












Node.js 为人所知的是单线程应用,也为人所知的是底层其实利用了多线程。单线程会使得代码实现上变得容易好理解,但是带来好处的同时,也往往会存在一些限制,这些限制导致在 Node.js 内核中,不得不引入其他子线程,最终形成多线程。本文介绍 Node.js 中的这些幕后英雄。
1 Libuv 线程池
Node.js 中,Libuv 线程池是最为人所知的子线程。Node.js 的整体架构是单线程 + 事件驱动,其本质是一个生产者消费者的模型。
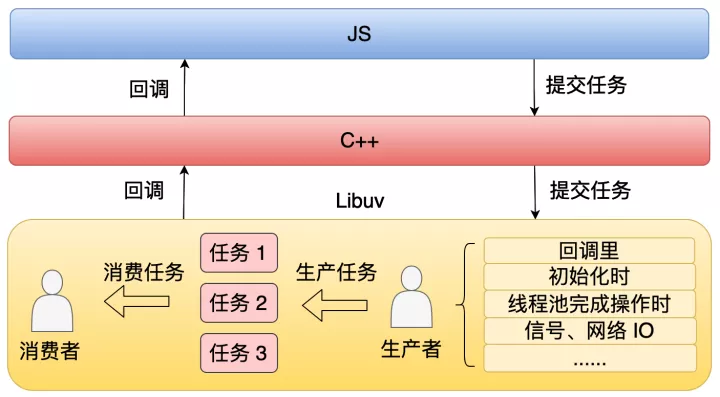
Node.js 不断通过事件驱动模块订阅 fd 的事件,然后等待 fd 对应事件的就绪,接着执行对应回调,通过事件驱动,Node.js 甚至实现了定时器的功能。但是事件驱动模块不是万能的,至少目前不是,也就是说事件驱动模块还无法支持所有的操作,那么这些操作就需要用额外的线程去完成。这是引入 Libuv 线程池的背景。具体来说,Libuv 用来处理文件 IO、DNS 和 CPU 密集型的任务。
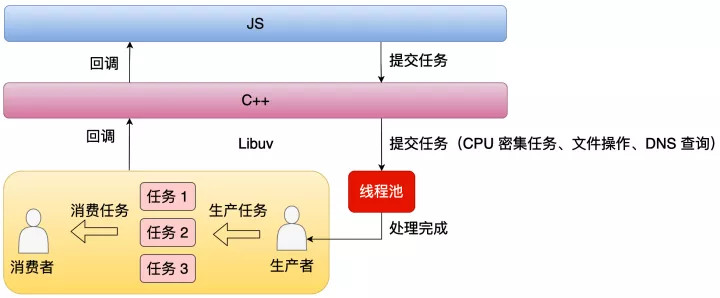
从上面图中可以看到,这些任务是直接提交给线程池处理的,等线程池把任务处理后,再通知主线程执行回调。所以底层虽然是多线程的,但是 Node.js 中,所有上层的代码都是在单线程(主线程)中执行的。下面以异步读文件为例看看大概的流程。
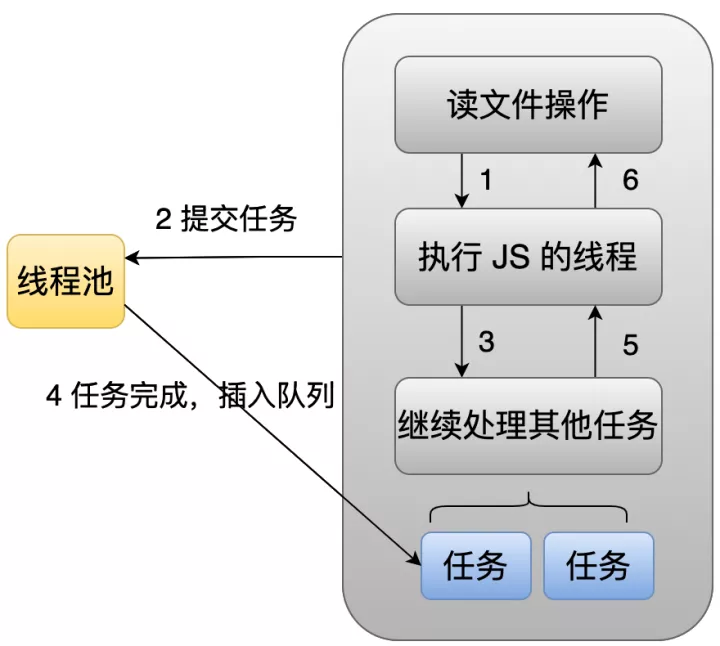
可以看到主线程提交任务给线程池后,就可以继续执行其他操作而不需要等待子线程完成,子线程完成任务后会以异步的方式通知主线程。
2 Watchdog
看门狗是计算机中的一个术语,大概就是定时做一些事情的一个程序,比如启动一个定时器定时检测系统是否运行正常,如果系统运行正常,则在定时器超时前重置定时器,如果系统挂了,则看门狗就会发出告警。在 Node.js 中也用到了看门狗。前面提到 Node.js 是单线程的,那么如何实现保证在某段时间内执行完一段代码呢?一旦我们把执行控制权交给某段代码,那么它什么时候结束就取决于这段代码的内容了,甚至如果它里面有个死循环,那么我们的系统也就无法做其他事情了。Node.js 提供了 API 处理这种情况。

Node.js 底层正是通过 watchdog 实现了这种能力,下面来看一下具体实现,下面是核心代码。
if (timeout != -1) {
Watchdog wd(env->isolate(), timeout, &timed_out);
result = run();
}- 1.
- 2.
- 3.
- 4.
run 函数实现了 js 代码的执行,在 run 之前定义了一个watchdog。我们来看看它的实现。
class Watchdog {
public:
explicit Watchdog(v8::Isolate* isolate,
