机器学习方法在生命、物理、社会经济等复杂系统的应用日渐频繁。如何针对特定任务选取合适的机器学习方法,如何综合利用各类机器学习方法并各取其所长,成为机器学习领域的热点问题。近日发表在 PNAS 的一项研究开发了一种名为转换机器学习的方法,能够综合利用多个相关任务的数据及多种学习方法,提取编码于训练模型中不同来源的先验知识,尤其适用于药物设计等对可解释性有强需求的科学研究领域。更具有普适性的是,转换机器学习提出了机器学习生态系统构建的新思路,学习任务、实例、方法、预测结果及元学习能够相互促进,共同提升机器学习生态系统中所有任务的性能和可解释性。

论文题目:
Transformational machine learning: Learning how to learn from many related scientific problems
论文链接:
https://www.pnas.org/content/118/49/e2108013118
目 录
摘要
意义
1. 转换机器学习简介
2. 转换机器学习与其它方法的对比
3. 转换机器学习可改进原有算法
4. 转换机器学习的可解释性
5. 转换机器学习与深度神经网络的对比
6. 构建机器学习的生态系统
7. 数据集,代码与模型的开源
翻译名词对照
几乎所有的机器学习都基于内生 (intrinsic) 特征来表征训练数据。当存在多个相关的机器学习任务 (问题) 时,可以先在目标任务外的其余任务上训练机器学习模型,将内生特征转化为外生 (extrinsic) 特征,并用训练后的机器学习模型在目标实例上进行预测,产生新的表征,我们称其为 转换机器学习 (transformational machine learning,TML) 。转换机器学习与迁移学习 (TL) 、多任务学习 (MTL) 和叠加学习 (stacking) 密切相关,并具有协同作用,可用来改进任何非线性的机器学习。我们使用最重要的几类非线性机器学习来评价转换机器学习:随机森林 (RF) 、梯度提升机 (XGB) 、支持向量机 (SVM) 、k-最近邻 (KNN) 、神经网络 (NN) 。为了保证评价的通用性和鲁棒性,我们利用了来自药物设计、基因表达预测和机器学习算法选择这三个科学领域的数千个机器学习问题。
我们发现,转换机器学习在所有领域均显著提高了所有机器学习的预测性能 (平均提高4% 至50%) ,并且转换机器学习识别出的特征通常优于内生特征。转换机器学习作为可解释的机器学习,还能够增加科学认识。在药物设计中,我们发现转换机器学习提供了关于药物靶标特异性、药物间关系以及蛋白质靶标间关系的新知。转换机器学习创建了一种基于生态系统的机器学习方法,在这种方法中,新的任务、实例、预测等相互协同,以提高预测性能。
机器学习是人工智能的一个分支,目标是开发能从经验中学习的计算系统。在有监督机器学习中,机器学习系统从有标签的数据中,得到一个可泛化的预测未知数据标签的模型。数据通常用直接描述实例的特征来表征。例如,在药物设计中,机器学习会将药物的分子结构作为特征。在存在多个相关机器学习问题的情况下,可以使用一种不同类型的特性,即通过机器学习模型对其它问题下的数据做出预测,我们称之为转换机器学习。我们表明,当应用于科学问题时,该范式会带来更好的预测性和可理解性。
1. 转换机器学习简介
机器学习开发从经验中学习的计算系统。它在科学领域的应用有着悠久的历史[1-4],最早的一种机器学习程序是 Meta-Denral,它使用机器学习来改进质谱数据分析[5]。机器学习对科学的重要性已被广泛认可,且正被用于几乎所有的科学领域,例如药物发现[6]、有机合成规划[7]、材料科学[8]、医学[9]等。
