑层,dom 就算是物理层,jquery 是操作 dom 的一系列工具函数,也是工作在物理层。
网页做的事情基本就是拿到数据渲染 dom,并且数据改变之后更新 dom,这个流程是通用的,后来逐渐出现了 mvvm 框架,来自动把数据的变更映射到 dom,不再需要手动操作 dom。也就是 vue、react 等现代的前端框架。我把这一层叫做逻辑层。
前端框架除了提供了数据驱动视图变化的功能以外,还支持了 dom 的逻辑划分,可以把一部分 dom 封装成组件,组件和组件之间相互组合,构成整个界面。物理层依然是 dom,只是实现了数据到 dom 的自动映射之后,我们只需要在逻辑层写组件就可以了。
现在前端入门也不会再学物理层的操作 dom 的 jquery 了,而是直接从 vue、react 这种逻辑层的前端框架开始。
但是也不是说完全不需要 jquery,前端框架主要解决的是数据到 dom 的绑定,可以变化以后自动更新 dom。如果不需要更新,那么直接操作 dom 即可,比如各种活动页,没啥数据更新,用 jquery 操作 dom 还是很方便。
前端框架是 UI = f(state) 这种声明式的思想,只需要声明组件的视图、组件的状态数据、组件之间的依赖关系,那么状态改变就会自动的更新 dom。而 jquery 那种直接操作 dom 的工具函数库则是命令式的。
对于视图的描述这件事 react 和 vue 用了不同的方案,react 是给 js 扩展了 jsx 的语法,由 babel 实现,可以在描述视图的时候直接用 js 来写逻辑,没啥新语法。
而 vue 是实现了一套 template 的 DSL,引入了插值、指令、过滤器等模版语法,相对于 jsx 来说更简洁,template 的编译器由 vue 实现。
vue template 是受限制的,只能访问 data,prop、method,可以静态的分析和优化,而 react 的 jsx 因为直接是 js 的语法,动态逻辑比较多,没法静态的做分析和优化。
但是 vue template 也不全是好处,因为和 js 上下文割裂开来,引入 typescript 做类型推导的时候就比较困难,需要单独把所有 prop、method、data 的类型声明一遍才行。而 react 的 jsx 本来就是和 js 同一个上下文,结合 typescript 就很自然。
所以 vue template 和 react jsx 各有优缺点。
前端框架都是数据驱动视图变化的,而这个数据分散在每个组件中,怎么在数据变化以后更新 dom 呢?
数据变化的检测基本只有三种方式:watch、脏检查、不检查。
vue 就是基于数据的 watch 的,组件级别通过 Object.defineProperty 监听对象属性的变化,重写数组的 api 监听数组元素的变化,之后进行 dom 的更新。
angular 则是基于脏检查,在每个可能改变数据的逻辑之后都对比下数据是否变了,变了的话就去更新 dom。
react 则是不检查,不检查难道每次都渲染全部的 dom 么?也不是,不检查是因为不直接渲染到 dom,而是中间加了一层虚拟 dom,每次都渲染成这个虚拟 dom,然后 diff 下渲染出的虚拟 dom 是否变了,变了的话就去更新对应的 dom。
这就是前端框架的数据驱动视图变化的三种思路。
vue 是组件级别的数据 watch,当组件内部监听数据变化的地方特别多的时候,一次更新可能计算量特别大,计算量大了就可能会导致丢帧,也就是渲染的卡顿。所以 vue 的优化方式就是把大组件拆成小组件,这样每个数据就不会有太多的 watcher 了。
react 并不监听数据的变化,而是渲染出整个虚拟 dom,然后 diff。基于这种方案的优化方式就是对于不需要重新生成 vdom 的组件,通过 shouldComponentUpdate 来跳过渲染。
但是当应用的组件树特别大的时候,只是 shouldComponentUpdate 跳过部分组件渲染,依然可能计算量特别大。计算量大了同样可能导致渲染的卡顿,怎么办呢?
