













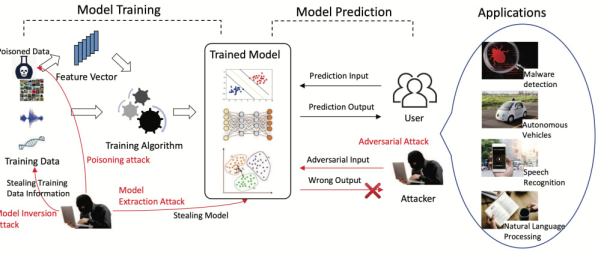
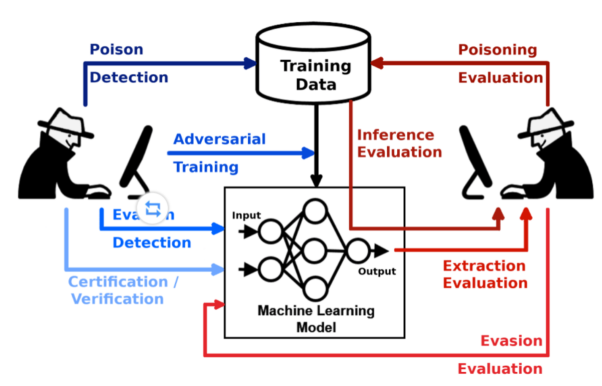
对抗性机器学习(Adversarial machine learning)主要是指在对攻击者的能力、及攻击后果的研究与理解的基础上,设计各种能够抵抗安全挑战(攻击)的机器学习(ML)算法。
对抗性机器学习认为,机器学习模型通常会面临如下四种类型的攻击:
提取式攻击(Extraction attacks)
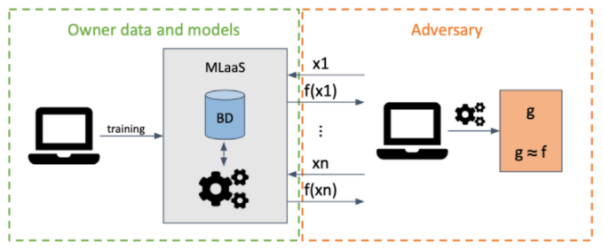
在上图所示的提取式攻击模型中,攻击者只要获取了Oracle prediction的访问权限,就会窃取那些远程部署的机器学习模型的副本。此类攻击的背后原理是,攻击者通过输入,向目标模型发出请求,以提取尽可能多的信息,并使用掌握到的输入和输出集,来产生并训练一个替代模型(substitute model)。
当然,该提取模型在实施的过程中会有一定的困难,攻击者需要通过强劲的计算能力,来重新训练具有准确性和保真度的新模型,以从头开始替代现有的模型。
防御
当模型对给定输入进行分类时,我们需要限制其输出信息。目前,我们可以采取的方法包括:
- 使用差分隐私(Differential Privacy)。
- 使用集成算法(ensembles,译者注:是通过构建并结合多个机器学习模型,来完成学习任务)。
- 在最终用户与PRADA(https://arxiv.org/abs/1805.02628)等模型之间构建代理。
- 限制请求的数量。
推理攻击(Inference attacks)
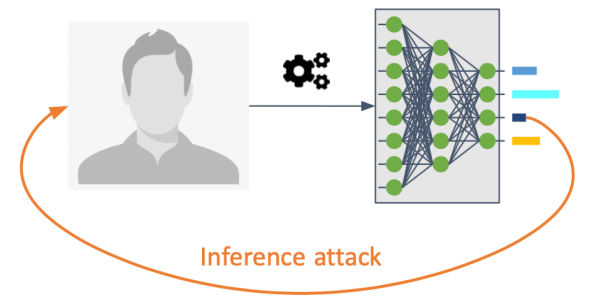
推理攻击旨在通过反转机器学习模型中的信息流,以方便攻击者洞察到那些并未显式共享的模型。从统计学的角度来说,由于私有的机密数据往往与公开发布数据有着潜在的相关性,而机器学习的各种分类器(classifier)具有捕捉到此类统计相关性的能力,因此推理攻击会给个人和系统构成严重的隐私和安全威胁。
通常,此类攻击会包括三种类型:
- 成员推理攻击(Membership Inference Attack,MIA,译者注:通过识别目标模型在行为上的差异,来区分其中的成员和非成员)。
- 属性推理攻击(Property Inference Attack,PIA,译者注:攻击者利用公开可见的属性和结构,推理出隐蔽或不完整的属性数据)。
- 恢复训练数据(Recovery training data,译者注:试图恢复和重建那些在训练过程中使用过的数据)。
防御
使用各种高级加密措施,其中包括:
- 差分加密(Differential cryptography)。
- 同态加密(Homomorphic cryptography)。
- 安全的多方计算(Secure Multi-party Computation)。
- Dropout(译者注:在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率,将其暂时从网络中丢弃)等技术。
- 模型压缩(译者注:通过减少算法模型的参数,使算法模型小型化)。
投毒攻击(Poisoning attacks)
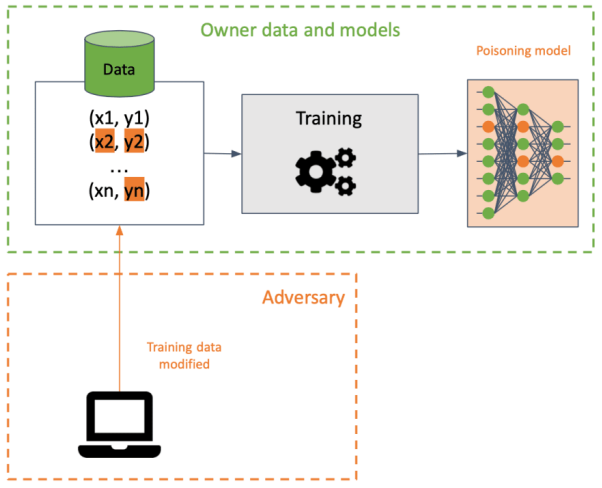
投毒攻击技术是指攻击者在训练数据集中插入损坏性数据,以在训练的过程中破坏目标的机器学习模型。计算机视觉系统在面对特定的像素模式进行推理时,会被此类数据投毒技术触发某种特定的行为。当然,也有一些数据投毒技术,旨在降低机器学习模型在一个或多个输出类别上的准确性。
由于此类攻击可以在使用相同数据的不同模型之间进行传播,因此它们在训练数据上执行的时候,很难被检测到。据此,攻击者会试图通过修改决策边界,来破坏模型的可用性,从而产生各种不正确的预测。
此外,攻击者还会在目标模型中创建后门,以便他们创建某些特定的输入,进而产生可被操控的预测,以及方便后续攻击的结果。
防御
- 保护训练数据的完整性。
- 保护算法,并使用各种健壮的方法去训练模型。
规避攻击(Evasion attacks)
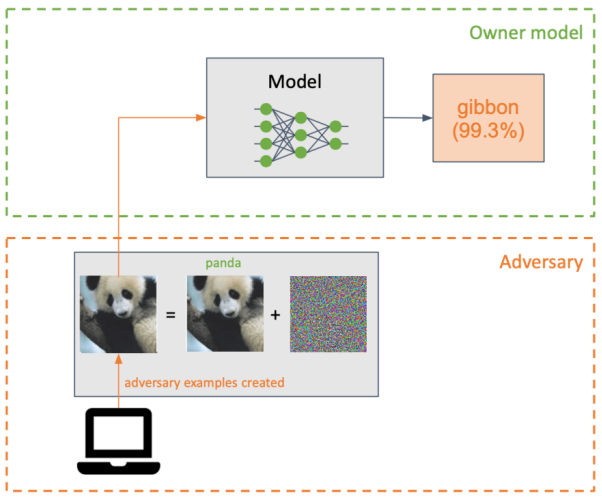
攻击者通过插入一个细微的扰动(如某种形式的噪声),并转换成某个机器学习模型的输入,并使之产生分类错误。
虽然与投毒攻击有几分类似,但是规避攻击主要尝试的是,在推理阶段、而不是在训练中,利用模型的弱点。当然,攻击者对于目标系统的了解程度是至关重要的。他们对于目标模型、及其构建方式越了解,就越容易对其发起攻击。
