












一 背景
1 优雅上下线
在分布式场景下,微服务进程都是以容器的形式存在,在容器调度系统例如 k8s 的支持下运行,容器组 Pod 是 K8S 的最小资源单位。随着服务的迭代和更新,当新版本上线后,需要针对线上正在运行的服务进行替换,从而发布新版本。
在稳定生产的过程中,容器调度完全由 k8s 管控,微服务治理由服务框架或者运维人员进行维护和管理。而在发布新版本,或者扩缩容的场景下,会终止旧的容器实例,并使用新的容器实例进行替换,对于承载高流量的线上生产环境,这个替换过程的衔接一但出现问题,将在短时间内造成大量的错误请求,触发报警甚至影响正常业务。对于体量较大的厂家,发布过程出现问题所造成的损失会是巨大的。
因此,优雅上下线的诉求被提出。这要求服务框架在拥有稳定服务调用能力,传统服务治理能力的基础之上,应当提供服务上下线过程中稳定的保障,从而减少运维成本,提高应用稳定性。
2 期望效果
我认为,理想状态下优雅上下线的效果,是在一个承载大量流量的分布式系统内,所有组件实例都可以随意地扩容、缩容、滚动更新,在这种情况下需要保证更新过程中稳定的 tps (每秒请求数) 和 rt(请求时延),并且保证不因为上下线造成请求错误。再深一步,就是系统的容灾能力,在一个或多个节点不可用的情况下,能保证流量的合理调度,从而尽最大能力减少错误请求的出现。
- Dubbo-go 的优雅上下线能力
Dubbo-go 对优雅上下线的探究可以追溯到三年前,早在1.5早期版本,Dubbo-go 就已经拥有优雅下线能力。通过对终止信号量的监听,实现反注册、端口释放等善后工作,摘除流量,保证客户端请求的正确响应。
在前一段时间,随着 Dubbo-go 3.0 的正式发版,我在一条 proposal issue (dubbo-go issue 1685) [1] 中提到了一些生产用户比较看重的问题,作为 3.x 版本的发力方向,并邀请大家谈论对这些方向的看法,其中用户呼声最高的特性就是无损上下线的能力,再次感谢社区的王晓伟同学的贡献。
经过不断完善和生产环境测试,目前 Dubbo-go 已拥有该能力,将在后续版本中正式与大家见面。
二 Dubbo-go 优雅上下线实现思路
优雅上下线可以分为三个角度。服务端的上线,服务端的下线,和客户端的容灾策略。这三个角度,保证了生产实例在正常的发布迭代中,不出现错误请求。
1 客户端负载均衡机制