树的遍历有深度优先和广度优先两种方式,组件树的渲染就是深度优先的,一般是通过递归来做,但是如果能通过链表记录下路径,就可以变成循环。
变成了循环,那么就可以按照时间片分段,让 vdom 的生成不再阻塞页面渲染,这就像操作系统对多个进程的分时调度一样。
这个通过把组件树改成链表,把 vdom 的生成从递归改循环的功能就是 react fiber。
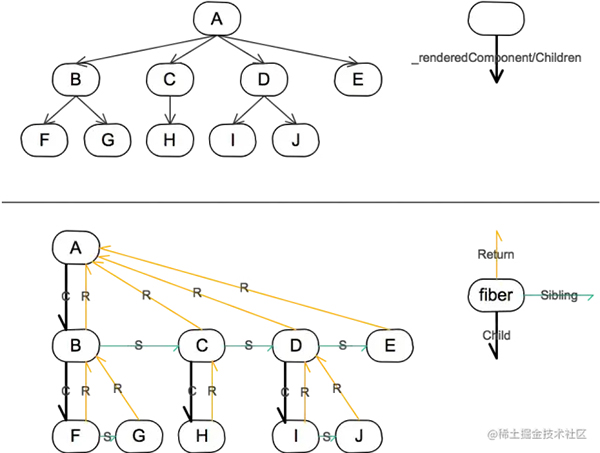
fiber 节点相对于之前的组件节点来说,没有了 parent、children 这种属性,多了 child、sibling、return 属性。
通过 fiber 链表树,优化了渲染的性能。
可以看到 vue 的性能优化和 react 的性能优化是不一样的:
vue 是组件级别的数据监听的方案,问题可能出现在一个属性太多 watcher 的时候,所以优化思路就是大组件拆分成小组件,保证每个属性不要有太多 watcher。
react 不监听、不检查数据变化,每次都渲染生成 vdom,然后进行 vdom 的对比,那么优化的思路就是 shouldComponentUpdate 来跳过部分组件的 render,而且 react 内部也做了组件树的链表化(fiber)来把递归改成可打断的渲染,按照时间片来逐渐生成整个 vdom。
组件之间难免要有逻辑的复用,react 和 vue 有不同的方案:
vue 的组件是 option 对象的方式,那么逻辑复用方式很自然可以想到通过对象属性的 mixin,vue2 的组件内逻辑复用方案就是 mixin,但是 mixin 很难区分混入的属性、方法的来源,比较乱,代码维护性差。但也没有更好的方案。
react 刚开始也是支持 mixin 的,但后来废弃了。
react 的组件是 class 和 function 两种形式,那么类似高阶函数的高阶组件(high order component)的方式就比较自然,也就是组件套组件,在父组件里面执行一部分逻辑,然后渲染子组件。
除了多加一层组件的 HOC 方式以外,没有逻辑的部分可以直接把那部分 jsx 作为 props 传入另一个组件来复用,也就是 render props。
HOC 和 render props 是 react 的 class 组件支持的两种逻辑复用方案。
最开始的 function 组件是没有状态的,只是作为 class 组件渲染的辅助而存在。
但是 HOC 的逻辑复用方式最终导致了组件嵌套太深,而且 class 内部生命周期比较多,逻辑都放在一起导致了组件比较大。
怎么解决 class 组件嵌套深和组件大的问题呢?而且还不能引入破坏性的更新,不然下场可能会很惨。
于是 react 团队就瞅准了 function 组件,能不能在 function 组件里面也支持 state,通过扩展一些 api 的方式来支持,也不是破坏性的更新。
function 组件要支持 state,那 state 存在哪里呢?
class 组件节点有 state,变成 fiber 节点之后依然有,function 组件本来就没有 state,那么 fiber 节点中同样也没有。
那在 function 组件的 fiber 节点中加入 state 不就行了?