uint64_t ms,
bool* timed_out = nullptr);
~Watchdog();
v8::Isolate* isolate() { return isolate_; }
private:
static void Run(void* arg);
static void Timer(uv_timer_t* timer);
v8::Isolate* isolate_; // 主线程 isolate
uv_thread_t thread_;// 子线程标识
uv_loop_t loop_; // 事件循环核心结构体
uv_async_t async_; // 子线程和主线程通信结构体
uv_timer_t timer_; // 注册于子线程的定时器
bool* timed_out_; // 标记是否超时了
};- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
从上面定义中可以看到,watchdog 会新建一个子线程然后在子线程里跑一个新的事件循环(Node.js 中很多这种用法),接着看具体的实现。
Watchdog::Watchdog(v8::Isolate* isolate, uint64_t ms, bool* timed_out)
: isolate_(isolate), timed_out_(timed_out) {
int rc;
// 初始化新的事件循环结构体
rc = uv_loop_init(&loop_);
// 初始化线程间通信结构体,并设置回调
rc = uv_async_init(&loop_, &async_, [](uv_async_t* signal) {
Watchdog* w = ContainerOf(&Watchdog::async_, signal);
uv_stop(&w->loop_);
});
// 在子线程的事件循环中初始化和启动定时器
rc = uv_timer_init(&loop_, &timer_);
rc = uv_timer_start(&timer_, &Watchdog::Timer, ms, 0);
// 创建子线程,并在子线程中执行 Run 函数
rc = uv_thread_create(&thread_, &Watchdog::Run, this);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
接着看一下 Run。
void Watchdog::Run(void* arg) {
Watchdog* wd = static_cast<Watchdog*>(arg);
uv_run(&wd->loop_, UV_RUN_DEFAULT);
uv_close(reinterpret_cast<uv_handle_t*>(&wd->timer_), nullptr);
}- 1.
- 2.
- 3.
- 4.
- 5.
