前面文章为什么GBDT可以超越深度学习,我们提到,GBDT在特定的表格数据场景上有独特的优势。而在过往的研究中,多目标一直是NN的主场。
我们能否把GBDT和多目标结合起来发光发热?
答案是,可以!MTGBM给你解决GBDT多目标建模的最后一公里。
多目标学习背景
多目标学习在推荐系统领域近年一直大放异彩,大家耳熟能详的ESSM和MMoE等神经网络模型都是多目标的典型代表方法,他们的基本思想都是考虑了不同任务之间的区别和联系,提高各个任务的学习质量和效果。
除了NN之外,GBDT(Gradient boosted decision trees)模型在推荐系统、广告系统及金融风控领域被广泛使用,但一些业界知名的GBDT实现(微软的LightGBM,XGBoost以及CatBoost)中没有多目标学习的功能。而在现实场景中引入多任务学习往往能带来稳定的效果提升及提供更加优秀的鲁棒性。
举几个简单的例子:在预测商品点击率时,不仅仅使用模型学习历史点击率,还可以学习点赞收藏分享等数据,更好的学习到用户的爱好信息,完成预测任务。
在预测欺诈分类时,如果不仅仅预测是否为欺诈,同时预测细分欺诈手法的多个二分类任务,不仅仅会增加模型表达能力,同时还可以在是否欺诈上更加精确,提高模型对目标的理解力。
MTGBM介绍
点击阅读原文直达GitHub.

论文地址:https://arxiv.org/pdf/2201.06239.pdf
开源实现:https://github.com/antmachineintelligence/mtgbmcode
这里我要说一下作者了,经常玩比赛的可能知道Bird这个ID,他是MTGBM的一作,并且在蚂蚁金服的风控业务实践和竞赛场景中,落地MTGBM都取得了显著的收益。
这篇文章创造性地提出了一种多任务学习的GBDT算法,并高效地实现了该算法,目前通过该算法能实现的功能有:多标签-性能提升、历史模型知识蒸馏,多任务-迁移学习等,在大量公开数据集上测试后,主目标均比XGB,LightGBM,Catboost有较大提升。
该算法基于LigntGBM实现,你可以像以前使用LightGBM一样使用它,几乎没有学习成本。
原理及细节