大多数机器学习使用特征元组表征训练数据,例如,数据可以放到单个表中,每一行代表一个实例,每一列代表一个特征。实例的特征也可称为属性 (attributes) 。目前,实例的特征几乎都是内生属性。例如,如果某人希望了解一种药物的药理活性,那么药物的分子结构就是该实例有用的属性。通常,选择一个特征作为预测值,其它属性则提供用于预测的信息。如果待预测的属性是标签,那么这是判别/分类任务;如果待预测的属性是实数,那么这是回归问题。该研究主要讨论回归问题。
当存在多个相关的机器学习任务时,外生特征也可能被用到:使用在其余任务上训练的机器学习,来对目标实例进行预测 。我们称之为转换机器学习。转换机器学习将基于内生属性的表征,转换为基于其余模型预测值的外生表征。我们接下来会论述,转换机器学习和迁移学习、多任务学习和叠加学习有密切的协同关系。它使得模型可以利用在其余相关任务中学到的的知识,而不必从头开始学习。因此,转换机器学习属于元学习 (meta learning) 的范式,可改进任何非线性的机器学习算法,尤其适用于存在许多相关小型学习任务的场景。
直观地说,以识别多种动物的学习任务为例。如果需要识别多种动物,并且还有待添加的物种,那么相比采用一个大型分类器而言,对每个物种都采用独立的分类器更合理。标准的机器学习方法采用内生特征 (例如动物是否有皮毛、皮毛的大小) 来训练分类器。转换机器学习则是先采用标准方法 (图1A左) 学习各种动物的预测模型,并使用基于这些模型的预测结果表征各种动物。比如,在通过标准方法获得类马程度、类猫程度、类兔程度等表征后,再以此训练 (元) 机器学习模型 (图1A右) 。转换机器学习适用于所有机器学习任务共享一组内生特征和目标变量的领域,而这在科学研究中很普遍,例如在药物设计中,需要将化合物的分子表征与靶标 (蛋白质) 相匹配 (图1B) 。 转换机器学习的有效性在于利用了编码于先前训练模型中关于世界规律的知识。
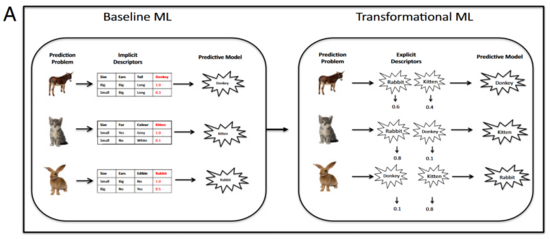
图1A. 标准机器学习和转换机器学习在预测动物物种上的对比。通过三个机器学习任务的实例来阐述转换机器学习:预测动物是驴、猫还是兔。标准机器学习以内生特征,如体型、耳朵、是否可食用来构建预测模型:驴( ),兔( ),猫( )。将内生特征输入模型兔( ),输出动物为兔子的概率。这三个模型的结果会作为训练转换机器学习的外生特征。直觉上,可以看到转换机器学习的表征是有意义的,因为兔和驴有相似之处,都有长耳朵,兔和猫的相似处在于体型都小且可爱。因此转换后的外生表征能够捕捉原始描述所不涉及的特征,例如是否可爱、眼睛是否位于头部两侧(兔和驴共有的特征)。
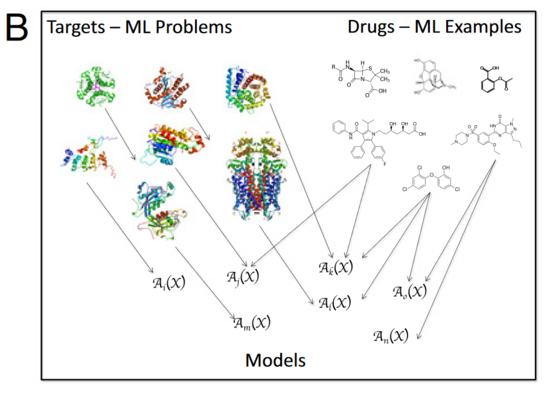
图1B. QSAR(结构-活性定量关系)学习。QSAR预测模型给定一个靶标(通常是蛋白质)以及一系列化合物(小分子)及其对应活性(如抑制特定蛋白),以此学习从化合物分子表征到活性的映射。
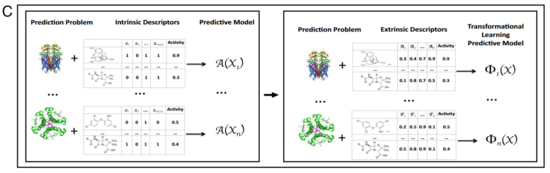
图1C. 标准机器学习和转换机器学习在QSAR上的对比。使用标准机器学习,每个靶标和多种药物的内生特征关联,例如是否包含特定的分子群,以此训练模型建立从分子表征到活性的映射。
2. 转换机器学习与其他方法的对比
转换机器学习与其它机器学习方法有非常相似的地方。然而,具体的转换机器学习概念之前没有被系统性的地评价过。
转换机器学习与 多任务学习 [10]非常相似。多任务学习是“一种以相关任务的训练数据中包含的领域信息为归纳基准,从而提高泛化能力的归纳迁移方法”。在多任务学习中,相关问题 (任务) 是被同时学习的,目的是利用问题之间的相似性来提高预测性能。多任务学习以共享表征并行训练,来达成该目标;从每个任务所学到的知识可以帮助其它任务学得更好[10]。多任务学习和转换机器学习之间有两个主要区别:多任务学习的训练通常是并行的,而转换机器学习通常逐个进行训练;转换机器学习在各个任务间共享数据表征,而多任务学习则使用单一模型。