以 Apache 顶级项目 Dubbo 为典范的微服务架构在这里就不进行赘述,在分布式场景下,即使在 K8S 内,大多数用户也会使用第三方注册组件提供的服务发现能力。站在运维成本、稳定性、以及分层解耦等角度,除非一些特殊情况,很少会直接使用原生 Service 进行服务发现和负载均衡,因此这些能力成为了微服务框架的标配能力。
熟悉 Dubbo 的同学一定了解过,Dubbo 支持多种负载均衡算法,通过可扩展机制集成到框架内。Dubbo-go 亦是如此,针对多实例场景下,可以支持多种负载均衡算法, 例如 RR,随机数,柔性负载均衡等等。
下图摘自 Dubbo 官网
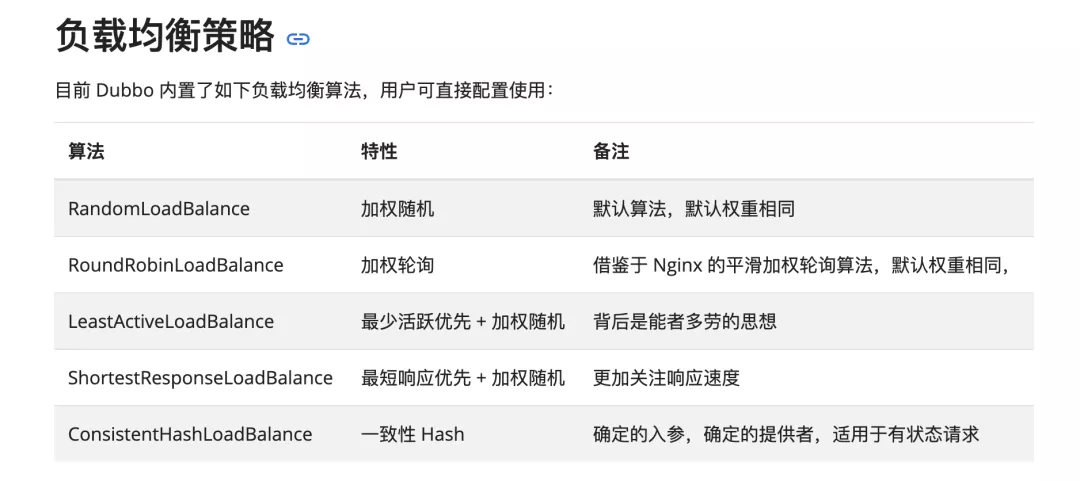
Dubbo-go 的负载均衡组件
Dubbo-go 服务框架拥有一套接口级扩展机制,可以根据配置,加载同一组件接口的不同的实现。其中就有随机算法负载均衡策略,它是 Dubbo-go 默认的负载均衡算法。在使用这种算法进行负载均衡的情况下,所有 provider 都会根据一定的权重策略被随机选择。所有的provider 实例都有可能成为下游。
这种较为传统的负载均衡算法会带来隐患,即不会因为之前调用的结果,影响到后续调用过程中对下游实例的选择。因此如果有部分下游实例处在上下线阶段,造成短暂的服务不可用,所有随机到该实例的请求均会报错,在高流量的场景下,会造成巨大损失。
集群重试策略
下图摘自Dubbo 官网
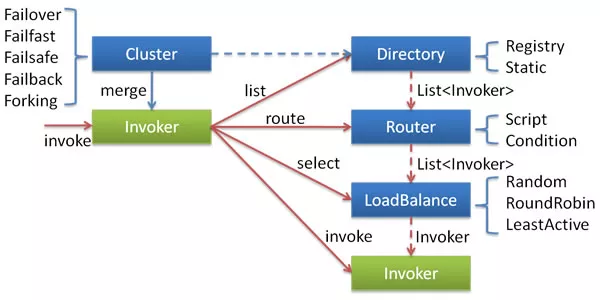
Dubbo-go 的集群重试策略是从 Dubbo 借鉴过来的,默认使用 Failover(故障转移) 逻辑,当然也有failback,fallfast 等策略,也是依靠了组件可扩展能力集成进框架内。
无论是上面提到的负载均衡,还是重试逻辑,都是基于“面向切面编程“的思路,构造一个抽象化 invoker 的实现,从而将流量层层向下游传递。对于 Failover 策略,会在负载均衡选择下游实例的基础上,增加对错误请求的重试逻辑。一旦请求报错,会选择下一个 invoker 进行尝试,直到请求成功,或超过最大请求次数为止。
集群重试策略只是增加了尝试的次数,降低了错误率,但本质上还是无状态的,当下游服务不可用时,会造成灾难性的后果。
黑名单机制
黑名单机制是我去年实习,师兄安排做的第一个需求,大致思路很简单,将请求抛错的 invoker 对应实例的 ip 地址加入黑名单,后续不再将流量导入该实例,等过一段时间,尝试请求它,如果成功就从黑名单中删除。