目前业内使用单目标学习较多,如LightGBM和XGBoost,缺点是模型容易过拟合,鲁棒性不足;而目前可用的多目标的GBDT,但是都是仅仅适用于互斥的多分类,并不能应用于多个独立的任务。而且多个分类之间独立学习,并没有提取公共的部分,导致模型提升有限。另外有使用神经网络深度学习完成多目标学习,但由于特征比较多且值域非常大神经网络在这些场景表现很差。
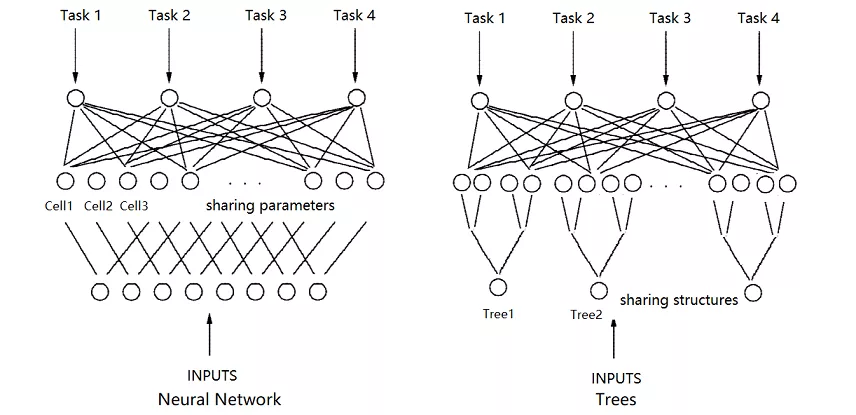
一般来说,多目标学习需要共享中间层的参数,从而达到多目标学习的过程。而在树模型中由于没有中间参数可以共享,我们决定使用共享树结构的方式进行多目标学习。新的树结构被称为同构异值树,为不同的目标提供相同的分裂结构和不同的输出值。
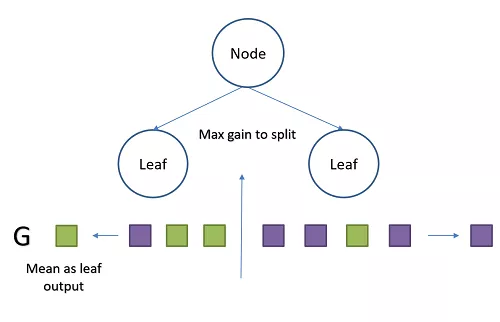
传统的单目标GBDT计算每个树的过程
- 计算之前所有树预测结果与当前目标的残差与梯度
- 通过每个样本的梯度,在每个树节点进行分裂的时候,使用某个合适的特征某个位置将样本划为两部分,令损失增益L(梯度)最小。
- 对每个叶子节点,使用落在他们上的数据梯度的均值进行更新。
- 在到达指定深度或样本不可再分后结束分裂。
- 得到一颗树。
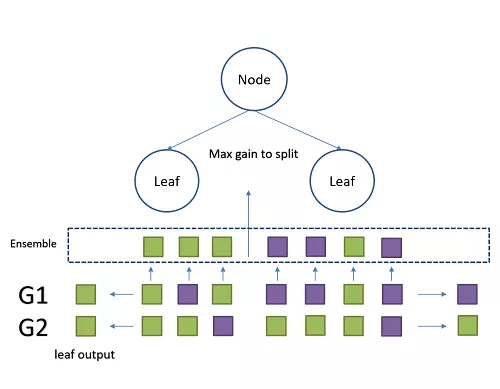
多目标MGBM算法训练过程
- 计算之前所有树预测结果与多个目标的残差与梯度
- 通过每个样本的多个目标梯度进行融合,使得每个样本拥有一个融合梯度,在每个树节点进行分裂的时候,使用某个合适的特征某个位置将样本划为两部分,令损失增益L(融合梯度)最小。
- 对每个叶子节点,产生等同于学习目标数目的输出,使用落在他们相应的目标的数据梯度的均值进行更新。
- 在到达指定深度或样本不可再分后结束分裂。
- 得到一颗树。
- 最后预测不同目标时,只需要使用相同树的不同目标值即可。
实验结果
MTGBM在两个实际表数据场景的数据集上做了对比实验,分别是China Foreign Currency Volume 和 Kaggle上的IEEE-CIS Fraud Detection
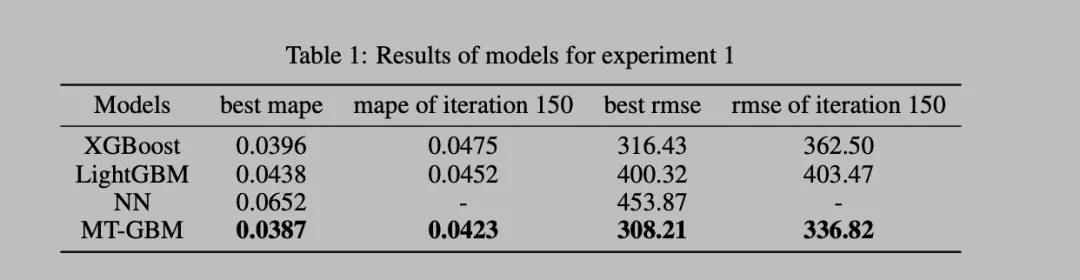
更多细节的实验结果,多任务的组合以及多fold的实验
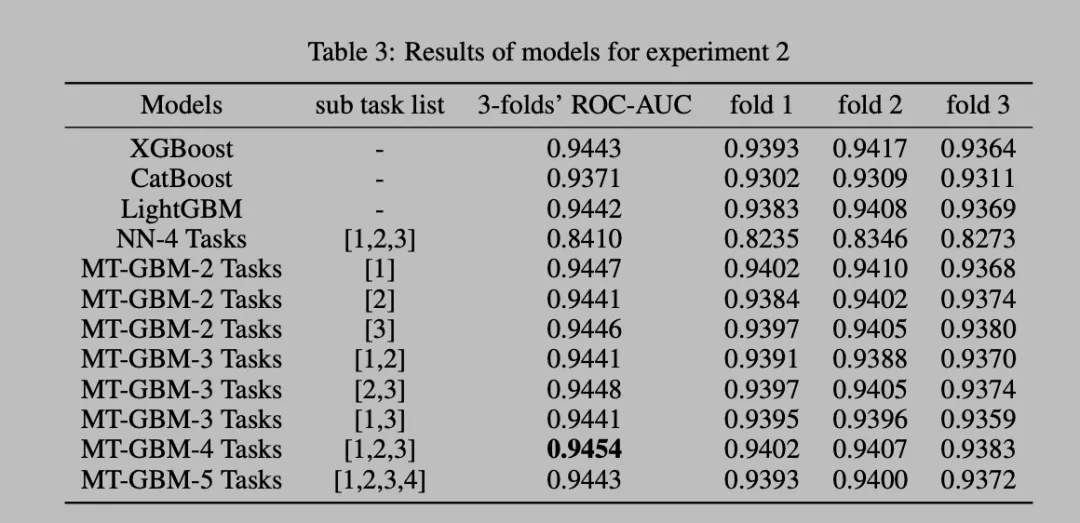
可以看出MTGBM在实际表数据场景的数据集上,比NN和多个GBDT实现,LGB/XGB/CTB都取得了更好和稳定的提升。