一 前言
Garner预测,到2022年,所有数据库中有75%将部署或迁移至云平台。另外一家权威机构IDC也预测,在2025年,超过50%的数据库将部署在公有云上,而中国则会达到惊人的70%以上。云数据库经过多年发展,经历从Cloud-Hosted (云托管)到 Cloud Native(云原生)模式的转变。
Cloud-Hosted:基于市场和业界的云需求,大部分厂商选择了云托管作为演进的第一步。这种模式将不再需要用户线下自建IDC,而是依托于云提供商的标准化资源将数据仓库进行移植并提供高度托管,从而解放了用户对底层硬件的管理成本和灵计划资源的约束。
Cloud-Native:然而随着更多的业务向云上迁移,底层计算和存储一体的资源绑定,导致用户在使用的过程中依然需要考量不必要的资源浪费,如计算资源增加会要求存储关联增加,导致无效成本。用户开始期望云资源能够将数据仓库进行更为细粒度的资源拆解,即对计算,存储的能力进行解耦并拆分成可售卖单元,以满足业务的资源编排。到这里,云原生的最大化价值才被真正凸显,我们不在着重于打造存算平衡的数据仓库,而是面向用户业务,允许存在大规模的计算或存储倾斜,将业务所需要的资源进行独立部署,并按照最小单位进行售卖。这一刻我们真正的进入了数据仓库云原生时代。
阿里云在2021云栖大会上,预告了全新云原生架构的数据仓库【1】。本文介绍了云原生数据仓库产品AnalyticDB PostgreSQL(以下简称ADB PG)从Cloud-Hosted到Cloud-Native的演进探索,探讨为了实现真正的资源池化和灵活售卖的底层设计和思考,涵盖内容包括产品的架构设计,关键技术,性能结果,效果实现和后续计划几方面。(全文阅读时长约为10分钟)
二 ADB PG云原生架构
为了让用户可以快速的适配到云数据仓库,目前我们采用的是云上MPP架构的设计理念,将协调节点和计算节点进行独立部署,但承载于单个ECS上,实现了计算节点存储计算一体的部署设计,该设计由于设计架构和客户侧自建高度适配,可快速并无损的将数仓业务迁移至云上,对于早期的云适配非常友好且满足了资源可平行扩展的主要诉求。随着云原生的进一步演进,我们提供了全新的存算分离架构,将产品进一步拆分为服务层、计算层和共享存储层,架构图如下:
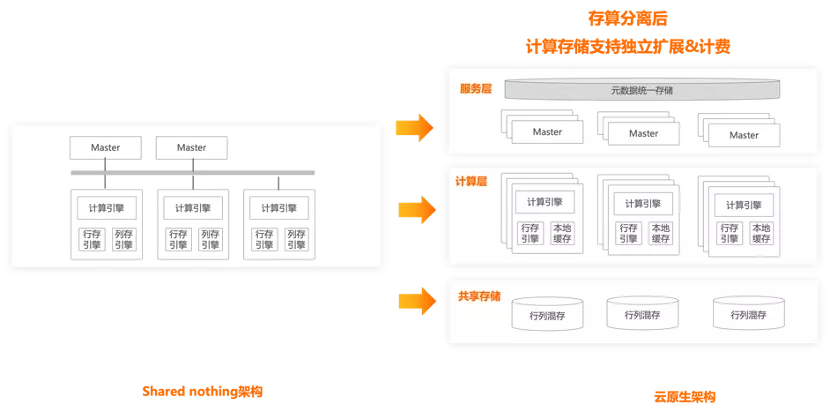
Master协调节点:保存全局的schema信息,并实现了全局事务管理;行存引擎:用来保存元数据信息,这里的元数据信息主要指共享存储文件的可见性信息,包括两个部分:
- 一个是文件与表的关系
- 另外一个是被删除的数据的delete bitmap
基于行存我们可以继承PG的本地事务能力,在增删改查的同时,与PG的事务能力完全兼容;
本地缓存:通过引入存储团队的DADI来实现高性能的本地缓存,DADI全称是Alibaba Cloud Data Accelerator for Disaggregated Infrastructure,相比开源产品,性能有数量级的提升;