于是 react 就在 function 组件的 fiber 节点中加入了 memorizedState 属性用来存储数据,然后在 function 组件里面通过 api 来使用这些数据,这些 api 被叫做 hooks api。
因为是使用 fiber 节点上的数据,就把 api 命名为了 useXxx。
每个 hooks api 都要有自己存放数据的地方,怎么组织呢?有两种方案,一种是 map,一种是数组。
用 map 的话那么要 hooks api 要指定 key,按照 key 来存取 fiber 节点中的数据。
用数组的话顺序不能变,所以 hooks api 不能出现在 if 等逻辑块中,只能在顶层。
为了简化使用, hooks 最终使用了数组的方式。当然,实现起来用的是链表。
每个 hooks api 取对应的 fiber.memoriedState 中的数据来用。
hooks api 可以分为 3 类:
第一类是数据类的:
- useState:在 fiber.memoriedState 的对应元素中存放数据
- useMemo:在 fiber.memoriedState 的对应元素中存放数据,值是缓存的函数计算的结果,在 state 变化后重新计算值
- useCallback:在 fiber.memoriedState 的对应元素中存放数据,值是函数,在 state 变化后重新执行函数,是 useMemo 在值为函数的场景下的简化 api,比如 useCallback(fn, [a,b]) 相当于 useMemo(() => fn, [a, b])
- useReducer:在 fiber.memoriedState 的对应元素中存放数据,值为 reducer 返回的结果,可以通过 action 来触发值的变更
- useRef:在 fiber.memoriedState 的对应元素中存放数据,值为 {current: 具体值} 的形式,因为对象不变,只是 current 属性变了,所以不会修改。
useState 是存储值最简单的方式,useMemo 是基于 state 执行函数并且缓存结果,相当于 vue 的 getter,useCallback 是一种针对值为函数的情况的简化,useReducer 是通过 action 来触发值的修改。useRef 包了一层对象,每次对比都是同一个,所以可以放一些不变的数据。
不管形式怎么样,这些 hooks 的 api 的作用都是返回值的。
第二类是逻辑类的:
- useEffect:异步执行函数,当依赖 state 变化之后会再次执行,当组件销毁的时候会调用返回的清理函数
- useLayoutEffect:在渲染完成后同步执行函数,可以拿到 dom
这两个 hooks api 都是用于执行逻辑的,不需要等渲染完的逻辑都可以放到 useEffect 里。
第三类是 ref 转发专用的:
数据可以通过各种方案共享,但是 dom 元素这种就得通过 ref 转发了,所谓的 ref 转发就是在父组件创建 ref,然后子组件把元素传过去。传过去之前想做一些修改,就可以用 useImperativeHandle 来改。
通过这 3 类 hooks api,以及之后会添加的更多 hooks api ,函数组件里面也能做 state 的存储,也能在一些阶段执行一段逻辑,是可以替代 class 组件的方案了。
而且更重要的是,hooks api 是传递参数的函数调用的形式,可以对 hooks api 进一步封装成功能更强大的函数,也就是自定义 hooks。通过这种方式就可以做跨组件的逻辑复用了。
再回头看一下最开始要解决的 class 组件嵌套过深和组件太大的问题,通过 hooks 都能解决:
- 逻辑扩展不需要嵌套 hoc 了,多调用一个自定义的 hooks 就行
- 组件的逻辑也不用都写在 class 里了,完全可以抽离成不同的 hooks
react 通过 function 组件的 hooks api 解决了 class 组件的逻辑复用方案的问题。(fiber 是解决性能问题的,而 hooks 是解决逻辑复用问题的)
vue2 中是通过 mixin 的方式来复用逻辑的,也有组件太大的问题,在 vue3 中也可以通过类似的思路来解决。
为了体验和原生更接近,现在基本都是不刷新页面的单页应用,都是从服务端取数据然后驱动 dom 变化的 浏览器渲染(csr)方案。但对于一些低端机,仍然需要服务端渲染(ssr)的方案。
但不能回到 jsp、php 时代的那种模版引擎服务端渲染了,而是要基于同一个组件树,把它渲染成字符串。服务端渲染和浏览器渲染都用同样的组件代码,这就是同构的方案。
技术从出现到完善到连带的周边生态的完善是一个轮回,从最开始服务端渲染,到了后来的客户端渲染,然后出现了逻辑层的组件方案,最后又要基于组件方案重新实现服务端渲染。
其实物理层的东西一直都没变,只是逻辑层不断的一层添加又一层,目的都是为了提高生产效率,降低开发成本,保证质量,这也是技术发展的趋势。