这个机制实现逻辑非常简单,但本质上是将无状态负载均衡算法升级为了有状态的。对于一个不可用的下游实例,一次请求会快速将该实例拉黑,其他请求就会识别出黑名单内存在该实例,从而避免了其他的流量。
对于这种策略,在黑名单中保留的超时、尝试从黑名单移除的策略等,这些变量都应当结合具体场景考虑,本质上就是一个有状态的故障转移策略。普适性较强。
P2C 柔性负载均衡算法
柔性负载均衡算法是 Dubbo3 生态的一个重要特性,Dubbo-go 社区正在携手 Dubbo 一同探索和实践。一些读者应该在之前 Dubbo-go 3.0 发布的文章中看过相关介绍。简单来说,是一个有状态的,不像黑名单那么“一刀切”的,考虑变量更广泛、更全面的一种负载均衡策略,会在 P2C 算法的基础之上,考虑各个下游实例的请求时延、机器资源性能等变量,通过一定策略来确定哪个下游实例最合适,而具体策略,将结合具体应用场景,交由感兴趣的社区成员来探索,目前是来自字节的牛学蔚(github@justxuewei) 在负责。
上述诸多负载均衡策略,都是站在客户端的角度,尽最大能力让请求访问至在健康的实例上。在无损上下线角度来考虑,对于处于发布阶段的不正常工作的实例,可以由客户端通过合理的算法和策略,例如黑名单机制来过滤掉。
我认为客户端负载均衡是通用能力,对无损上下线场景的作用只是锦上添花,并不是的核心要素。究其本质,还是要从被“上下线”的服务端实例来考虑,从而解决根本问题。
2 服务端优雅上线逻辑
相较于客户端,服务端作为服务的提供者、用户业务逻辑的实体,在我们讨论的场景下逻辑较为复杂。在讨论服务端之前,我们还是先重温一下基础的服务调用模型。
传统服务调用模型
参考 Dubbo 官网给出的架构图,完成一次服务调用,一般需要三个组件:注册中心,服务端,客户端。
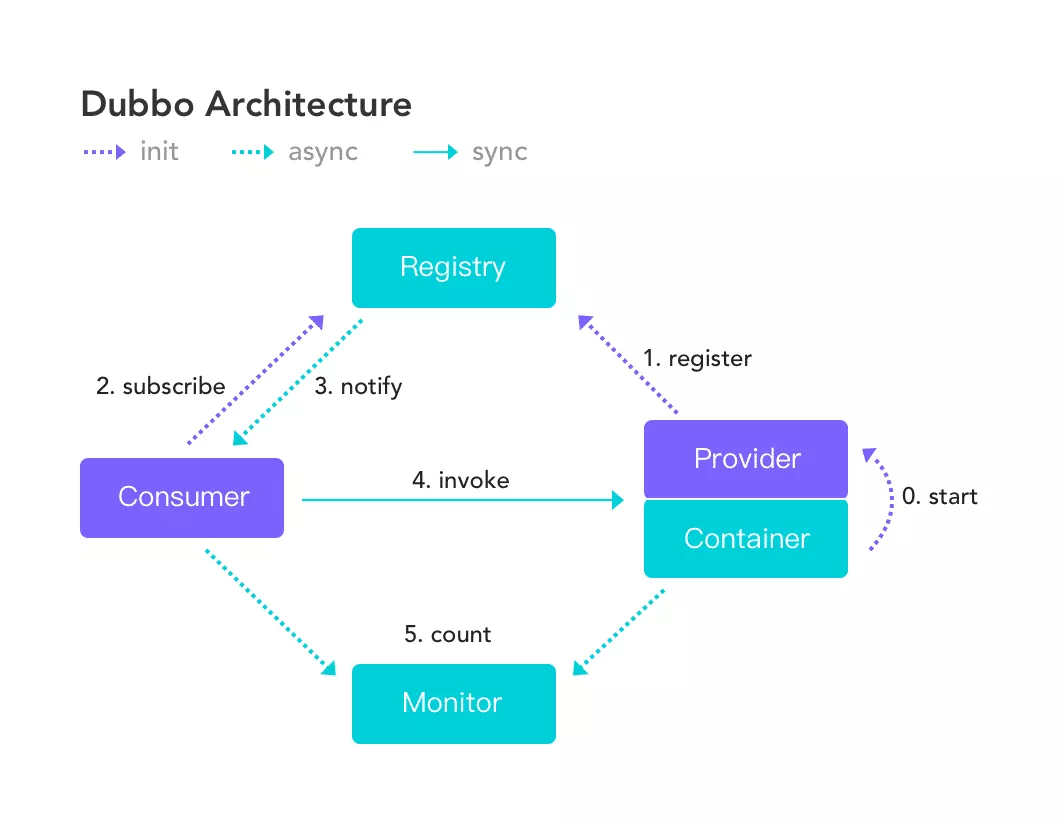
- 服务端首先需要暴露服务,监听端口,从而具备接受请求的能力。
- 服务端将当前服务信息例如ip和端口,注册在中心化的注册中心上,例如Nacos。
- 客户端访问注册中心,获取要调用的服务ip和端口,完成服务发现。
- 服务调用,客户端针对对应 ip 和端口进行请求。
这简单的四个步骤,就是 Dubbo-go 优雅上下线策略的核心关注点。正常情况下,四个步骤依此执行下来非常顺利,逻辑也非常清晰。而放在一个大规模的生产集群内,在服务上下线时就会出现很多值得考量的细节。