共享存储:我们借鉴了ClickHouse的一些关键设计,在存储层实现了一个基于MergeTree的行列混存,此外我们对共享存储基于文件接口做了一层统一访问接口,同时高度适配了OSS和HDFS 两种形态的分布式文件系统;
当我们在架构设计的时候,和同样源自Greenplum的HAWQ对比,HAWQ把元数据都保存在master,在每次写的时候,把修改的元数据带到master来更新,读的时候,先从master读取需要的元数据,然后在执行计划里面把元数据都带上,这样segment就能拿到对应的元数据, 同时segment可以完全无状态。但是这个设计会带来2个核心问题:
1. 元数据膨胀导致master成为瓶颈。
2. 受限于元数据的性能,无法支持高并发的实时写入。而我们不这样设计做的原因是我们希望在未来能够支持高并发的任务,ADB PG大概花了2年多的时间,将Greenplum的单点master架构拓展为multi-master,核心是为了解决高并发实时写入的问题,如果把元数据都保存在master上会带来如问题:1. master上面的元数据存储和访问容易形成单点瓶颈2. 需要对ADB PG的执行层做大量的重构,实现在执行计划里面把元数据都带上,这会急剧的增加查询计划本身的带宽,这个对于高并发的小查询非常不友好。所以我们改进了架构,将元数据分散到segment,规避并实现了:
1. master的存储和读写都不会成为瓶颈
2. 无需对执行层做重构,将元数据分散减少单次查询的带宽压力。
3. 将segment上的元数据放到分布式kv上,解决扩缩容的元数据搬迁问题。
共享存储使用OSS的原因在于,随着单个用户业务数据不断增长,需要一个可持续发展的存储方案,而OSS的低存储成本,高可用性和数据持久性是最好的选择。
维度 | OSS | ESSD云盘(PL1) |
成本 | 0.56元/GB/月 | 2元/GB/月 |
高可用 | 99.995% | 99.975% |
数据持久性 | 99.9999999999%(12个9) | 99.9999999%(9个9) |
使用OSS的另外一个好处在于按需付费,用户不需要预制存储空间大小,存了多少数据,付多少钱,数据删除后即不再收费;ESSD云盘通常需要根据数据计算存储水位,无法做到将存储资源真正的按需供应,而且无法自动缩容,这些都违背了我们云原生的设计理念。但同时OSS的劣势在于RT:
维度 | OSS | ESSD云盘(PL1) |
RT | 50 ms | 200us |
为了解决OSS的RT问题,我们为计算节点配置了一定比例的本地盘,用来做访问加速。此外,我们设计了一个高性能的行列混存,借鉴了ClickHouse mergetree存储的核心思想,以有序为核心,文件内绝对有序,文件与文件大致相对有序,通过merge的异步操作,实现文件和并和排序,基于有序,我们在文件内设计了3层的统计信息,并做了大量的IO裁剪优化。
下面我们对每个技术点做进一步介绍。
三 关键技术
1 弹性伸缩