在 Run 中进入事件循环。以此同时,主线程中也在执行 js 代码。随着时间的流逝,有两种情况,第一,js 代码在定时器超时前执行完,回头看看定义 watchdog 的代码是包裹在一个 if 里的,run 执行完后就会离开 if 作用域,从而析构 watchdog。我们看看析构函数的逻辑。
Watchdog::~Watchdog() {
// 通知子线程退出
uv_async_send(&async_);
// 等待子线程退出
uv_thread_join(&thread_);
uv_close(reinterpret_cast<uv_handle_t*>(&async_), nullptr);
// UV_RUN_DEFAULT so that libuv has a chance to clean up.
uv_run(&loop_, UV_RUN_DEFAULT);
CheckedUvLoopClose(&loop_);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
析构函数里通过 uv_async_send 通知子线程退出,看一下回调。
uv_async_init(&loop_, &async_, [](uv_async_t* signal) {
Watchdog* w = ContainerOf(&Watchdog::async_, signal);
uv_stop(&w->loop_);
});- 1.
- 2.
- 3.
- 4.
回调里执行 uv_stop 结束子线程中事件循环的运行,最终退出子线程。第二种情况就是 js 代码过久,然后子线程定时器超时,来看一下超时回调。
void Watchdog::Timer(uv_timer_t* timer) {
Watchdog* w = ContainerOf(&Watchdog::timer_, timer);
*w->timed_out_ = true;
w->isolate()->TerminateExecution();
uv_stop(&w->loop_);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
回调里通过 isolate 的 TerminateExecution 函数终止 js 代码的执行,然后继续执行主线程后面的代码,而子线程也完成了自己的使命。
3 Inspector
调试 js 时,我们通常会打很多断点,当代码执行到断点时,整个线程就会停住,我们就可以查看当前的栈和信息。如果这时候我们想关闭调试功能,可能会发现无法关闭,因为整个线程都停在断点处了,虽然我们可以直接关闭调试客户端,但是真实情况可能比较复杂,比如多人打开了调试器,我们却只能关闭自己的。另外,如果我们的代码陷入了死循环,那么连打开调试功能的机会都没有了。这是单线程导致的问题,所以 Node.js 中的调试功能是以独立的线程实现的。在 Node.js 中我们可以通过很多种方式打开调试功能。比如在启动 Node.js 时通过加入命令行参数,在代码里通过 inspector 模块的 open 函数,通过给 Node.js 进程发送 SIGUSR1 信号(这种方式可以在主线程死循环的情况依然可以生效)。这些方式对应的实现都是一样的。
uv_thread_create(&thread_, InspectorIo::ThreadMain, this);- 1.
Node.js 会创建一个新的线程运行调试相关的代码。
void InspectorIo::ThreadMain() {
uv_loop_t loop;
loop.data = nullptr;
int err = uv_loop_init(&loop);
// 获取调试的 host 和端口
std::string host;
int port;
{
ExclusiveAccess<HostPort>::Scoped host_port(host_port_);
host = host_port->host();
port = host_port->port();
}
// 创建服务器,往事件循环注册 fd
InspectorSocketServer server(std::move(delegate),
&loop,
std::move(host),
port,
inspect_publish_uid_);
server.Start();
// 启动事件循环
uv_run(&loop, UV_RUN_DEFAULT);
CheckedUvLoopClose(&loop);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
具体就不多介绍了,主要是开了子线程避免了主线程阻塞时所带来的限制。另外多提一下就是通过信号打开调试器的实现。哪怕进程陷入了死循环,也是会处理收到的信号的,因为操作系统在进程调度时,选中某个进程后,在执行前会先处理信号。所以如果 Node.js 进程如果正在陷入死循环,通过信号机制,我们依然有机会执行一些代码。接下来看看这时候 Node.js 都执行了什么代码。首先 Node.js 在初始化时先创建了一个线程。
pthread_create(&thread, &attr, StartIoThreadMain, nullptr);
inline void* StartIoThreadMain(void* unused) {
for (;;) {
uv_sem_wait(&start_io_thread_semaphore);
Mutex::ScopedLock lock(start_io_thread_async_mutex);
Agent* agent = static_cast<Agent*>(start_io_thread_async.data);
if (agent != nullptr)
agent->RequestIoThreadStart();
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
这个线程被创建后通过 uv_sem_wait 把自己阻塞,等待信号量 start_io_thread_semaphore 的唤醒,然后通过 agent->RequestIoThreadStart() 启动调试子线程。那么谁来唤醒 StartIoThreadMain 对应的线程呢?是信号 SIGUSR1 的处理函数。
RegisterSignalHandler(SIGUSR1, StartIoThreadWakeup);
static void StartIoThreadWakeup(int signo, siginfo_t* info, void* ucontext) {
uv_sem_post(&start_io_thread_semaphore);
}- 1.
