2017年什么准备开发D-SMART这个产品的时候,是受到“知识自动化”这个理念的启发,想通过运维知识图谱积累运维经验,再辅助以深度学习、人工智能的算法,实现复杂的数据库运维问题的自动化。一晃这件事也做了四年了,虽然说摸到了一些门道,不过前面依然是漫漫长路,和刚上路不同的是,现在天已经蒙蒙亮了,不像我们刚刚出发的时候,只能看到前面黑沉沉的长路。这条路已经被证明是能走得通的,剩下来的是通过漫长的积累,逐步完善知识库。
我们的知识库是在不断的实践过程中慢慢的积累,随着从案例中提取的知识的积累不断地弥补整个知识网络中的缺陷,让知识更丰富,能发挥更大的作用。因此每个案例对我们来实都是十分珍贵的,必须从中挖掘出最大的价值才行。
可能有朋友要说了,这有什么难的,把以往的案例抽象出来,形成知识,下次再遇到类似的问题就可以处理了,框架已经打好了,剩下的只要积累不就行了。这实际上也是我最初的想法,不过做到今天,随着我们不断的拿到客户现场的实际案例,我们发现实际上故障自动化分析并不是那么简单的事情。
昨天有个客户说他们的系统中有个业务比较慢,通过TOP EVENT发现存在大量的latch: row cache objects等待,有个业务相关的SQL执行的十分缓慢,要数秒钟才能完成。客户那边处置这些问题的经验也十分丰富,很快就找到了等待这些闩锁的语句都是一条类似的语句,因为这条语句并没有试用绑定变量,所以每次都是硬解析。这个问题大概率是和解析有关。从D-SMART的问题分析报告中也能够找到出问题的这条SQL的情况。
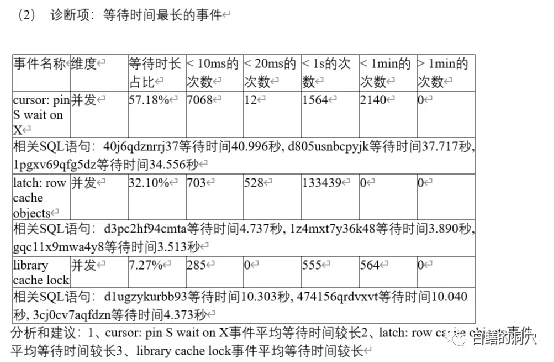
在这个分析里,我们的工具做的还不够细致,只是列出了问题,并没有做进一步的根因分析,这个案例也让我们发现了工具的不足。不过从这些列出的情况也可以看出解析一定是出了什么问题。因为当时这个问题已经影响了一些交易,因此需要马上先解决问题。客户那边分析后立即采取了一个措施,将cursor_sharing设置为similar,修改参数后,问题立即消失了,系统也恢复了正常。
事后我让客户把问题分析报告和当时的AWR报告发给了我,上班后,我们也会把这个案例的监控数据带回来仔细分析分析。这种特殊的案例对于完善知识图谱是十分关键的。这些年我们已经很少发现因为硬解析而引发的性能问题了。一般来说,以目前的PC服务器的硬件来说,因为CPU的核数较多,硬解析带来的问题已经越来越少了,因为一次解析的时间也就是几个毫秒到几十毫秒,强大的硬件资源足以支撑十分高并发的解析。不过问题并不是那么简单的,昨天的这个案例就是一个十分珍贵的特例的案例,具有十分高的价值。
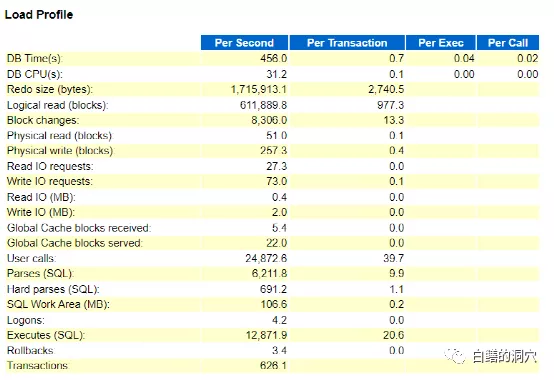
从load profile上看,系统负载还不算高,每秒600多的事务,12871的执行,数量只能算是中等。不过每秒6211次的解析说明无解析执行的比例很低,硬解析691,占11%多一点,解析数量很高,但是应该还不至于出现如此大的问题的。
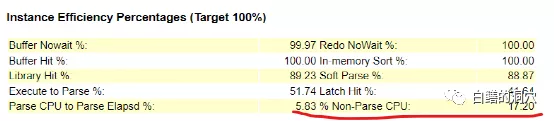
命中率指标有个十分大的疑点,那就是非解析CPU比例仅为17.2%,反过来看,就是解析占用的CPU资源高达83%左右,这是在以往的系统中很少会看到的现象。这是一台4路14核28线程的服务器,整个服务器有56个核,112线程,从D-SMART的报告中可以看出,CPU的使用率大概是在30%左右。
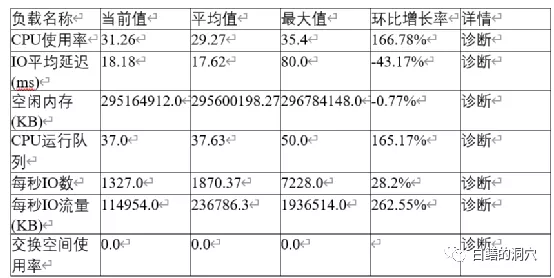
从操作系统层面上看,各种资源还是比较充足的,CPU的R队列最大值也没有超过CPU的线程数。按理说当前的硬件资源是足以支撑当时的并发解析的量的。实际上当时客户电话里和我沟通这个问题的时候,我也猜测了latch:row cache objects等待比较严重可能存在的几种问题,系统有HANG住的现象,SGA RESIZE,存在DDL操作,SGA设置太小等等。不过这些问题当时都查看过,而且也被一一排除了。
