













自监督学习能在各种任务中学习到分层特征,并以现实生活中可使用的海量数据作为资源,因此是走向更通用人工智能的一种途径,也是深度学习三巨头之一、图灵奖得主 Yann LeCun 一直推崇的研究方向。
LeCun 认为:相比于强化学习,自监督学习(SSL)可以产生大量反馈,能够预测其输入的任何一部分(如预测视频的未来画面),从而具有广泛的应用前景。
自监督学习通过直接观察环境来进行学习,而非通过有标签的图像、文本、音频和其他数据源进行学习。然而从不同模态(例如图像、文本、音频)中学习的方式存在很大差异。这种差异限制了自监督学习的广泛应用,例如为理解图像而设计的强大算法不能直接应用于文本,因此很难以相同的速度推动多种模态的进展。
现在,MetaAI(原 Facebook AI)提出了一种名为 data2vec 的自监督学习新架构,在多种模态的基准测试中超越了现有 SOTA 方法。

data2vec 是首个适用于多模态的高性能自监督算法。Meta AI 将 data2vec 分别应用于语音、图像和文本,在计算机视觉、语音任务上优于最佳单一用途算法,并且在 NLP 任务也能取得具有竞争力的结果。此外,data2vec 还代表了一种新的、全面的自监督学习范式,其提高了多种模态的进步,而不仅仅是一种模态。data2vec 不依赖对比学习或重建输入示例,除了帮助加速 AI 的进步,data2vec 让我们更接近于制造能够无缝地了解周围世界不同方面的机器。data2vec 使研究者能够开发出适应性更强的 AI,Meta AI 相信其能够在多种任务上超越已有系统。

- 论文地址:https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
- 项目地址:https://github.com/pytorch/fairseq/tree/main/examples/data2vec
论文一作 Meta AI 研究员 Alexei Baevski 表示:我们发布了最新 SSL 方法 data2vec,与单独训练相比,我们在具有相同预训练任务的视觉、语音和 NLP 上获得了 SOTA。语音和文本的代码和模型已经发布,视觉模型代码即将到来!
即将成为 Meta CTO 的 Boz(领导 Reality Labs 团队的 AR、VR、AI、Portal 等)也发推表示:很高兴 data2vec 能够帮助为跨多种模态的、更通用的自监督学习铺平道路——这项工作还将对我们正在构建的 AR 眼镜开发情境化 AI 产生重大影响。

data2vec 是如何工作的?
大部分 AI 仍然基于监督学习,它只适用于具有标注数据的任务。但是,假如我们希望机器可以完更多的任务,那么收集所有的标注数据将变得不现实。例如,虽然研究人员在为英语语音和文本创建大规模标注数据集方面做了大量工作,但对于地球上成千上万的语言来说,这样做是不可行的。
自监督使计算机能够通过观察世界,然后弄清楚图像、语音或文本的结构来了解世界。不需要专门训练就能对图像进行分类或理解语音的机器,其扩展性也会大大提高。
data2vec 训练方式是通过在给定输入的部分视图的情况下预测完整输入模型表示(如下动图所示):首先 data2vec 对训练样本的掩码版本(学生模型)进行编码,然后通过使用相同模型参数化为模型权重的指数移动平均值(教师模型)对输入样本的未掩码版本进行编码来构建训练目标表示。目标表示对训练样本中的所有信息进行编码,学习任务是让学生在给定输入部分视图的情况下预测这些表示。

data2vec 以相同的方式学习图像、语音和文本。
模型架构
Meta AI 使用标准的 Transformer 架构(Vaswani 等人,2017):对于计算机视觉,Meta AI 使用 ViT 策略将图像编码为一系列 patch,每个 patch 跨越 16x16 像素,然后输入到线性变换(Dosovitskiy 等人, 2020;Bao 等人,2021)。语音数据使用多层 1-D 卷积神经网络进行编码,该网络将 16 kHz 波形映射到 50 Hz 表示(Baevski 等人,2020b)。对文本进行预处理以获得子词(sub-word)单元(Sennrich 等人,2016;Devlin 等人,2019),然后通过学习的嵌入向量将其嵌入到分布空间中。
data2vec 还可以为不同模态预测不同的单元:图像的像素或视觉 token、文本的单词以及语音的学习清单。像素的集合与音频波形或文本段落非常不同,因此,算法设计与特定的模态紧密联系在一起。这意味着算法在每种模式下的功能仍然不同。