转换机器学习还与 迁移学习 [13]有密切的关联。迁移学习将信息从特定来源的问题转移为特定目标的问题。迁移学习的思想是从一个或多个源领域提取知识,并在数据稀缺的目标领域复用这些知识,从而在目标领域建立性能更好的学习模型。但是迁移学习通常不同于转换机器学习,因为迁移学习只针对一个源任务,而转换机器学习需要应对多源任务。迁移学习已成功应用于药物设计,几个前瞻性的应用证明了其有效性[15]。
转换机器学习与 叠加学习 [16,17]也非常相似,后者是一种集成机器学习算法。叠加学习结合多种算法,以获得比单独使用任何一种算法更好的预测性能。在叠加多个基准模型时,首先训练基准模型,然后使用基准模型的输出训练元模型。转换机器学习和叠加学习的主要区别在于,转换机器学习的训练是在一大组相关任务上进行,每个任务对应的训练集可能不同。而在叠加学习中,不同的基准模型通常针对同一个任务进行训练。
3. 转换机器学习可改进原有算法
转换机器学习适用于任何非线性机器学习的改进。为了评价转换机器学习,我们选择了5种机器学习[1-4]:随机森林 (RF) [21]、梯度增强算法 (XGB) [22]、支持向量机 (SVM) [23]、k-最近邻 (KNN) [3]和神经网络 (NN) [3,4]。为了确保评价的普遍性和鲁棒性,我们利用了来自三类重要科学问题——药物发现 (QSAR 学习,即定量构效关系) 、类基因表达的预测 (跨越不同组织类型和药物治疗) 、元机器学习 (预测机器学习方法解决问题的效果) ——的数千个机器学习任务。
对于每一种机器学习方法和每一个问题领域,我们比较了转换机器学习和基准机器学习算法的表现。我们研究了两种形式的预测改进:强改进和联合改进。强改进即使用新的转换机器学习特征,得出的预测优于使用基于基准 (内生) 特征的得出预测。联合改进即以基准特征作为新的转换机器学习特征,以提高预测性能。为了增强转换机器学习预测性能,我们使用了最简单的叠加方法:组合预测结果。我们发现,转换机器学习在三个领域中均显著提高了所有方法的平均预测性能 (提高幅度从4% 到50%) ,即针对新的外生特征训练的模型通常优于针对内生特征训练的模型 (表1) 。
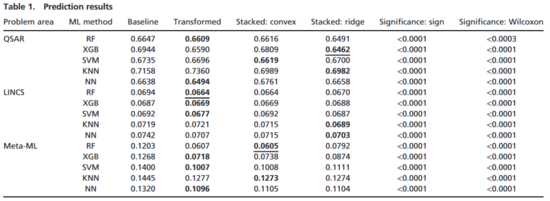
表1. 预测结果,表中数值为均方根误差(RMSE)。加粗的数值为某应用场景下的最优结果。基准结果使用标准内生表征及对应的机器学习算法得出的结果。转换机器学习使用外生表征得出结果。均方根误差为各应用领域中数千次任务的平均值。我们测试了两种叠加方式:最小二乘法(convex squares)(非负最小)和岭回归(ridge regression)。我们使用了两种显著性检验:t 检验和 Wilcoxon 检验。两种方法都检验了标准方法与转换机器学习之间均方根误差的差异是否显著(p< 0.05),前者检验了两种方法的均方根误差中位数是否存在统计上的差异,后者检验了两种方法的均方根误差平均数是否存在统计上的差异。
几乎所有的统计方法和机器学习方法都被应用于 QSAR 问题[23] ,但是仍未发现一种最好的方法[24,25]。 QSAR非常适合应用转换机器学习,因为药物分子表征可以通过相关的靶蛋白而相互关联 。例如,在小鼠和人类中抑制二氢叶酸还原酶 (DHFR ) 的问题是相似的,因为两者有相似的配体结合位点[活性中心][26],而且它们涉及的分子相同或相关[26 -28]。为了评价用于 QSAR 学习的转换机器学习,我们使用了2219个 QSAR 问题[24,25]。QSAR 基准 (内生) 表征是1024位的分子指纹表征,这已经被证明是有效的[25]。