我们要明白,上下线过程中的错误是怎么产生的?我们只需要关注两个错误,就是:“一个请求被发送给了一个不健康的实例”,以及“正在处理请求的进程被杀死”,上下线过程中几乎所有的错误都是来自于他们。
服务优雅上线逻辑细节
服务上线时,按照上述的步骤,首先要暴露服务,监听端口。在保证服务提供者可以正常提供服务之后,再将自身信息注册在注册中心上,从而会有来自客户端的流量发送至自己的ip。这个顺序一定不能乱,否则将会出现服务没有准备好,就收到了请求的情况,造成错误。
上面所说的只是简单的情况。在真实场景下,我们所说的一个服务端实例,往往包含一组相互依赖的客户端和服务端。在 Dubbo 生态的配置中,被称为 Service (服务)和 Reference(引用) 。
举一个业务同学非常熟悉的例子,在一个服务函数内,会执行一些业务逻辑,并且针对多个下游服务发起调用,这些下游可能包含数据库、缓存、或者其他服务提供者,执行完毕后,返回获得的结果。这对应到 Dubbo 生态的概念中,其实现就是:Service 负责监听端口和接受请求,接受的请求会向上层转发至应用业务代码,而开发者编写的业务代码会通过客户端,也就是 Reference,请求下游对象。当然这里的下游协议有多种,我们只考虑 dubbo 协议栈。
由上面提到这种常见的服务模型,我们可以认为 Service 是 依赖 Reference 的,一个 Service 的所有 Reference 必须都正常工作后,当前 Service 才能正确接受来自上游的服务。这也就推导出了,Service 应该在 Reference 之后加载,当加载完成所有 Reference 后,保证这些客户端都可用,再加载 Service,暴露能工作的服务,最后再注册到注册中心,喊上游来调用。如果反过来,Service 准备好了而 Reference 没有,则会造成请求错误。
因此,服务上线逻辑是 Consumer 加载 -> Provider 加载 -> Registry 服务注册。
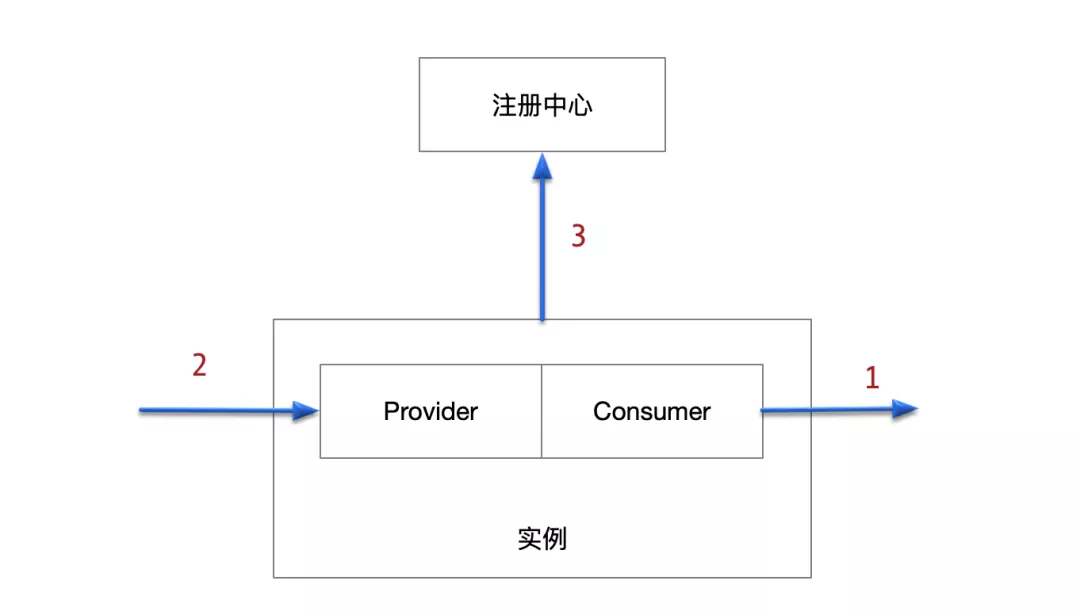
有读者可能会疑惑,如果 Consumer 依赖当前 实例自己的 Provider 怎么办,Dubbo 的实现是可以不走网络直接发起函数调用,Go 这边也可以按照这种思路来处理,不过实现还待开发。这种情况相对较少,更多的还是上述大家熟悉的情况。
3 服务端优雅下线逻辑
相比于服务上线,服务下线需要考虑的点更多一些。我们重新回到上一节提到的服务调用模型四步骤:
- 服务端首先需要暴露服务,监听端口,从而具备接受请求的能力。
- 服务端将当前服务信息例如ip和端口,注册在中心化的注册中心上,例如Nacos。
- 客户端访问注册中心,获取要调用的服务ip和端口,完成服务发现。
- 服务调用,客户端针对对应 ip 和端口进行请求。
如果一个服务将要下线,则一定要把相关的善后工作做好。现在的线上情况是这样:客户端正在源源不断地给当前实例请求,如果这个时候直接结束当前进程,一方面,将在一瞬间会有大量的 tcp 建立连接失败,只能寄希望于第一章提到的客户端负载均衡策略了;另一方面,有大量正在处理的请求被强制丢弃。这很不优雅!所以当实例知道自己要被终止后,首先要做的就是告诉客户端:“我这个服务要被终止了,快把流量切走”。这体现在实现中,就是把自身的服务信息从注册中心删除。客户端拿不到当前实例IP后,不会再将请求发过来,这个时候再终止进程才优雅。
上面所说的,也只是简单的情况。在真实场景之下,客户端可能并没有那么快地把流量切走,并且当前服务手里还有一大批正在处理的任务,如果贸然终止进程,可以形象地理解成将端在手里的一盆水撒了一地。
有了这些铺垫,我们来详细地聊一聊服务下线的步骤。
优雅下线的使用和触发
上面的小故事里面提到,进程首先要知道自己“要被终止”了,从而触发优雅下线逻辑。这个消息可以是信号量,当 k8s 要终止容器进程,会由 kubelet 向进程发送 SIGTERM 信号量。在 Dubbo-go 框架内预置了一系列终止信号量的监听逻辑,从而在收到终止信号后,依然能由进程自己来控制自己的行动,也就是执行优雅下线逻辑。
不过有些应用会自己监听 SIGTERM 信号处理下线逻辑。比如,关闭 db 连接、清理缓存等,尤其是充当接入层的网关类型应用,web 容器和 RPC 容器同时存在。这个时候先关闭 web 容器还是先关闭 RPC 容器就显得尤其最重要。所以 Dubbo-go 允许用户通过配置internal.signal来控制 signal信号监听的时机,并通过 graceful_shutdown.BeforeShutdown()在合适的时机优雅关闭 rpc 容器。同样,Dubbo-go 也允许用户在配置中选择是否启用新号监听。
反注册
上面提到,服务端需要告诉客户端自己要终止了,这个过程就是通过注册中心进行反注册(Unregister)。常见的服务注册中间件,例如 Nacos 、Zookeeper、Polaris 等都会支持服务反注册,并将删除动作以事件的形式通知给上游客户端。客户端一定是随时保持对注册中心的监听的,能否成功请求与否,很大程度取决于来自注册中心的消息有没有被客户端及时监听和作出响应。