为了实现快速的弹性伸缩,我们的方式是数据在共享存储上hash bucket来组织,扩缩容后通过一致性hash把计算节点和bucket做重新映射,为了解决bucket与segment分配的均匀性,并降低扩缩容后cache失效的影响,我们对传统的一致性hash算法做了改进,支持扩缩容时的动态映射。
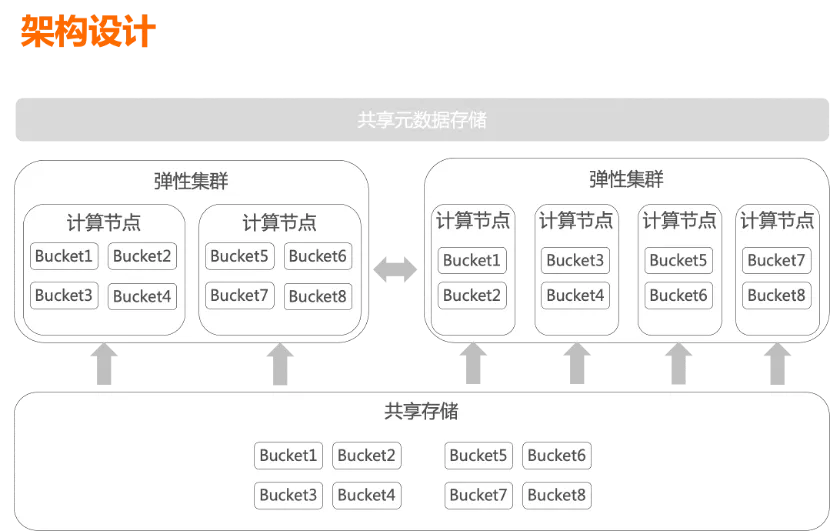
把数据根据hash bucket分成多个分片,按分片粒度在扩缩容的重新映射对象存储上的数据。如果扩容计算节点超过分片个数的时候,只能重分布数据。为了解决这个问题,我们支持hash bucket可以后台分裂和合并,避免重新分布数据。
上述是扩缩容时“数据”的重现映射,而描述数据文件可见性的元数据,由于保存在行表中,我们还是使用了Greenplum的数据重分布策略,不同的是,为了加速元数据的重分布,我们做了并行化分布等优化。我们以扩容为例进一步细化扩容的流程:
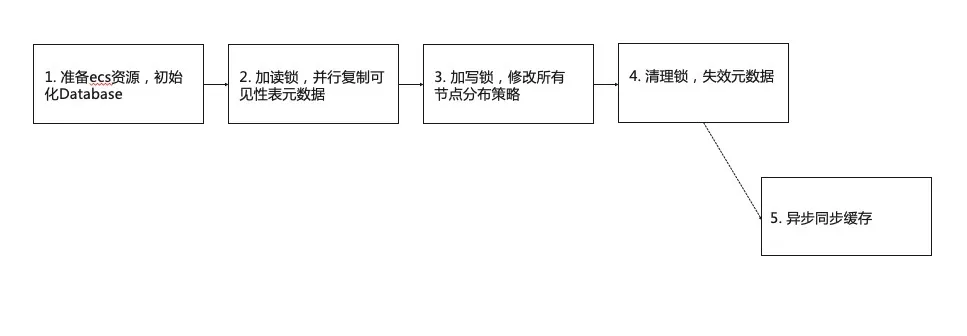
结合ECS资源池化,网卡并行加载和docker镜像预热等技术,16节点内端到端的耗时接近1分钟。
2 分层存储
分层存储的实现如下:
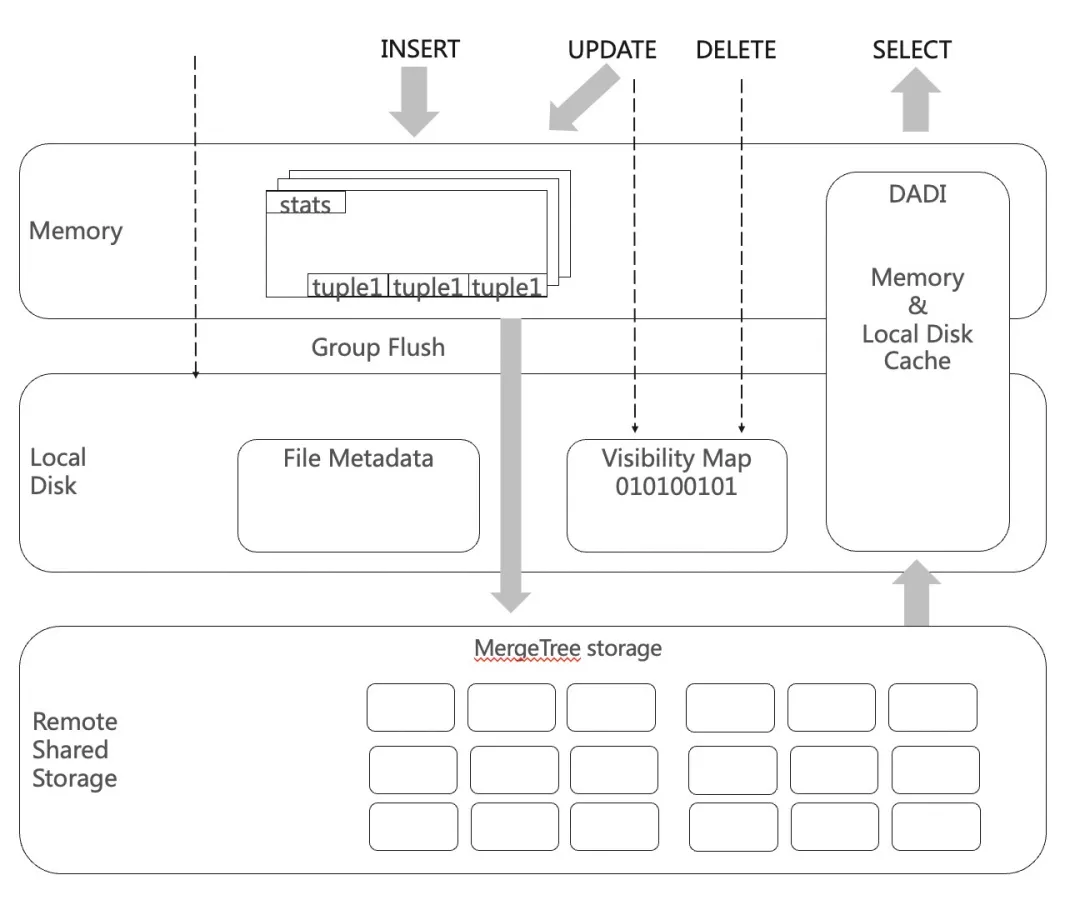
如上图所示,我们把存储的资源分成3层,包括内存、本地盘和共享存储。内存:主要负责行存访问加速,并负责文件统计信息的缓存;本地盘:作为行存的持久化存储,并作为远端共享存储的本地加速器;远端的共享存储:作为数据的持久化存储。
3 读写流程
写入流程如下:
- 用户写入数据通过数据攒批直接写入OSS,同时会在本地磁盘上记录一条元数据。这条元数据记录了,文件和数据表的对应关系。元数据使用PG的行存表实现,我们通过file metadata表来保存这个信息。
- 更新或者删除的时候,我们不需要直接修改OSS上面的数据,我们通过标记删除来实现,标记删除的信息也是保存在本地行存表中,我们通过visibility bitmap来存这个信息。标记删除会导致读的性能下降,我们通过后台merge来应用删除信息到文件,减少删除带来的读性能影响。
我们在写入的时候,是按照bucket对segment上的数据做了进一步划分,这里会带来小文件的问题。为了解决小文件问题,我们做了下面几点优化:
1. Group flush:一批写入的数据,可以通过group flush写到同一个OSS文件,我们的OSS文件采用了ORC格式,不同bucket写入到对应strip;
2. 流水线异步并行:编码攒批,排序是典型的cpu密集型任务,上传到oss是典型的网络IO密集型任务,我们会把这2种任务类型并行起来,在上传oss的任务作为异步任务执行,同时对下一批数据编码排序,加快写入性能。
因为远端持久化存储提供了12个9的持久性,所以只有保存元数据的行存才有WAL日志和双副本来保证可靠性,数据本身写穿到共享存储,无需WAL日志和多副本,由于减少了WAL日志和WAL日志的主备同步,又通过异步并行和攒批,在批量写入场景,我们写入性能做到了基本与ECS弹性存储版本性能持平。
读取流程如下:
