大家好,我是Python进阶者。
前言
前几天在学习【麦叔】Python自动化书本中案例的时候,学到了PDF文件处理,感觉挺有意思的。正好在【J哥】的交流群里边有粉丝问了一道关于PDF处理的问题。
这个问题如果没有学点PDF的处理,一开始看到还是觉得有点困难的,我一开始也有点束手无策。
一、思路
针对这个问题,其实我有三个思路。
第一个思路:将pdf文件一进行分割成单独文件,之后和pdf文件二进行排序放到一个文件夹下,再统一进行merge;
第二个思路:尝试用merge进行合并,直接插入到文件的指定页面之下,但是我目前对这个用的不是很好,没有弄出来;
第三个思路:逐页进行添加,并保存为新文件。
二、解决方案
针对该问题,这里采用了第三个方法,最为自然,也是三个方法中最简单的一个了。这里需要用到PDF的处理库PyPDF2,这个库需要安装,安装命令:pip install PyPDF2
这个库针对PDF的处理来说还是算比较强大的了,可以针对PDF文件做拆分、合并、加密和截取等。关于这个库的其他用法,很多公众号也有写,这里就不展开赘述了。
针对这个问题,这里直接上代码了,如下所示:
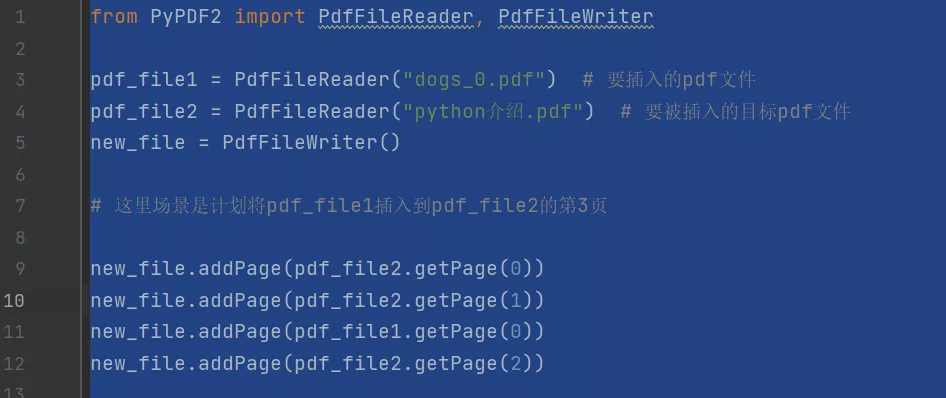
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_file1 = PdfFileReader("dogs_0.pdf") # 要插入的pdf文件
pdf_file2 = PdfFileReader("python介绍.pdf") # 要被插入的目标pdf文件
new_file = PdfFileWriter()
# 这里场景是计划将pdf_file1插入到pdf_file2的第3页
new_file.addPage(pdf_file2.getPage(0))
new_file.addPage(pdf_file2.getPage(1))
new_file.addPage(pdf_file1.getPage(0))
new_file.addPage(pdf_file2.getPage(2))
# 写入文件
with open("merged_file.pdf", "wb") as f:
new_file.write(f)
关键的地方都有注释进行标注了,如果你需要插入的pdf原始文件页面太多的话,可以考虑循环遍历追加,这样就不至于写很多行代码了。
三、总结
我是Python进阶者。本文基于实际过程中遇到的PDF文件拆分和合并问题,使用了PyPDF2第三方库来帮助解决,这个库可以针对PDF文件做拆分、合并、加密和截取等,功能强大,帮助自己和大家加深对该库用法的认识。