掩码:在输入样本作为 token 序列嵌入后,Meta AI 用学习的掩码嵌入 token 替换掩码单元的一部分,并将序列馈送到 Transformer 网络。对于计算机视觉,Meta AI 遵循 Bao 等人的分块掩码(block-wise)策略;对于语音,Meta AI 掩码潜在语音表示的跨度 ;对于语言,Meta AI 使用掩码 token 。
训练目标:Meta AI 预测的表示是上下文表示,不仅对特定的时间步长进行编码,还对来自样本的其他信息进行编码,这是由于在 Transformer 网络中使用了自注意力,这是与 BERT、wav2vec 2.0 或 BEiT、MAE、SimMIM 和 MaskFeat 重要区别,这些预测目标缺乏上下文信息。
面向多种模态:data2vec 通过训练模型来简化其方法,以预测输入数据的表征。没有预测视觉 token、词、声音等的方法,而是专注于预测输入数据的表征,单个算法就可以处理完全不同类型的输入。这消除了学习任务中对特定模态目标的依赖。
直接预测表征并不简单,它需要为任务定义一个稳健的特征归一化,以对不同的模态都是可靠的。该研究使用教师网络首先从图像、文本或语音中计算目标表征。然后掩码部分输入并使用学生网络重复该过程,然后预测教师网络的潜在表征。即使只能查看部分信息,学生模型也必须预测完整输入数据的表征。教师网络与学生模型相同,但权重略有不同。
实验及结果
该研究在 ImageNet 计算机视觉基准上测试了该方法,结果如下。