- 我们通过读取file metadata表,得到需要扫描的OSS文件。
- 根据OSS文件去读取对应文件。
- 读到的文件通过元数据表visibility bitmap过滤掉已经被删除的数据。
为了解决读OSS带来的延迟,我们也引入了DADI帮忙我们实现缓存管理和封装了共享文件的访问,读文件的时候,首先会判断是否本地有缓存,如果有则直接从本地磁盘读,没有才会去 OSS读,读到后会缓存在本地。写的时候会直写OSS,并回写本地磁盘,回写是一个异步操作。对于本地缓存数据的淘汰我们也通过DADI来管理,他会根据LRU/LFU策略来自动淘汰冷数据。
由于事务是使用PG的行存实现,所以与ADB PG的事务完全兼容,带来的问题是,我们在扩缩容的时候需要重新分布这部分数据,我们重新设计了这块数据的重分布机制,通过预分区,并行拷贝,点对点拷贝等技术,极大缩短了扩缩容时间。
总结一下性能优化点:• 通过本地行存表实现事务ACID,支持数据块级别的并发;
- 通过Batch和流水线并行化提高写入吞吐;
- 基于DADI实现内存、本地SSD多级缓存加速访问。
4 可见性表
我们在File Metadata中保存了共享存储文件相关的信息,它的结构如下:
字段 | 类型 | 说明 |
table_oid | Int32 | 表的oid |
hash_bucket_id | Int16 | hash_bucket的id |
level | Int16 | 逻辑文件所处的merge级别,0表示delta文件 |
physical_file_id | Int64 | 逻辑文件对应的oss物理文件id |
stripe_id | Int64 | 逻辑文件对应的oss物理文件中的stripe id |
Total_count | int32 | 逻辑文件总共具有的行数,包括被删除行数 |
Hash bucket:是为了在扩缩容的时候搬迁数据的时候,能够按照bucket来扫描,查询的时候,也是一个bucket跟着一个bucket;Level:是merge tree的层次,0层代表实时写入的数据,这部分数据在合并的时候有更高的权重;Physical file id:是文件对应的id,64字节是因为它不再与segment关联,不再只需要保证segment内table的唯一性,需要全局唯一;Stripe id:是因为一个oss文件可以包含多个bucket 的文件,以stripe为单位,方便在segment一次写入的多个bucket合并到一个oss文件中。避免oss小文件,导致性能下降,和oss小文件爆炸;Total count:是文件行数,这也是后台合并的一个权重,越大合并的权重越低 。
Visibility bitmap记录了被删除的文件信息
字段 | 类型 | 说明 |
physical_file_id | Int64 | 逻辑文件对应的oss物理文件id |
stripe_id | Int32 | 逻辑文件对应的oss物理文件中的stripe id |
