












本文转载自微信公众号「Code视角」,作者Code视角。转载本文请联系Code视角公众号。
什么是无锁编程
LOCK-FREE,字面解释就是不通过锁来解决多线程、多进程之间的数据同步和访问的程序设计方案。相对来说就是通过数据结构和算法来解决数据并发冲突的实现方案。
无锁编程的实现
「比较并交换 Compare-and-swap」
compare and swap,解决多线程并行情况下使用锁造成性能损耗的一种机制,CAS操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在CAS指令之前返回该位置的值。CAS有效地说明了“我认为位置V应该包含值A;如果包含该值,则将B放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。(百度百科)
参考图
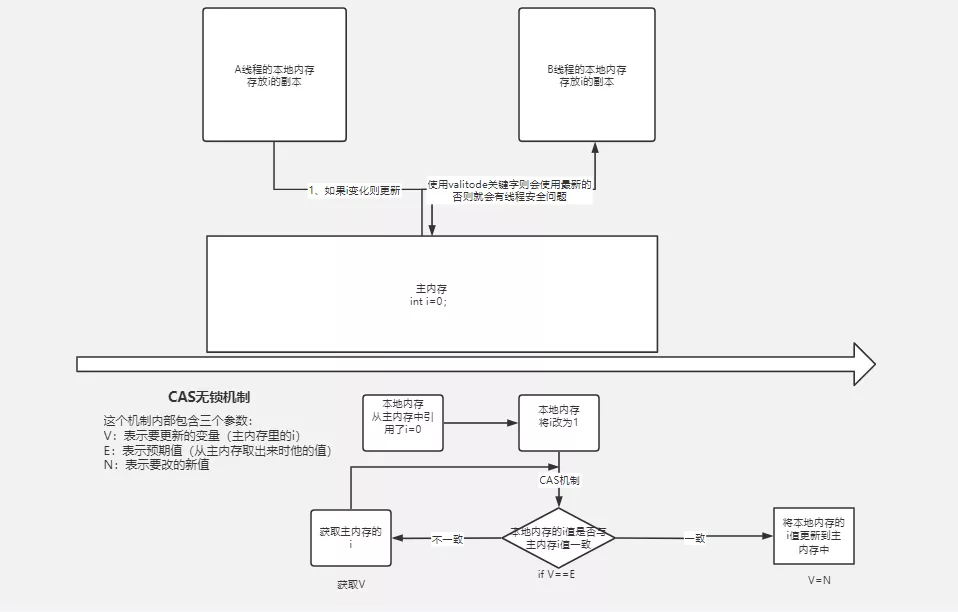
使用场景
(1) 乐观锁的实现方案:不加锁,假设没有冲突去完成某项操作,如果因为冲突失败就重试,直到成功为止。
缺点
(1)循环开销问题。长时间更改不成功,会来带大量的CPU消耗。解决方法:需要在修改失败后执行其它逻辑, 且CAS并不适合资源大量竞争的情况。
(2)ABA问题:线程1准备用CAS将变量的值由A替换为B,在此之前,线程2将变量的值由A替换为C,又由C替换为A,然后线程1执行CAS时发现变量的值仍然为A,所以CAS成功。但实际上这时的现场已经和最初不同了。
「数据Hash」
数据Hash其实就是通过Hash算法把数据提前来确定由哪个节点进行处理或者存储,解决数据并发的思想是通过算法解决不同的数据到不同的节点。算法:数据.hashCode() % 节点数量。
参考图
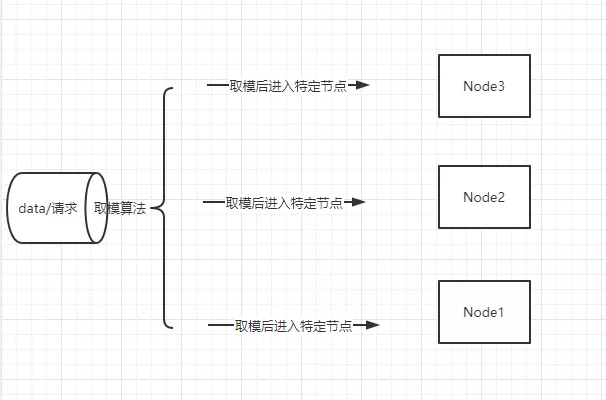
使用场景
(1)定时任务处理数据时。例如:一个定时任务数据量较多,需要集群处理。那么就可以同时启动任务读取数据,然后根据idHash来决定当前节点是否要处理这条数据。
(2)请求到指定服务器进行处理。例如:Nginx ipHash转发策略,Kafka hash分区保证分区有序性。
缺点
(1) 扩容相对复杂,需要进行数据迁移。例如一致性hash算法,Kafka分区再均衡策略。但是某些场景不一定支持扩容。
(2) hash算法是否散列,如果算法不够散列会出现数据倾斜问题。
「单线程」
某些场景下单线程的设计要比多线程更加优秀, 单线程下不存在资源竞争、线程切换,当然也取决于你当前的服务器配置。
例如:
(1)Redis的设计上,由于内存级别的K/V数据库,在处理核心读写时如果频繁的CPU切换、线程等待唤醒和锁资源获取,反倒会造成性能瓶颈。
(2)在生成分布式id的场景下, 某台id服务器批量生成id 这个时候也可以进行单线程处理,内存计算非常高效。
什么时候使用单线程?
(1)单核服务器。
(2)业务场景大量CPU计算且数据冲突较多的情况下(非绝对)。
无锁编程的优缺点
「优点」
不会有优先级倒置。
不会出现死锁、饥饿、饿死等问题。
减少资源竞争,CPU资源消耗少,更高效。
「缺点」
具有一定的复杂性,需要一定的算法思想。
不适合所以的场景,非全局最优解。
总结
在设计程序时, 应该考虑程序的使用场景来进行最优的数据结构和算法来进行方案设计。无锁编程也只是解决某些场景的一种方案,并不一定代表着最优解。
结语
优秀的设计模式结合优秀的数据结构相才能带来优秀的代码。编程人的内功心法:数据结构+算法。