- 2.
- 3.
- 4.
- 5.
但是事情没有那么简单,因为 RequestIoThreadStart 是在子线程里执行的,而 V8 的 isolate 不是线程安全的。
void Agent::RequestIoThreadStart() {
// We need to attempt to interrupt V8 flow (in case Node is running
// continuous JS code) and to wake up libuv thread (in case Node is waiting
// for IO events)
uv_async_send(&start_io_thread_async);
parent_env_->RequestInterrupt([this](Environment*) {
StartIoThread();
});
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
RequestIoThreadStart 往主线程的任务队列里插入一个任务,然后在主线程里执行任务回调去打开调试器,至于为什么需要同时调 uv_async_send 和 RequestInterrupt 注释里已经写得很清楚,Node.js 可能正阻塞于 Libuv 的 Poll IO 阶段,也可以正陷入 JS 的代码执行中甚至死循环中。这两个调用分别解决这两个问题,从而“唤醒”主线程继续执行任务。同样,start_io_thread_async 的回调也是调用了 StartIoThread 启动调试器。StartIoThread 中加了判断,如果已经开启了则直接返回,避免两个回调执行重复的代码。
4 Trace
Node.js 的 Trace 功能中也使用了子线程。先看一下 Trace Agent 的构造函数。
Agent::Agent() : tracing_controller_(new TracingController()) {
CHECK_EQ(uv_loop_init(&tracing_loop_), 0);
// 注册当注册 writer 时的回调
CHECK_EQ(uv_async_init(&tracing_loop_,
&initialize_writer_async_,
[](uv_async_t* async) {
Agent* agent = ContainerOf(&Agent::initialize_writer_async_, async);
agent->InitializeWritersOnThread();
}), 0);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
接着看 Agent 启动的代码,Trace Agent 启动的时候就会创建一个新的子线程。
void Agent::Start() {
if (started_)
return;
// 创建 controller 和 buffer 后续用到
NodeTraceBuffer* trace_buffer_ = new NodeTraceBuffer(NodeTraceBuffer::kBufferChunks, this, &tracing_loop_);
tracing_controller_->Initialize(trace_buffer_);
// 创建子线程运行新的事件循环
CHECK_EQ(0, uv_thread_create(&thread_, [](void* arg) {
Agent* agent = static_cast<Agent*>(arg);
uv_run(&agent->tracing_loop_, UV_RUN_DEFAULT);
}, this));
started_ = true;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
逻辑和之前介绍的类似,都是开启一个新的线程运行一个事件循环,然后主线程和子线程进行通信。看 NodeTraceBuffer 的初始化
NodeTraceBuffer::NodeTraceBuffer(size_t max_chunks,
Agent* agent, uv_loop_t* tracing_loop)
: tracing_loop_(tracing_loop),
buffer1_(max_chunks, 0, agent),
buffer2_(max_chunks, 1, agent) {
current_buf_.store(&buffer1_);
flush_signal_.data = this;
// 初始化线程间通信的结构体,NonBlockingFlushSignalCb 在子线程中执行
int err = uv_async_init(tracing_loop_, &flush_signal_,
NonBlockingFlushSignalCb);
exit_signal_.data = this;
err = uv_async_init(tracing_loop_, &exit_signal_, ExitSignalCb);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
NodeTraceBuffer 往 loop 中注册了一个 async 结构体。注册完任务后,子线程就进入了事件循环。这时候有两种情况会改变事件循环的状态。第一个是注册 writer。writer 是消费者,当有 trace 事件发生时,agent 会调用 writer 进行数据的消费,比如写入文件。我们看一下注册 writer 的逻辑。
AgentWriterHandle Agent::AddClient(
const std::set<std::string>& categories,
std::unique_ptr<AsyncTraceWriter> writer,
enum UseDefaultCategoryMode mode) {
// 省略了一些逻辑
AsyncTraceWriter* raw = writer.get();
writers_[id] = std::move(writer);
// 记录待初始化的 writer,通知子线程处理
{
Mutex::ScopedLock lock(initialize_writer_mutex_);
to_be_initialized_.insert(raw);
uv_async_send(&initialize_writer_async_);
while (to_be_initialized_.count(raw) > 0)
initialize_writer_condvar_.Wait(lock);
}
return AgentWriterHandle(this, id);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
前面看到 initialize_writer_async_ 的回调是
uv_async_init(&tracing_loop_,
&initialize_writer_async_,
[](uv_async_t* async) {
Agent* agent = ContainerOf(&Agent::initialize_writer_async_, async);
agent->InitializeWritersOnThread();
}), 0)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
接着看 InitializeWritersOnThread。
void Agent::InitializeWritersOnThread() {
Mutex::ScopedLock lock(initialize_writer_mutex_);
