












先抛出几个问题
- 声明一个 slice 并赋值为 nil, 如 var slice []int = nil,此时 len(slice) 的运行结果是什么?
- func(arr []int) 和 func(arr [10]int) 两个函数内部都对 arr 进行修改, 对外面的值(作为参数的数据)是否造成影响?
- 创建一个 slice := make([]int, 5, 10), 然后 slice[8] 和 slice[:8] 的运行结果是什么?
- 下面两段代码的输出结果是什么
slice := []int{1, 2, 3, 4, 5}
slice2 := append(slice[:3], 6, 7)
fmt.Println(slice)
fmt.Println(slice2)
slice := []int{1, 2, 3, 4, 5}
slice2 := append(slice[:3], 6, 7, 8) // 多追加一个数字 8, 这是唯一的不同
fmt.Println(slice)
fmt.Println(slice2)
如果上面的问题都能很轻松回答上来, 可以直接关闭文章了。
为了方便, 下面的描述均以 int 作为元素类型说明
数组 Array
先说一下数组, 的确在 Go 语言中, 因为 slice 的存在, 使得 array 的出场率不高。但想要很好地理解 slice, 还是要先要了解 array.
数组的声明
Go 语言的数组和其他语言一样, 没有什么特别的地方, 就是一段以元素类型(如int)为单位的连续内存空间。数组创建时, 被初始化为元素类型的零值.
声明举例:
var arr [10]int // 长度为 10 的数组, 默认所有元素是 0
arr := [...]int{1, 2, 3} // 长度由初始化元素个数指定, 这里长度是 3
arr := [...]int{11: 3} // 长度为 11 的数组, arr[11] 初始化为 3, 其他为 0
arr := [5]int{1,2} // 长度为 5 的数组, 前两位初始化为 1, 2
arr := [5]int{1,2} // 长度为 5 的数组, 前两位初始化为 1, 2
arr := [...]int{1: 23, 2, 3: 22} // 长度为 4 的数组, 初始化为 [0 23 2 22]
[] 内设定数组长度, 写成 ... 表示长度由后面的初始化值决定.
数组初始化的完整写法是 {1:23, 2:8, 3:12}, 只不过可以省略 index 写成 {23, 8, 12}, index 自动从 0 开始累加, 最大的 index 值决定数组长度.
如 {5: 10, 11, 12, 6: 100} 是非法的, 因为它会被转换成 {5: 10, 6: 11, 7: 12, 6: 100}, 会出现编译错误 duplicate index in array literal: 6.
长度为 0 的数组
比较特别的就是 [0]int, 长度为 0 的数组. 这种不占有任何内存空间的数据类型实际上是无意义的, 所以 Go 语言对此类数据特殊处理了一下, 此外还包括 struct{}, [10]struct{} 等.
看一个例子:
var (
a [0]int
b struct{}
c [0]struct {
Value int64
}
d [10]struct{}
e = new([10]struct{}) // new 返回的就是指针
f byte
)
fmt.Printf("%p, %p, %p, %p, %p, %p", &a, &b, &c, &d, e, &f)
// 0x1127a88, 0x1127a88, 0x1127a88, 0x1127a88, 0x1127a88, 0xc42000e280
前 5 个变量的内存地址一样, 第 6 个变量 f 有一个真实可用的内存. 也就是说 Go 并没有为 [0]int 和 struct{} 这类数据真正分配地址空间, 而是统一使用同一个地址空间.
这类数据结构在 map 中经常应用, 比如 map[string]struct{}. 声明这样一个 map 类型来标记某个 key 是否存在. 在 key 值很多的情况下, 要比 map[string]bool 之类的结构节约很多内存, 同时也减小 GC 压力.
数组作为函数参数
文章最开始的问题中提到, func(arr [3]int) 内部对 arr 进行修改是否会影响外面的实际值. 答案是不会.
因为一个数组作为参数时, 会拷贝一份副本作为参数, 函数内部操作的数组与外界数组, 在内存中根本就不是同一个地方. 是值传递不是引用传递, 这点可能和某些语言不同.
看下面代码:
array := [3]int{1, 2, 3}
func(innerArray [3]int) {
innerArray[0] = 8
fmt.Printf("%p: %v\n", &innerArray, innerArray)
}(array)
fmt.Printf("%p: %v\n", &array, array)
// 0xc42000a2e0: [8 2 3]
// 0xc42000a2c0: [1 2 3]
函数内外, 数组的内存地址都不一样, 自然不会有影响.