对于每种基准机器学习算法 (RF,SVM,k-NN 和 NN) ,我们使用先前训练的模型所预测的化合物活性,获得转换机器学习的外生特征。然后使用基准机器学习方法训练 QSAR 模型。在所有方法中,转换机器学习预测效果均优于基准算法。有关结果见表1。我们发现总体结果最好的是叠加了梯度提升机的转换机器学习模型,其结果相较于基准梯度提升机提升了7%,其次是叠加了神经网络的转换机器学习模型。值得注意的是,该数据集已被广泛研究[18种学习方法和6种分子表征[25]] ,并且转换机器学习显著优于之前的最佳结果。
对于第二个问题领域,我们使用了基于集成网络的细胞特征数据库 (LINCS) [29] ,它描述了在118050个实验条件下测量的978个标志性人类基因的表达水平。我们将机器学习任务看作是在给定实验条件 (细胞类型、药物和剂量) 下,为每个基因建立一个能够预测其表达水平的模型。 基因表达预测问题也适合转换机器学习,因为存在基因间关系 (同源性、共同信号通路等) 和实验条件间关系 (药物相似性等) ,可用于提高预测性能。使用与 QSAR 问题相同的方法,我们使用随机森林、支持向量机、k-最近邻和神经网络进行了比较评价,比较了使用内生表征和转换机器学习表征的模型,结果见表1。所有方法中,使用转换机器学习的模型都优于基准机器学习。我们发现,随机森林的总体结果提升最大,相比基准提升了4% ,其次提升较大的是梯度提升机和支持向量机模型。
第三个评价问题领域来自机器学习, 其基本问题是选择适用于新任务的最佳机器学习算法。机器学习是解决该问题的一个有效途径,这被称为元机器学习 。机器学习模型的任务是:给定训练数据的特征 (例如训练数据的统计分布) ,学习一个用于预测机器学习算法在新任务 (给定特定的任务) 上性能的元模型。这一场景也适合转换机器学习,因为机器学习任务可以通过具有类似的数据分布和数据属性 (如缺失值) 或包含由相似过程生成的数据而发生关联。从 OpenML[31]中,我们对351个任务和53个机器学习方法进行了10840个评价,产生了351个元学习任务,结果见表1。在所有方法中,使用转换机器学习特征的算法都优于基准机器学习算法。总体来看,提升最大的是使用转换机器学习的随机森林,相比使用内生特征的算法提高了50% 。使用转换机器学习特征的梯度提升机也比基准算法有相似程度的提升,对于支持向量机和神经网络,使用转换机器学习特征后,性能也有提升。对于 k-最近邻,叠加转换机器学习特征的效果最好。相比之前描述的场景,使用转换机器学习特征,预测性能提高的百分比要大得多。这可能是因为原始 (内生) 特征对训练数据集的描述较差,而转换机器学习特征编码了更多关于算法在不同任务中的隐含信息。此外,相比之前的场景,预测性能的实验噪音较小。
4. 转换机器学习的可解释性
机器学习的一个越来越重要的分支是可解释的人工智能,因为在许多应用 (例如医学或金融) 中,有必要使预测具有可理解性。在科学领域,可解释的机器学习预测模型会带来科学新知。机器学习模型的可理解性取决于模型的简单性,及模型表征与人类概念间的密切程度。概念结构的标准理论起源于亚里士多德,以定义和解释概念间存在充分必要条件为基础。 转换机器学习模型的可解释性基于相似概念存在多种可替换的学习方法 [33,34]。
在药物设计领域利用随机森林模型,我们说明了转换机器学习模型能够以三种方式产生科学新知。首先,我们阐明了如何使用转换机器学习模型为特定药物靶标 H. sapiens DHFR 的 QSAR 预测提供解释。表2列出了对 H. sapiens DHFR 药物活性预测最重要的10个特征 (基准模型) 。正如所料,该列表中还有其它 DFHR 靶标的模型。但有趣的是,这些模型是细菌 ( L. casei,E. coli ,和 M. avium ) 的模型,而不是哺乳动物的模型。这三个细菌的 DHFR 模型对人类 DHFR 的预测有所贡献,其中 L. casei 的DHFR最像人类,而 E. coli 和 M. avium 的DHFR 明显不同,因为E. coli DHFR 与甲氧苄氨嘧啶抗生素结合紧密,而 M. avium 的 DHFR 具有耐药性。这些信息有助于设计人类 DHFR 抑制剂,以更好地治疗癌症。表2中的其它特征也提供了类似的洞见。