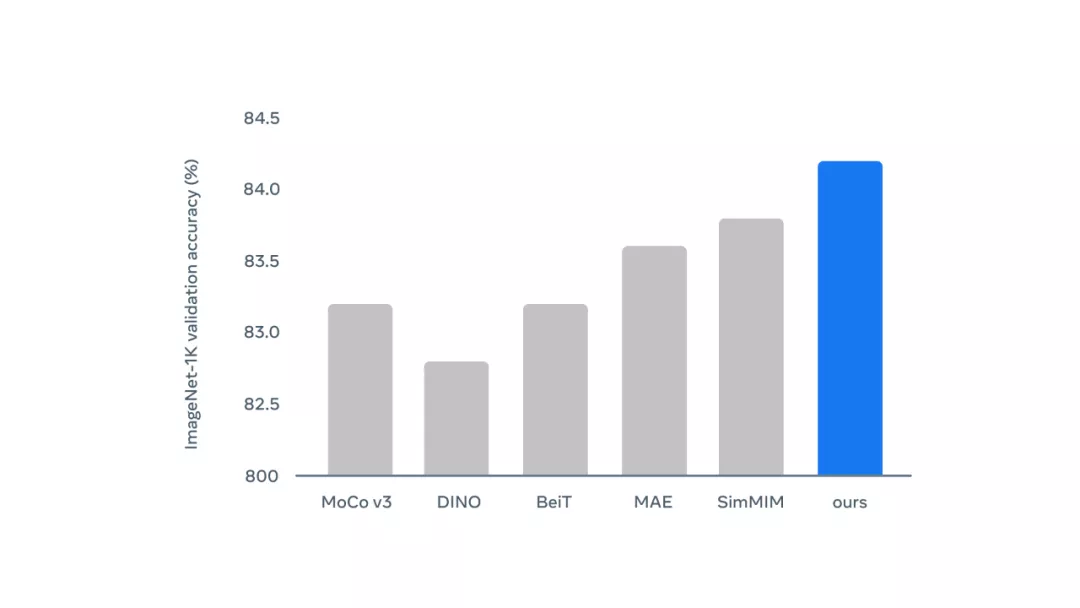
用于计算机视觉的 data2vec:在 ImageNet 基准上,ViT-B 模型与其他方法的性能比较结果。
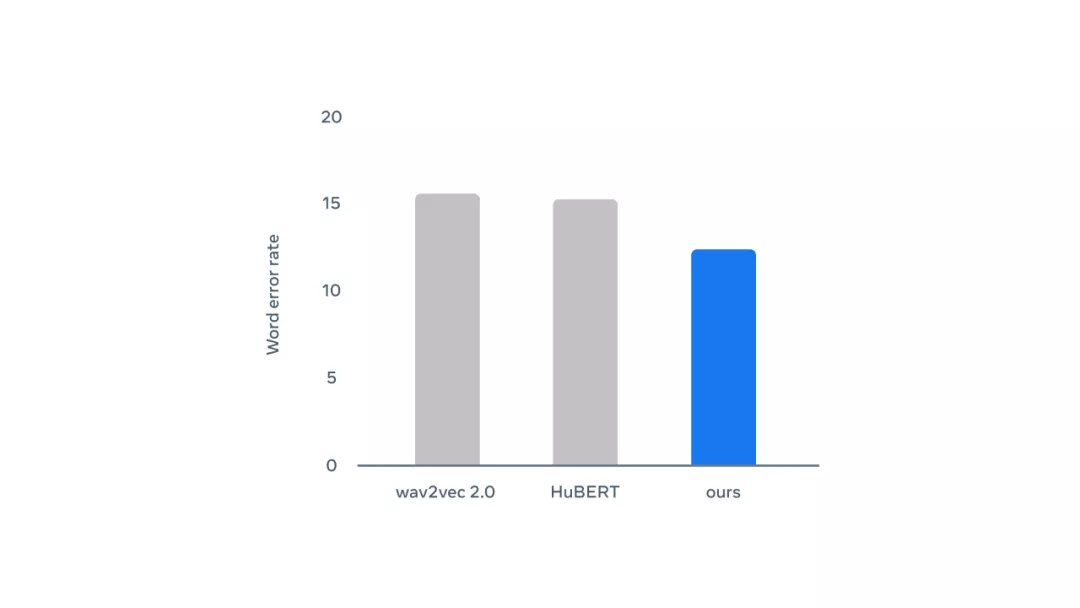
应用于语音的 data2vec:在 LibriSpeech 基准测试中使用 10h 标记数据的 Base 模型与其他方法的性能比较结果,错误率越低,性能越好。
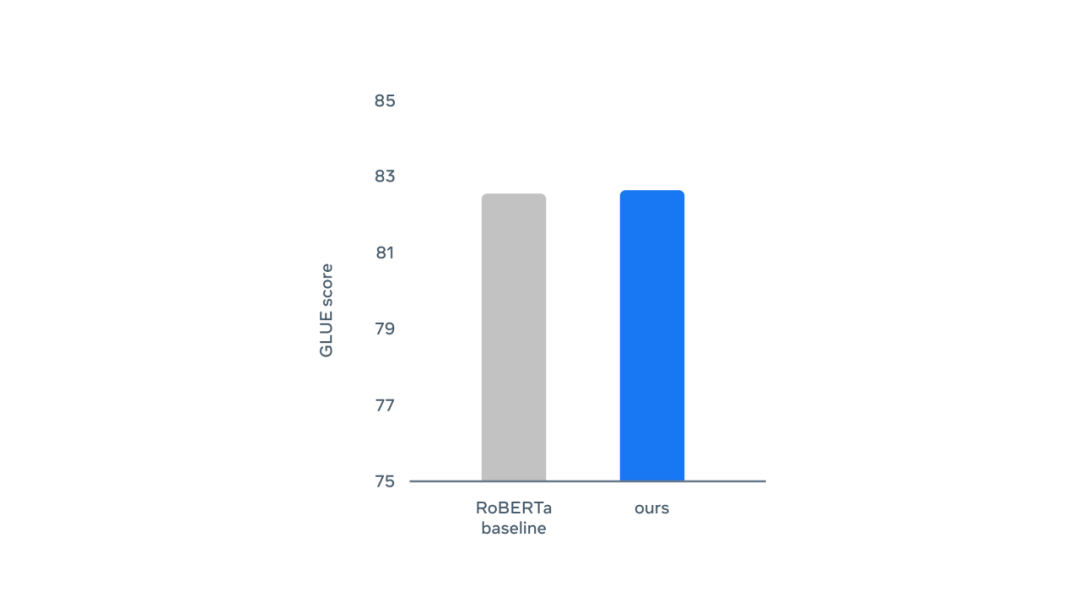
应用于文本的 data2vec:在使用原始 BERT 设置重新训练时,与 RoBERTa 相比,Base 模型在 GLUE 自然语言理解基准上的性能。分数越高,性能越好。
通过观察进行学习
自监督学习在计算机视觉、视频等多种模态方面取得了很大进展。这种方法的核心思想是为了更广泛地学习,以使人工智能可以学习完成各种任务,包括完全未见过的任务。研究者希望机器不仅能够识别训练数据中显示的动物,而且还能通过给定描述识别新生物。
data2vec 证明其自监督算法可以在多种模态下良好执行,甚至比现有最佳算法更好。这为更一般的自监督学习铺平了道路,并让人工智能更接近使用视频、文本、音频来学习复杂世界的目标。
由于收集高质量数据成本很高,因此该研究还希望 data2vec 能让计算机仅用很少的标记数据来完成任务。data2vec 是迈向更通用人工智能的重要一步,未来有望消除对特定模态特征提取器的需求。


