如果你想让函数直接修改, 可以使用指针, 即 func(arr *[3]int).
切片 Slice
slice 通常用来表示一个变长序列, 也是基于数组实现的。看下图:
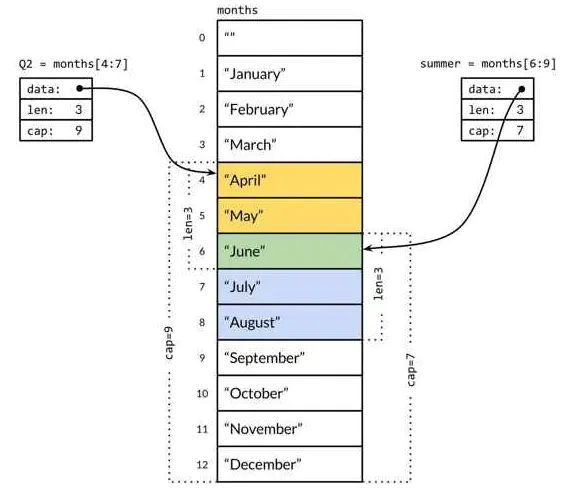
图中 Q2 和 summer 是 slice, 实际就是对数组 months 引用, 只是记录了引用了数组中的那些元素.
再看一下 slice 在 Go 内部的定义.
type slice struct {
array unsafe.Pointer // 被引用的数组中的起始元素地址
len int // 长度
cap int // 最大长度
}
我们对 slice 的读写, 实际上操作的都是它所指向的数组.
看到了上面的 slice 数据结构, 自然就知道了以下两点:
值为 nil 的 slice 变量的 len 和 cap 都是 0. 虽然它没有指向具体某个数组(slice.array 为空), 但是它的 slice.len 和 slice.cap 默认就是 0.
func(arr []int) 这种函数对参数 arr 的修改, 会影响到外面数值, 因为函数内部操作的内存与外界是同一个. 这是 slice 和 array 的主要区别之一.
slice 越界
slice 是可伸缩变长的, 导致很多人误以为 slice 是不会越界的, 下面我们来阐述下几种越界情况.
以上图中右侧的 summer 为例, summer[4] = "hello" 肯定会出现 index out of range 的 panic 信息, 尽管 cap(summer) = 7, 但 summer[4] 超出了 len(summer) = 3 的范围.
再看下面这个例子:
arr := [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println(arr[:3:5][:4]) // [1 2 3 4]
fmt.Println(arr[:3:5][:8]) // panic: runtime error: slice bounds out of range
arr[:3:5] 基于 arr 创建一个 slice, len 是 3, cap 是 5; 然后再在这个 slice 的基础上分别创建一个 len = 4 和 len = 8 的 slice. 前者运行正常, 后者因超出 cap = 5 范围而 panic, 尽管后者实际想要的内存并没有超出 arr 数组范围.
对 slice 的操作记住两点:
- 数据直接访问(slice[index])时, index 值不能超过 len(slice) 范围
- 创建切片(slice[start:end])时, start 和 end 指定的区间不能超过 cap(slice) 范围
所以, 文章开头的第 3 个问题, slice[8] 会 panic, 而 slice[:8] 正常返回.
append 函数
很多人以为 slice 是可以自动扩充的, 估计都是 append 函数误导的. 其实 slice 并不会自己自动扩充, 而是 append 数据时, 该函数如果发现超出了 cap 限制自动帮我们扩的.
当执行 append(slice, v1, v2) 时, append 函数会先检查执行结果的长度是否会超出 cap(slice).
如果超出, 就先 make 一个更长的 slice, 然后把整个 slice 都 copy 到新 slice 中, 再进行 append.
如果没超, 直接以 len(slice) 为起始点进行追加, len(slice) 会随着 append 操作不断扩大, 直到达到 cap(slice) 进行扩充.
建议使用者尽可能的避免让 append 自动为你扩充内存. 一个是因为扩充时会出现一次内存拷贝, 二是因为 append 并不知道需要扩充多少, 为了避免频繁扩充, 它会扩充到 2 * cap(slice) 长度. 而有时我们并不需要那么多内存.
所以在使用 slice 时, 最好不要不 make, 直接 append 让其自己扩充; 而是先 make([]int, 0, capValue) 准备一块内存, capValue 需要自己估计下, 尽可能确保足够用就好.






