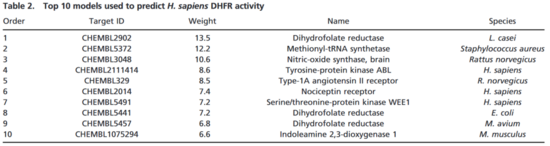
表2. 预测人类 DHFR活性最佳的十种模型
转换机器学习也可以通过聚类 (非监督学习) 提供科学新知。化学信息学中一个基本问题是估计化合物之间的相似性。标准方法基于化学结构的相似性来估计化合物间的相似性,比如根据分子指纹和图相似性上的 Tanimoto (Jaccard) 系数距离估计。然而,当比较药物时,功能相似性而不是结构相似性更受关注[15]。功能相似性可以使用实验积累的信息来度量,这些信息被编码于 QSAR 模型中,可用于预测药物针对靶标的活性 (图2A) 。该预测结果可用于计算药物和它们药理特征间的距离。图2B使用转换机器学习,将美国食品药物管理局 (FDA) 批准的药物聚类成三簇。尽管这些化合物的药理学关系很复杂,但这些药品都与血清素和多巴胺受体相互作用有关。可以使用转换机器学习对这一相互作用进行预测,并将其用于聚类。可以根据聚类后化合物的相对位置,预测不同化合物的药理学特征。
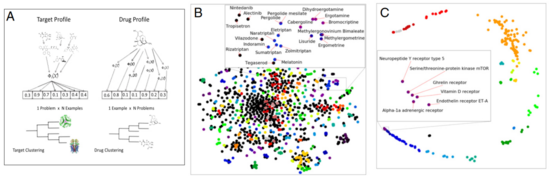
图2.(A)转换机器学习在聚类分析中的应用 ,通过对药物分子进行表征来对药物聚类。在这些表征中,每个元素都是药物对其中一个靶标(问题)的预测值。
(B)通过化合物在 QSAR 靶标的预测活性对化合物聚类。该图显示了获得 FDA 批准的化合物(颜色代表簇)的聚类,以及三个密切相关的簇和放大的单簇。
(C)通过化学表征对药物靶标聚类。该图显示了 FDA 批准的药物的蛋白质靶标的整体聚类(颜色代表簇)和一个单簇的放大部分。
我们应用类似的方法来估计蛋白质靶标相似性这一生物信息学问题 (图2C) 。该任务的标准方法是使用序列对比估计进化距离。然而,在大多数问题中,最重要的不是进化距离,而是蛋白质活性位点的功能相似性。我们可以使用转换机器学习 QSAR 模型中积累的信息估计功能相似性。我们刻画了每一个靶标的药物活性预测,即 FDA 批准的化合物对靶标的活性预测。和化合物相似性预测一样,我们认为药物设计的聚类比传统的进化距离提供了更多的洞见,因为它是基于靶标对化合物的实证响应得出的。QSAR 相似性预测模型识别出的一个有趣的蛋白质 (药物靶标) 团簇如图2C 所示。尽管这一组蛋白质没有任何明显的结构相似性,但这些 (哺乳动物) 蛋白质的功能与新陈代谢控制有着明确的关联。
5. 转换机器学习与深度神经网络的对比
将转换机器学习与当前最重要的机器学习算法——深度神经网络 (DNNs) [35]进行比较是很有启发性的。DNN 的输入是典型的空间结构或顺序结构,输入结构的先验知识被编码于网络结构。DNN 的成功在于它能够利用多个神经网络层和大量数据,学习如何将较差的输入表征 (如图像像素值) 映射到丰富和有效的潜在表征。这是通过使用可微学习模型和端到端学习来实现的。改善较差输入表征的能力,使 DNN 能够在原先被证明不适合机器学习的领域取得成功:例如在围棋[36]等游戏中击败世界冠军,比人类专家更好地诊断皮肤癌[9]。 从 DNN 的成功中得到的一个关键经验是,利用机器学习能够增强机器学习的表征,而这正是转换机器学习所做的事情 。DNN最适用于有大量可用于训练良好表征的数据,并且不要求所用符号模型适于人类认知的问题。而大多数科学问题领域都不满足这些标准。