start_row | Int32 | delete_bitmap对应的起始行号,每32k行对应一个delete_bitmap |
hash_bucket_id | Int16 | hash_bucket的id |
delete_count | Int32 | 该delete_bitmap总共记录删除了多少行 |
bitmap | bytea | delete_bitmap的具体数值,压缩存储 |
Start_row对应32k对应一个delete bitmap。这个32000 4k,行存使用的32k的page可以保存7条记录。Delete count是被删除的数量。我们无需访问oss,可以直接得到需要merge的文件,避免访问oss带来的延迟,另外oss对于访问的吞吐也有限额,避免频繁访问导致触发oss的限流。
5 行列混存
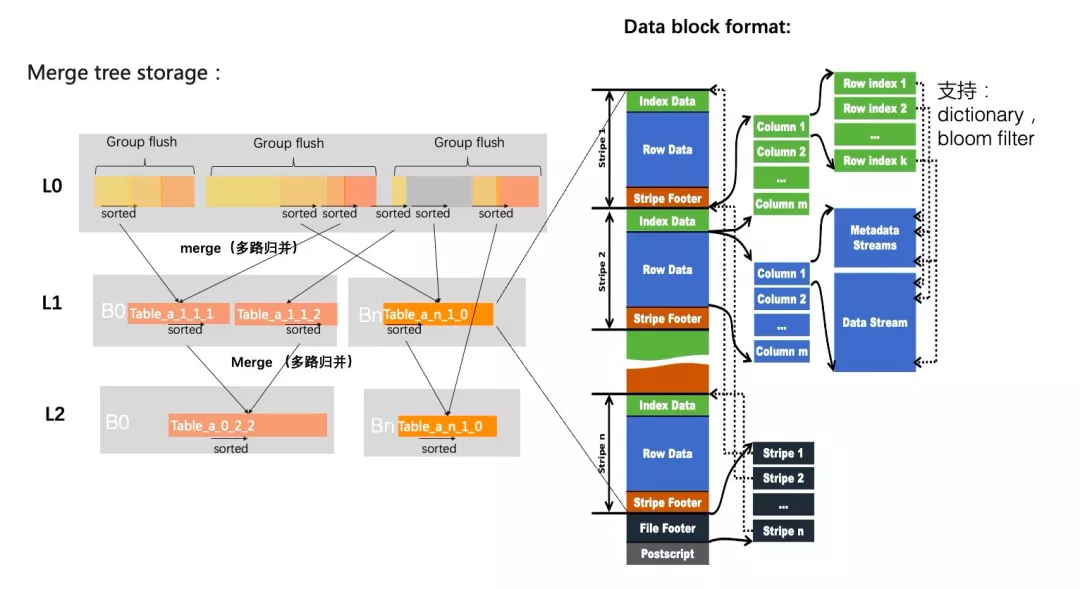
Mergetree的结构如上图左侧所示,核心是通过后台merge的方式,把小文件merge成有序的大文件,并且在merge的时候,我们可以对数据重排,例如数据的有序特性做更多的优化,参考后续的有序感知优化。与leveldb的不同在于:
1. 0层实时写入的会做合并,不同bucket的文件会合并成大文件,不同bucket会落到对应的stripe;
2. Merge会跨层把符合merge的文件做多路归并,文件内严格有序,但是文件间大致有序,层数越高,文件越大,文件间的overlap越小。
每个文件我们使用了行列混存的格式,右侧为行列混存的具体的存储格式,我们是在ORC的基础上做了大量优化。
ORC文件:一个ORC文件中可以包含多个stripe,每一个stripe包含多个row group,每个row group包含固定条记录,这些记录按照列进行独立存储。
Postscript:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息,数据字典等)、所有stripe的信息和文件schema信息。
stripe:stripe是对行的切分,组行形成一个stripe,每次读取文件是以行组为单位的,保存了每一列的索引和数据。它由index data,row data和stripe footer组成。
File footer:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
Index data:保存了row group级别的统计信息。
Data stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定,下面以integer和string 2种类型举例说明:
对于一个Integer字段,会同时使用一个比特流和整形流。比特流用于标识某个值是否为null,整形流用于保存该整形字段非空记录的整数值。