while (!to_be_initialized_.empty()) {
AsyncTraceWriter* head = *to_be_initialized_.begin();
head->InitializeOnThread(&tracing_loop_);
to_be_initialized_.erase(head);
}
initialize_writer_condvar_.Broadcast(lock);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
InitializeWritersOnThread 就是遍历刚才记录的 writer 并执行它的 InitializeOnThread。以 NodeTraceWriter 为例。
void NodeTraceWriter::InitializeOnThread(uv_loop_t* loop) {
tracing_loop_ = loop;
flush_signal_.data = this;
int err = uv_async_init(tracing_loop_, &flush_signal_,
[](uv_async_t* signal) {
NodeTraceWriter* trace_writer =
ContainerOf(&NodeTraceWriter::flush_signal_, signal);
trace_writer->FlushPrivate();
});
CHECK_EQ(err, 0);
exit_signal_.data = this;
err = uv_async_init(tracing_loop_, &exit_signal_, ExitSignalCb);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
writer 会往子线程的事件循环里注册任务。等到有数据消费的时候主线程会通知子线程。现在有了消费者,那么生产者是谁?生产者散布在 Node.js 源码的多个地方。下面以文件模块的打开文件为例。
FS_SYNC_TRACE_BEGIN(open);
int result = SyncCall(env, args[4], &req_wrap_sync, "open",
uv_fs_open, *path, flags, mode);
FS_SYNC_TRACE_END(open);- 1.
- 2.
- 3.
- 4.
FS_SYNC_TRACE_BEGIN 和 FS_SYNC_TRACE_END 是 Trace 模块定义的宏,非常繁琐。最终会调用 controller->AddTraceEvent 生产 trace 数据,这是改变子线程事件循环状态的第二种情况。Node.js 的 controller 为 TracingController 对象,继承 v8::platform::tracing::TracingController。看一下这个对象的 AddTraceEvent 函数。
uint64_t TracingController::AddTraceEvent(...) {
return AddTraceEventWithTimestamp(...);
}
uint64_t TracingController::AddTraceEventWithTimestamp() {
TraceObject* trace_object = trace_buffer_->AddTraceEvent(...);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
最终调用了 buffer 的 AddTraceEvent。buffer 就是 Trace Agent 初始化时设置的 NodeTraceBuffer。
TraceObject* NodeTraceBuffer::AddTraceEvent(uint64_t* handle) {
// 数据太多则 flush
if (!TryLoadAvailableBuffer()) {
*handle = 0;
return nullptr;
}
// 记录数据
return current_buf_.load()->AddTraceEvent(handle);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
NodeTraceBuffer::AddTraceEvent 会不断积攒数据。达到某个值后会通知子线程进行 flush。我们看一下 TryLoadAvailableBuffer。
bool NodeTraceBuffer::TryLoadAvailableBuffer() {
InternalTraceBuffer* prev_buf = current_buf_.load();
if (prev_buf->IsFull()) {
uv_async_send(&flush_signal_);
}
return true;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
通过 uv_async_send 通知 flush_signal_ ,然后在子线程里执行回调 NonBlockingFlushSignalCb。
void NodeTraceBuffer::NonBlockingFlushSignalCb(uv_async_t* signal) {
NodeTraceBuffer* buffer = static_cast<NodeTraceBuffer*>(signal->data);
if (buffer->buffer1_.IsFull() && !buffer->buffer1_.IsFlushing()) {
buffer->buffer1_.Flush(false);
}
if (buffer->buffer2_.IsFull() && !buffer->buffer2_.IsFlushing()) {
buffer->buffer2_.Flush(false);
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
buffer->buffer1_ 和 buffer->buffer2_ 是 InternalTraceBuffer 对象。
void InternalTraceBuffer::Flush(bool blocking) {
{
Mutex::ScopedLock scoped_lock(mutex_);
if (total_chunks_ > 0) {
flushing_ = true;
for (size_t i = 0; i < total_chunks_; ++i) {
auto& chunk = chunks_[i];
for (size_t j = 0; j < chunk->size(); ++j) {
TraceObject* trace_event = chunk->GetEventAt(j);
if (trace_event->name()) {
agent_->AppendTraceEvent(trace_event);
}
}
}
total_chunks_ = 0;
flushing_ = false;
}
}
agent_->Flush(blocking);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
InternalTraceBuffer 会把积攒的数据写到 agent 并 flush。
void Agent::AppendTraceEvent(TraceObject* trace_event) {
for (const auto& id_writer : writers_)
id_writer.second->AppendTraceEvent(trace_event);
}- 1.