标准 DNN 算法在需要处理多任务问题时,需要学习包含所有问题的单一大型模型。与转换机器学习相比,DNN 问题间的关系和训练数据间的关系都不是以转换特征的形式外显化的。对于多任务问题,转换机器学习还具有支持增量机器学习的优势:如果添加新数据或新任务,那么无需重新学习任务模型。虽然转换机器学习增加了一些额外的计算代价,但是与 DNN 学习相比,转换机器学习的额外代价很低。
6. 构建机器学习的生态系统
机器学习的传统方法是将每个学习任务看作一个单独的问题。随着多任务学习[10]、 迁移学习 [13]、终身学习 (life-long learning) [37]等方面的进展,这种观点开始发生变化。 转换机器学习使我们对作为生态系统的机器学习有了更广阔的视野。在这个生态系统中,学习任务、学习实例、机器学习方法、机器学习预测、元机器学习方法等等都能够协同作用,以提升生态系统中所有任务的性能和可解释性 。增加更多的训练数据,不仅能够改进特定任务的模型 (使用特征选择、集成学习、叠加学习、转换机器学习、二阶转换机器学习等) ,还能改进所有其它使用特定任务模型的模型 (转换机器学习、二阶转换机器学习等) 。与此类似,添加了新任务能够扩展转换后的表征,从而可通过转换机器学习、二阶转换机器学习等方式改进所有其它任务的模型。添加新的机器学习或元机器学习方法,那么所有的任务模型都会得到改进。在这样一个机器学习生态系统中,随着新知识的增加,预测性能将逐步提高[38]。因为来自许多不同来源的先验知识被用于所有预测任务中[38],预测也将更加可靠。
在机器学习领域,人们对 机器学习的自动化 越来越感兴趣,并且存在许多或免费或商业的系统,这些系统能够自动进行机器学习以解决新的问题。例如,Auto-WEKA 和 Auto-sklearn [39]通过搜索可能的机器学习方法和超参数空间来优化机器学习的预测性能。然而,目前还没有一个机器学习自动化系统,能够发现一个有价值的机器学习新技巧,例如dropout、叠加等。尽管目前有越来越多将科学发现自动化的人工智能系统[40] ,但这些系统高度依赖机器学习,而很少有工作将人工智能发现系统应用于机器学习。发展能够发现重要机器学习新技巧的机器学习系统,将改变机器学习和整个世界。
7. 数据集,代码与模型的开源
为实现可重复性,本文所涉及的数千个数据集 (QSAR,LINCS,Metalearning) ,代码的链接 (TML,RF,XGB,SVM,k-NN,NN) ,以及包括所有决策树的约50000个随机森林模型都可以在开放科学平台 (Open Science Platform,OSP) 的知识共享许可协议数据库中获得:https://osf.io/vbn5u/。总共有约100 GB 的压缩数据。 很少有机器学习项目能将如此多的可重复数据放到网上 。为了最大化其附加价值,我们遵循了公开数字对象的FAIR原则 (Findability,Accessibility,Interoperability,and Reusability,即可发现,可访问,可互操作,可重用) [41]。
翻译名词对照
TL:transfer learning,迁移学习
MTL:multitask learning,多任务学习
RF:random forests,随机森林
XGB:gradient boosting machine,梯度增强机
SVM:support vector machine,支持向量机
KNN:k-nearest neighbors,k-最近邻
NN:neural network,神经网络
DNN:deep neural network,深度神经网络
QSAR:Quantitative structure–activity relationship,定量构效关系