String类型字段,ORC writer在开始时会检查该字段值中不同的内容数占非空记录总数的百分比不超过0.8的话,就使用字典编码,字段值会保存在一个比特流,一个字节流及两个整形流中。比特流也是用于标识null值的,字节流用于存储字典值,一个整形流用于存储字典中每个词条的长度,另一个整形流用于记录字段值。如果不能用字典编码,ORC writer会知道这个字段的重复值太少,用字典编码效率不高,ORC writer会使用一个字节流保存String字段的值,然后用一个整形流来保存每个字段的字节长度。
在ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别。而提升存储性能的核心是减少IO,我们基于ORC的统计信息和索引实现各种下推,帮助我们实现IO裁剪。例如Projection下推,我们只会扫描需要物化的列。Agg下推中,我们会直接把需要的min,max,sum,unique从统计信息或者索引中读取即可返回,避免了对data stream的解压。对于predicate,我们还支持把filter下推,通过统计信息直接做过滤,直接跳过不符合的条件的stripe,我们支持各种操作符,以及in/not in,以及表达式的等价转换。
此外我们针对存储格式对性能还做了下面的优化:1. 零拷贝:为了把ORC的数据类型转换成PG数据类型,我们对于定长类型的做值拷贝,变长类型直接转换成PG的datum做指针引用。2. Batch Scan:面向column采用batch scan,替代逐行访问而是先扫完一列,再扫下一列,这样对CPU cache更加友好。3. 支持Seek read:方便过滤命中情况下的跳转。
6 本地缓存
DADI帮助我们实现2个能力,一个是高效的缓存管理,另外一个是统一存储访问。在了解DADI之前,我们可以首先看一下,DADI与开源解决方案从RT与throughput 2个维度做了对比测试:
维度 | RT | Throughput | ||
产品 | DADI | Alluxio-Fuse | DADI | Alluxio-Fuse |
命中内存 | 6~7 us | 408 us | 单线程: 4.0 GB/s四线程: 16.2 GB/s | 2.5 GB/s |
命中磁盘 | 127 us | 435 us | 四线程: 541 MB/s | 0.63 GB/s |
从中看到,DADI相比开源解决方案alluxio在内存命中的场景RT上有数量级的提升,在throughput上也有明显的优势。在命中磁盘的场景,也有明显的性能优势,在部分分析场景下,我们会频繁但是少量读取文件统计信息,这些统计信息我们会缓存在本地,这个优势带来整体性能的较大提升。
DADI在缓存命中场景下的性能优势,可以参考下面的架构:
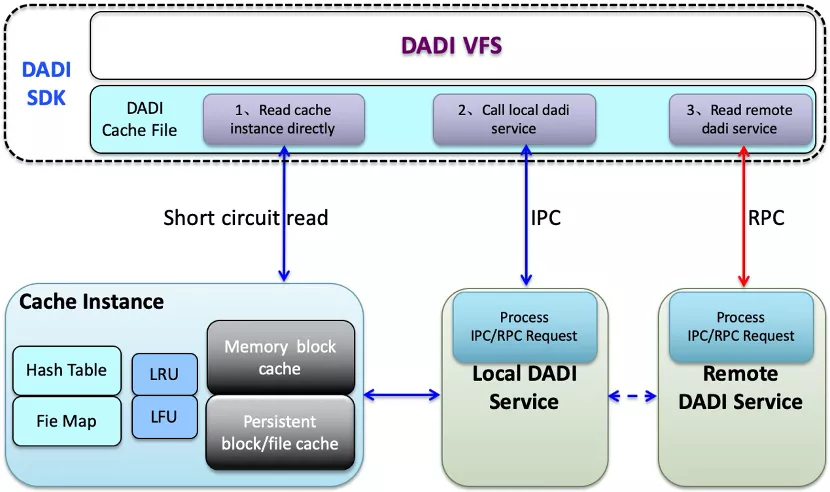
DADI SDK:通过标准读写接口访问存储,通过缓存是否命中,选择短路读(short circuit read),还是IPC进程通信访问Local DADI Service,或者访问远端的DADI Service,对应分布式缓存服务,作为lib库嵌入ADB PG的读写进程;Cache Instance:管理本地缓存,缓存文件抽象成虚拟块设备来访问,数据在memory和本次磁盘的冷热以block为单位管理。