在 Dubbo-go 的实现中,客户端会第一时间拿到删除事件,将该实例对应 invoker 从缓存中删除。从而保证后续的请求不会再流向该 invoker 对应的下游。
反注册过程虽然很快,但毕竟是跨越三个组件之间的事情,无法保证瞬间完成。因此便有了下一步:等待客户端更新。

和后面步骤有些关联的是,在当前阶段只进行反注册,而不能进行反订阅,因为在优雅下线执行的过程中,还会有来自自身客户端向下游的请求,如果反订阅,将会无法接收到下游的更新信息,可能导致错误。
等待客户端更新
服务端在优雅下线逻辑的反注册执行后,不能快速杀死当前服务,而会阻塞当前优雅下线逻辑一小段时间,这段时间由开发人员配置,默认3s,应该大于从反注册到客户端删除缓存的时间。
经过了这段等待更新的时间,服务端就可以认为,客户端已经没有新的请求发送过来了,便可以亮起红灯,逻辑是拒绝一切新的请求。

等待来自上游的请求完成
这里还是不能杀死当前进程,这就像自己的手里还端着那盆水,之前做的只是离开了注水的水龙头,但并没有把盆里的水倒干净。因此要做的还是等待,等待当前实例正在处理的,所有来自上游的请求都完成。
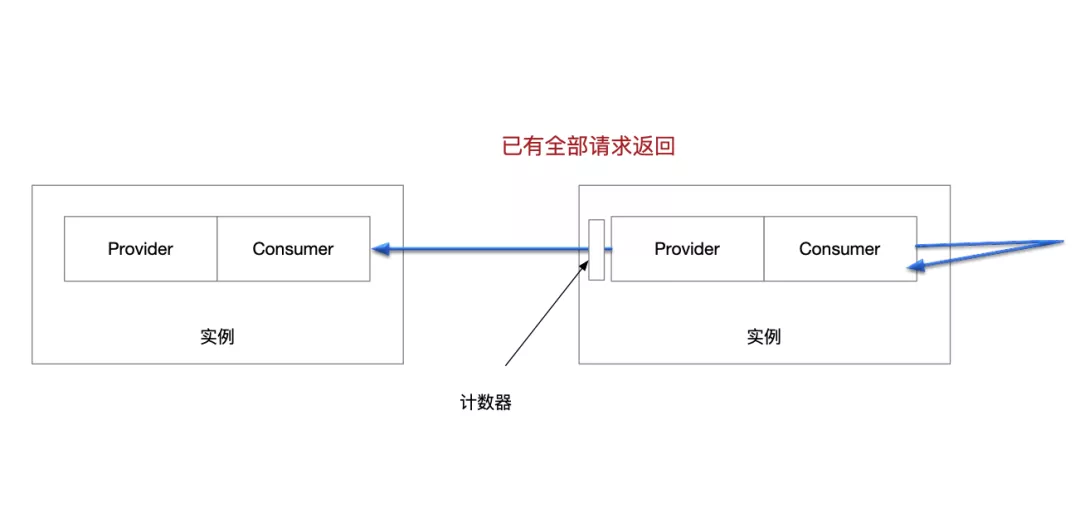
服务端会在一层 filter 维护一个并发安全的计数器,记录所有进入当前实例但未返回的请求数目。优雅下线逻辑会在这时轮询计数器,一旦计数器归零,视为再也没有来自上游的请求了,手里端着的来自上游的水也就倒干净了。
等待自己发出的请求得到响应
走到这一步,整条链路中,自己上游的请求都移除干净了。但自己往下游发出的请求还是个未知数,此时此刻也许有大量由当前实例发出,但未得到响应的请求。如果这时贸然终止当前进程,会造成不可预知的问题。
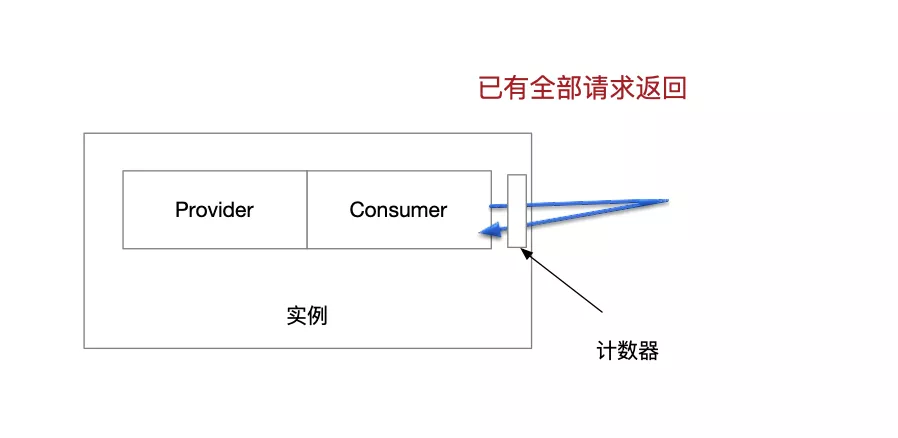
因此还是类似于上述的逻辑,服务在客户端 filter 维护一个线程安全的计数器,由优雅下线逻辑来轮询,等待所有请求都已经返回,计数器归零,方可完成这一阶段的等待。
如果当前实例存在一个客户端,源源不断地主动向下游发起请求,计数器可能一直不归零,那就要依靠这一阶段的超时配置,来强行结束这一阶段了。
销毁协议,释放端口