- 2.
- 3.
- 4.
Agent 也只是个中间人,它会调用每个 writer 进行数据的消费。以 NodeTraceWriter 为例,NodeTraceWriter 会先把数据积攒起来。
void Agent::Flush(bool blocking) {
for (const auto& id_writer : writers_)
id_writer.second->Flush(blocking);}
// 通知子线程一起 flush 到文件
void NodeTraceWriter::Flush(bool blocking) {
int err = uv_async_send(&flush_signal_);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
flush_signal_ 回调是 NodeTraceWriter 的 FlushPrivate。
void NodeTraceWriter::FlushPrivate() {
WriteToFile(std::move(str), highest_request_id);
}- 1.
- 2.
- 3.
最终写入文件,我们也就拿到了 Trace 对应的数据。
5 Platform
Node.js 在初始化时会创建一个 WorkerThreadsTaskRunner。
WorkerThreadsTaskRunner::WorkerThreadsTaskRunner(int thread_pool_size) {
Mutex platform_workers_mutex;
ConditionVariable platform_workers_ready;
Mutex::ScopedLock lock(platform_workers_mutex);
int pending_platform_workers = thread_pool_size;
delayed_task_scheduler_ = std::make_unique<DelayedTaskScheduler>(
&pending_worker_tasks_);
// threads_ 是线程队列
threads_.push_back(delayed_task_scheduler_->Start());
for (int i = 0; i < thread_pool_size; i++) {
PlatformWorkerData* worker_data = new PlatformWorkerData{
&pending_worker_tasks_, &platform_workers_mutex,
&platform_workers_ready, &pending_platform_workers, i
};
std::unique_ptr<uv_thread_t> t { new uv_thread_t() };
// 创建线程
if (uv_thread_create(t.get(), PlatformWorkerThread,
worker_data) != 0) {
break;
}
threads_.push_back(std::move(t));
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
首先会根据 thread_pool_size 创建多个子线程。还创建了一个延迟任务的调度器 DelayedTaskScheduler,这个对象里也创建了一个线程。
std::unique_ptr<uv_thread_t> Start() {
auto start_thread = [](void* data) {
// 处理任务
static_cast<DelayedTaskScheduler*>(data)->Run();
};
std::unique_ptr<uv_thread_t> t { new uv_thread_t() };
uv_sem_init(&ready_, 0);
CHECK_EQ(0, uv_thread_create(t.get(), start_thread, this));
uv_sem_wait(&ready_);
uv_sem_destroy(&ready_);
return t;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
Node.js 初始化后就创建了一波线程,然后 V8 会使用这些线程,我们通过 Post 和 PostDelayedTask 可以看到。
6 总结
大致完成了 Node.js 中幕后线程的分析,单线程的 Node.js 正是因为这些幕后的子线程变得越来越强大,另外我们也可以通过 Addon 的方式开启新的子线程,以此做更多的事情,当然也可以使用 worker_thread 模块。