这里的核心设计在于:
- 短路读,直接读共享内存,避免通过IPC读;
- 缓存是否命中的数据结构,也是在共享内存里面。通过reference count,结合robust mutex来保证共享内存数据的多线程安全;
- 磁盘读,100us,+ 27us约等于磁盘读本身rt,IPC走shm通信,没有使用本地socket通信。
4. 极低的资源使用。内存:DADI Service使用的内存在100~200M,原因在于基于共享内存的IPC实现,hash表等数据结构,避免多进程架构下内存膨胀, 精简的编码方式,1个内存页16k 对应 4byte的管理结构;CPU:Local DADI Service在磁盘打满的时候单核CPU使用20%左右。CPU的使用在SDK这边,SDK与Local DADI Service通信很少。
此外为了更好的发挥DADI在命中内存的优势,我们结合行列混存做了以下优化:
- 缓存优先级支持统计信息高优先级,常驻内存,索引信息常驻本地磁盘。支持维度表数据高优先级缓存在本地。
- 细粒度缓存策略为了避免大表冷数据访问,导致本地热数据被全部替换,大表使用专有缓存区。
- 文件异步预取根据查询情况,把解析的数据文件,预先读取到本地,这个过程不影响当前文件的读写,并且是异步的。
7 向量化执行
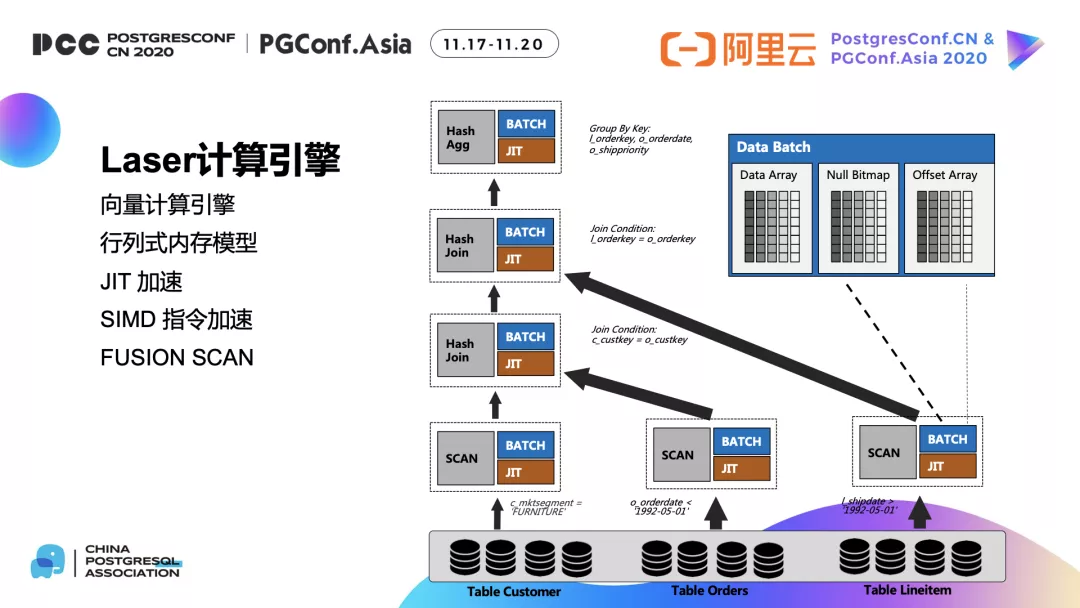
ADB PG云原生版本也同样支持向量化执行引擎,核心还是通过攒批的方式提高数据在CPU cache的命中率,通过codegen减少函数调用次数,减少复杂计算指令跳转,通过SIMD指令加速计算,通过内存池管理,降低算子间的内存拷贝,更多信息可以参考【3】。
8 有序感知
数据的有序主要用在2个方面,基于有序的IO裁剪,另外一个是尽量减少计算过程中的排序,IO裁剪在行列混存以及有较多的讨论,这里主要讨论第二点,这里我们做的主要工作有:
- 消除多余sorting操作。如果data本身有序,且满足排序要求,则不需要加sort操作。
- 最小化需要排序的列。例如希望对{c1,c2,..cn}排序,如果有谓词c1=5,则order简化成{c2,..cn},避免排序多一个字段。
- order下推。在初始化阶段,降意向排序操作尽量下推。
我们通过下列方法来生成sort scan的算子,查询SQL解析生成AST后,会根据一系列启发式规则做变换生成物理执行计划:
- 首先针对不同算子的有序性需求,例如(join/group by/distinct/order by),建立算子的interesting order(即这个算子期望的有序输入)。
- 其次在sort scan的过程中所生成的interesting order,会尽可能下推到下层算子中(sort-ahead),以尽早满足order属性要求。
- 如果一个算子具有多个interesting order,会尝试将他们合并,这样一个排序就可以满足多个order属性的需求。