这时,就可以放心大胆地做最后的工作了,销毁协议、关闭监听,释放端口,反订阅注册中心。用户可能希望在下线逻辑彻底结束后,端口释放后,执行一些自己的逻辑,所以可以提供给开发者一个回调接口。
三 优雅上下线的效果
按照上述的介绍,我们在集群内进行了压测实验和模拟上下线实验。
使用一个 client 实例,5个 proxy 实例,5个 provider 实例,请求链路为:
client -> proxy -> provider
因为资源问题,我们选择让客户端保证 5000 tps 的压力,通过 dubbo-go 的 prometheus 可视化接口暴露出成功率和错误请求计数,之后针对链路中游的 proxy 实例和链路下游的 provider 实例进行滚动发布、扩容、缩容、实例删除等一系列实验,模拟生产发布过程。
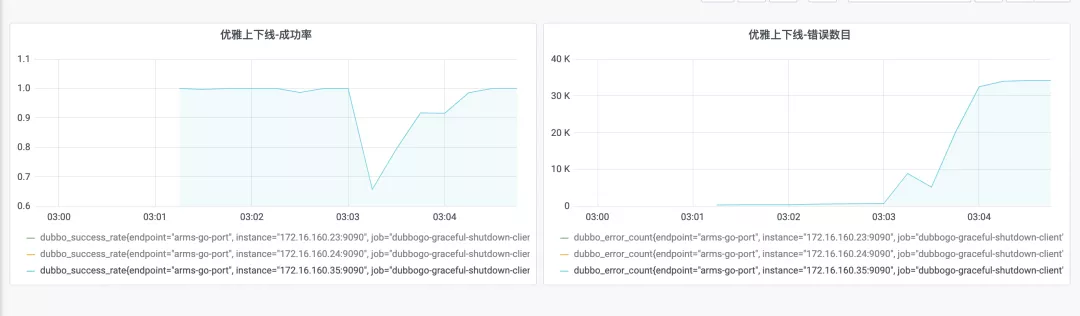
期间我记录了很多数据,可以把一个比较明显的对比展示出来。
不使用优雅上下线逻辑:更新时成功率大幅降低,错误数目持续升高,客户端被迫重启。
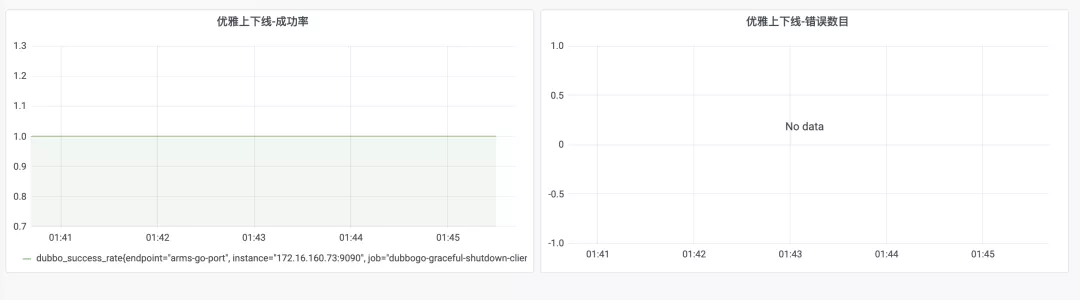
优雅上下线优化后:无错误请求,成功率保持在100%
四 Dubbo-go 在服务治理能力的展望
Dubbo-go v3.0 从去年年底正式发版,到现在过了一个多月左右的时间,3.0 发布对我们而言不是大功告成,而是踏上了展望未来的一个新阶梯。我们即将发布 3.1 版本,这一版本将拥有优雅上下线能力。
在 3.0 筹备阶段,我有想过如果一款服务框架从传统设计走向未来,需要一步一步走下来,需要有多个必经之路:从最基本的用户友好性支持、配置重构、易用性、集成测试、文档建设;到实现传输协议(Dubbo3) Triple-go 的跨生态、稳定、高性能、可扩展、生产可用;再到我们 3.0 发版之后的 服务治理能力、运维能力、可视化能力、稳定性,其中就包括了优雅上下线、流量治理、proxyless;再到形成生态,跨生态集成。这样走,才能一步一个脚印,不断积累,不断迭代。
运维能力和服务治理的充实和优化,将作为后续版本的重要 Feature ,我们将会进一步完善流量治理、路由、Proxyless Service Mesh、还有文中提到的柔性负载均衡算法等方面,这些都是今年社区工作的重点。
Dubbo-go 生态,同开发者同在!
[1] https://github.com/apache/dubbo-go/issues/1685


























