分布式高性能 ID 生成算法——Snowflake ID。
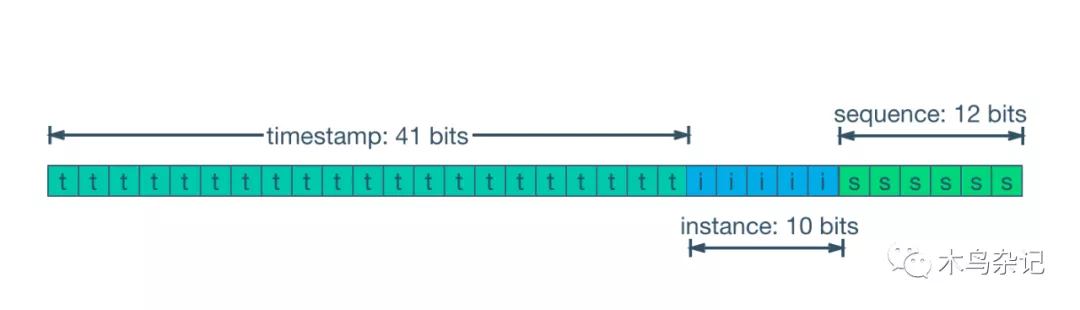
维基百科 Snowflake ID 格式Untitled
来源:https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake[2]
雪花算法(Snowflake ID) 是时下应用相当广的一个分布式全序 ID 生成算法,这篇 Twitter 官方博客 2010 年的文章,宣告了雪花算法的诞生,概略的介绍了 Twitter 当时对分布式 ID 生产算法需求的背景(context)、可选项和最终方案。理解了其产生时的需求,也就理解了算法的一半,推荐一读。
问题背景。Twitter 的数据库经历了一个从小到大、从单机到分布式的增长过程。但无论在分布式数据库 Cassandra[3] 中,还是使用 gizzard[4] 方案水平扩容的多机 MySQL 中,都没有一个满足 Twitter 当时需求的全局 ID 生成方案。那 Twitter 当时对全局 ID 的要求是什么呢?
- 每秒产生数万个 ID。这就限制了不能使用依赖多机沟通来产生 ID。毕竟一次网络通信延迟都会有 1ms+,自然难以实现超过 1k 的 qps。
- 所有 ID 满足全序(roughly sortable)关系。即任意两个 id 都是可比的,毕竟 Feed 流中所有 Tweet 的排序都依赖此 ID。
- 长度不超过 64 bit 。Twitter 以前经历过随着系统体量的增大而痛苦的增加 ID bit 数的过程,这次希望一步到位,但同时又不太长。
可选项。基于 MySQL 的自增 id,类似于 flickr[5]的方案。但不通过多机同步,难以提供全序保证。
一些现成的 UUID 算法,但其生成的 ID 都是 128 bit。
基于 Zookeeper 的全局自增 id 。自然,由于 Zab 等共识算法,其能保证全序,却不能满足 Twitter 的性能需求。
最终方案。通过组合时间戳、进程编号、自增序号,Twitter 找到了一种分布式高性能全序 ID 生成算法。基本思想是,大体保证机器间的时钟同步,并利用机器时钟生成时间戳作为自增 ID,如果两个进程产生了相同时间戳,则通过进程编号进一步确认其大小。由于一般时间戳会精确到毫秒,为了满足 QPS 需求,会留几位给自增 id,使得 1ms 内产生 10+ 个 id。
最终格式如上图,1 bit 的符号位,固定为0,以保证在有符号数体系下 ID 也为正数。41 bit 的时间戳,单位 ms,时间戳本身是个相对值,其起始点可以自行设置。10 bit 的进程编号,最终可支持含有 1024 个进程的单机或者集群,但一般来说,每个机器一个进程。12 bit 的自增序号,每毫秒最多允许产生 4k+ 个 ID。
在实际使用时,可以在保证总 bit 数的情况下,按需调整三个字段的 bit 数。比如进程数确定不会超过 100 个,则可以将对应字段缩短为 7 bit。进程序号可以在初始时通过一个全局发号器来分配,比如 Zookeeper。在之后的运行或者重启时,无需再改。
开源代码在此[6],其优点如下:
- 高性能(Performance)。单进程 10k+ 的 QPS,平均 2ms 的延迟。
- 无需沟通(Uncoordinated)。产生 ID 的这组进程,可以分布在多个数据中心的多个机器,而在产生数据时无需进行互相沟通(除了 NTP 时间戳同步)。
- 大致按时间有序(Roughly Time Ordered)。可以从 ID 中解析出时间戳。
- 可直接排序(Directly Sortable)。无需解析即可直接排序。
- 紧凑(Compact)。不要 128 bit 就要 64 bit。
- 高可用(Highly Available)。将进程分布在多数据中心的多台机器上,只要有一台机器活着,就仍能提供服务。
一些问题。雪花算法会隐式的依赖机器时钟,虽然并不严格。但使用者需要保证产生 ID 的所有机器通过 NTP 保持大致的时间同步。snowflake 算法可以处理由于 NTP 时钟同步带来的时钟回退问题。但解决方法很粗暴,即发现时钟回退了就死等到时钟超过上一次 ID 产生的对应时间点。也正因如此,需要维持所有机器时钟大致同步。
参考资料
[1]任何想法都欢迎来提 issue: https://github.com/DistSysCorp/ArticleListWeekly/issues
[2]Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake
[3]Cassandra: Open Source NoSQL Database: http://cassandra.apache.org/
[4]gizzard: http://github.com/twitter/gizzard
[5]Ticket Servers: Distributed Unique Primary Keys on the Cheap: https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/
[6]snowflake 2010: https://github.com/twitter-archive/snowflake/tree/snowflake-2010