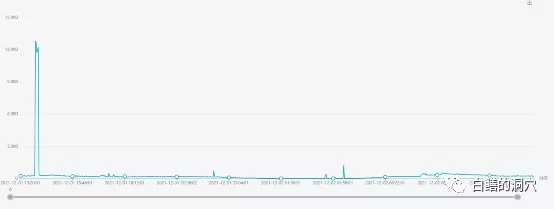
去年12月1日的历史数据
我们实验室正好有这套系统去年的历史数据,从历史数据上看,硬解析数量一直很高,甚至有时候高达12000+/秒,不过用户那边以前并没有发现其中存在什么问题。
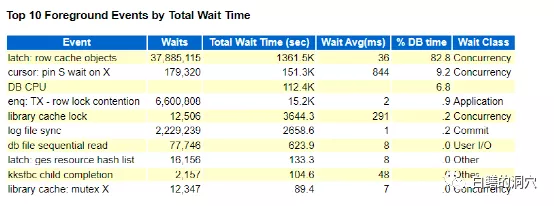
从TOP EVENT上看,latch:row cache objects的平均等待时间为36毫秒。似乎这个等待时间也不高,不过如果算上一个事务平均要等待10多次这个等待事件,对系统的影响就很大了。

平时这个等待时间的延时为0.13毫秒,偶尔会出现15多毫秒的点,不过一小时平均值36毫秒的情况还没有出现过。一下子暴增200多倍,导致系统异常也就很正常了。不过latch:row cache objects的延时为什么会达到这么高?执行数量过大,解析数量过大,硬解析过大吗?
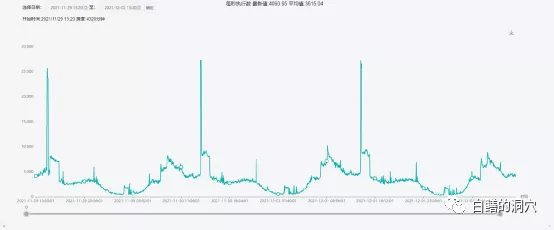
执行数量上看,这个系统每秒的执行数量平均值在3000-4000之间,出问题时段一小时平均值为1.2万多,是平时的3倍左右。不过平时的高峰期经常会有超过2.5万/秒的执行高峰,只是没有持续很长时间而已。
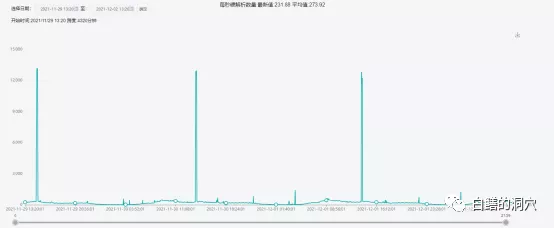
硬解析也是如此,平时的平均值大约略低于300,高峰期也会出现高达1.2万+的高值,也低于出问题时段的一小时平均值690+。
从这个案例最终通过修改cursor_sharing参数就解决了问题的现象上看,确实是这条没有试用绑定变量的SQL导致了问题,不过这个问题为什么会发生,其原因是十分复杂的。上面我们分析的持续的高峰是导致问题的一个十分重要的原因之一,不过这还不是所有的原因。
仔细分析和CURSOR解析相关的指标,我们发现每秒的session cache命中数量只有1700左右,和6000多的解析相比,命中率也很低,换算下来大概只有28%左右。而除了这条出问题的SQL以外的其他解析较高的SQL语句的解析数量占比大约是33%,根据这个情况我们检查了一下session_cached_cursors参数,发现这个参数使用了缺省的50。不过在这个案例里,加大这个参数能够发挥的作用可能还是有限的,不过在某些其他的案例里,类似情况可能会因为这个参数的设置不合理而加重SQL 解析的负担。
实际上这个看似并不复杂的案例里包含了很多复杂的内容,只有十分深入的去分析它,才能发现更深层次的问题。虽然说当时现场很快通过cursor_sharing解决了这个问题,但是如果没有把其中的问题分析清楚,今后遇到类似的问题,我们就无法提前预警,此类问题稍微发生一些变化,我们就无法正确的去处置。因为此类问题的表象上十分类似,而实际上深层次的内容上存在极大的不同。
这也是故障自动化分析比较难做的主要原因,同样是硬解析,为什么有的系统每秒数千次都不会出问题,而这个系统才700就出问题了呢?这和这台服务器的配置、CPU使用率、SQL涉及的表的数量,是不是存在分区数量极多的分区表等等,以及和昨天这个案例类似的是否存在持续时间很长的,针对同一张表的高并发解析,这些因素都有关系。如果在分析的时候要考虑到这些因素,那么我们需要更为准确的采集到相关的数据,并进行指标化处理,并通过指标来反映出这些问题的因素,在分析算法中也需要覆盖这些指标。
这种自动化分析能力只能在一次次的不尽如人意的分析中不断地迭代优化,才能获得更为准确的自动化分析工具。就像今天我们讨论的这个案例,虽然说好像现在看,问题已经分析的差不多了,而且当时发现问题和解决问题也很及时。不过我感觉我们还是没有抓住问题的最根本的那个点,因此我们还需要通过在用户现场更广泛的采集数据,从而找到更深层次的问题原因。只有不断地从这样的案例中去不断地挖掘知识,我们的知识图谱才能变得更有价值。
本文转载自微信公众号「白鳝的洞穴」,可以通过以下二维码关注。转载本文请联系白鳝的洞穴公众号。