规避攻击通常发生在,当某个网络中被输入了“攻击性样本(adversarial example)”时。这往往是一种被“精心构造”扰动性输入。它看似与那些未被篡改的副本相同,但实际上完全避开了正确的分类器。
防御
- 通过训练,使用健壮的模型,来对抗攻击性样本。
- 将“消毒”过的输入馈入模型。
- 采取梯度正则化(Gradient regularization)。
各类实用工具
对抗性鲁棒工具箱
对抗性鲁棒工具箱(Adversarial Robustness Toolbox,ART,https://github.com/Trusted-AI/adversarial-robustness-toolbox)是一种可用于机器学习的安全类Python库。由ART提供的工具可让开发与研究人员,去评估和防御应用程序、及其所用到的机器学习模型,进而抵御上面提到的四类威胁与攻击。
ART能够支持时下流行的机器学习框架,例如:TensorFlow、Keras、PyTorch、以及scikit-learn。而它支持的数据类型包括:图像、数据表、音频、以及视频等。同时,它还支持分类、物体检测、以及语音识别等机器学习任务。您可以通过命令:pip install adversarial-robustness-toolbox,来安装ART。
ART的攻击示例如下代码段所示:
from art.attacks.evasion import FastGradientMethod
attack_fgm = FastGradientMethod(estimator = classifier, eps = 0.2)
x_test_fgm = attack_fgm.generate(x=x_test)
predictions_test = classifier.predict(x_test_fgm)
其对应的防御示例为:
from art.defences.trainer import AdversarialTrainer
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=tf.keras.optimizers.Adam(lr=0.01), metrics=["accuracy"])
defence = AdversarialTrainer(classifier=classifier, attacks=attack_fgm, ratio=0.6)
(x_train, y_train), (x_test, y_test), min_pixel_value, max_pixel_value = load_mnist()
defence.fit(x=x_train, y=y_train, nb_epochs=3)
Counterfit
Counterfit是一种命令行工具和通用的自动化层级,可以被用于评估机器学习系统的安全性。基于ART和TextAttack(译者注:是一种Python框架,可用于NLP中的对抗性攻击、数据增强和模型训练)的Counterfit,是专为机器学习模型的安全审计而开发的,可实现黑盒式的规避算法。Counterfit包括如下实用命令:
--------------------------------------------------------
Microsoft
__ _____ __
_________ __ ______ / /____ _____/ __(_) /_
/ ___/ __ \/ / / / __ \/ __/ _ \/ ___/ /_/ / __/
/ /__/ /_/ / /_/ / / / / /_/ __/ / / __/ / /
\___/\____/\__,_/_/ /_/\__/\___/_/ /_/ /_/\__/
#ATML
--------------------------------------------------------
list targets
list frameworks
load <framework>
list attacks
interact <target>
predict -i <ind>
use <attack>
run
scan
可深入研读的参考链接
译者介绍
陈 峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:Adversarial Machine Learning: A Beginner’s Guide to Adversarial Attacks and Defenses,作者: Miguel Hernández






