此外就是sort scan算子的实现,存储层面只能保证文件内严格有序,文件的大致有序,我们通过多路归并的算法来实现。这里的问题在于sort scan的多路归并需要一条条读取数据,与向量化的batch scan与文件的批量读冲突,我们通过CBO来选主最优的执行计划。
9 细粒度并行
ADB PG是MPP架构,能够充分发挥节点间并行计算能力,云原生版本由于对数据按bucket做了切分,能帮助我们在节点内实现更细粒度的并行,我们以join为例说明:
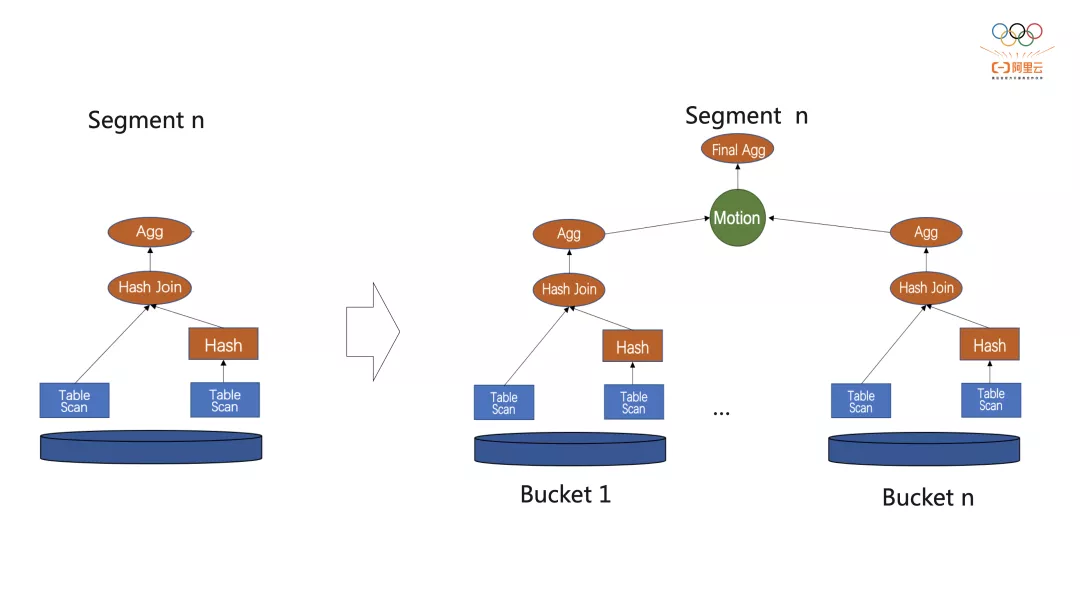
左边是没有节点内并行的join的执行计划,会起2个进程,一个做hash join的build,另外一个做probe,右边是节点内做了并行,我们会根据segment所分配的bucket来做并行,例如上图每个bucket的数据都可以并行的去做计算,由于数据是按照bucket做的划分,join key是分布健的时候,节点内并行也能完美命中local join的优化。
四 性能结果
1 扩缩容性能
计算资源扩容(节点数)2->44->88->1616->128
用时<1min<1min<1min<7min
2 读写性能
为了测试性能,我们使用了4*4C规格的实例,ADB PG的新版云原生与存储弹性版本做了性能对比测试。
写性能测试
测试表选用scale factor = 500的TPC-H lineitem表。通过同时执行不同并发数的copy命令,测得命令执行时间,用总数据量除以命令执行时间,得到吞吐量。
ADB PG 弹性存储 | ADB PG新版云原生 | |||||
并发数 | 1 | 4 | 8 | 1 | 4 | 8 |
COPY | 48MB/s | 77MB/s | 99MB/s | 45MB/s | 156MB/s | 141MB/s |
在单并发下新版本与存储弹性版本的性能差不多,主要在于资源都没有满;
在4并发下新版本的吞吐是存储弹性的2倍,原因在于使用lineitem表都定义了sort key,新版本在写入数据无需写WAL日志,另外攒批加上流水线并行相比弹性存储版本先写入,再merge,merge的时候也需要写额外的WAL有一定优势;
在8并发下新版本与4并发差不多,主要由于4C 4并发已经把CPU用满,所以再提升并发也没有提升。
读性能测试
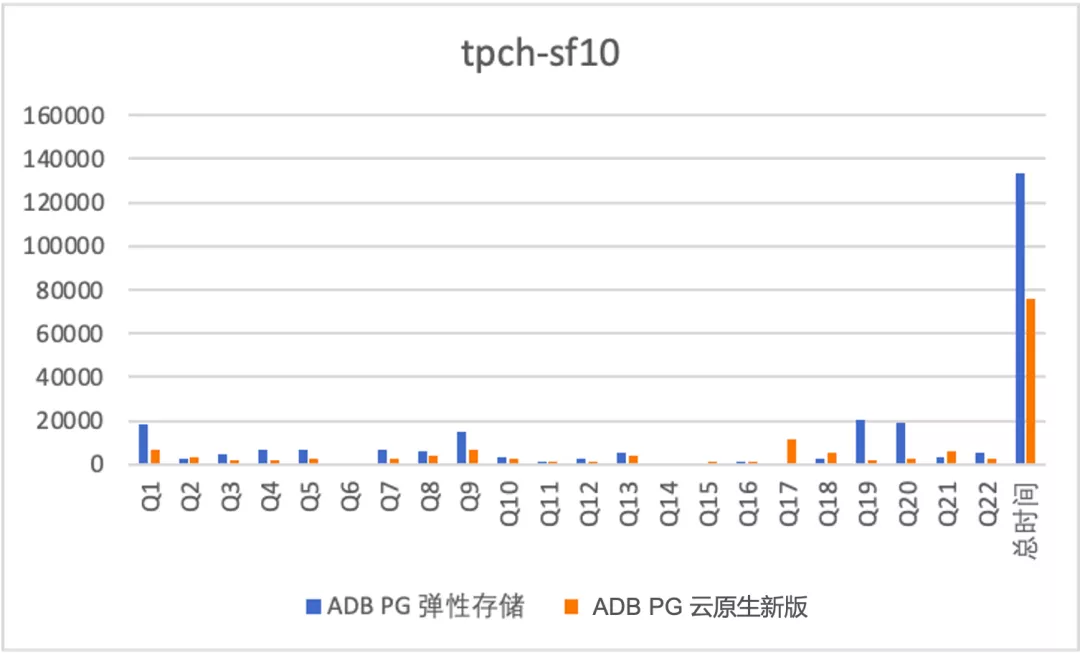
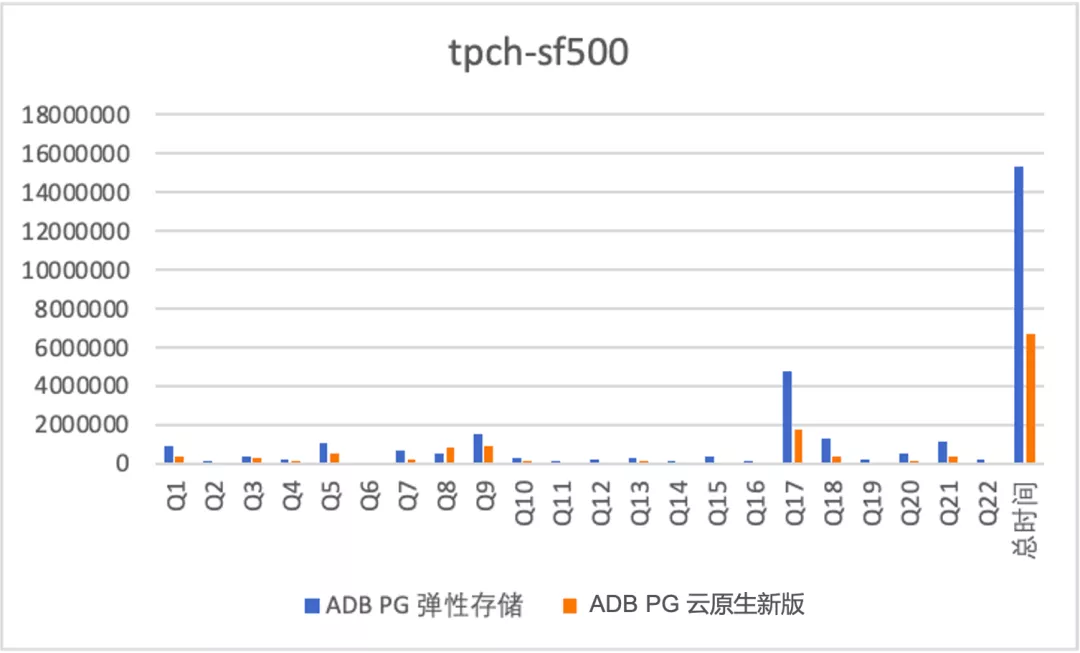
为了全面的测试读性能,我们针对3种场景做了测试:全内存:使用的是TPCH sf为10的数据集,会生成10G的测试数据集。全本地磁盘缓存:使用的是TPCH sf为500的数据集,会生成500GB的测试数据集。一半缓存,一半OSS:使用的是TPCH sf为2000的数据集,会生成2000GB的测试数据集。(本地磁盘缓存960GB)测试结果如下(纵轴为RT单位ms)
全内存
全本地磁盘缓存
一半本地缓存,一半OSS
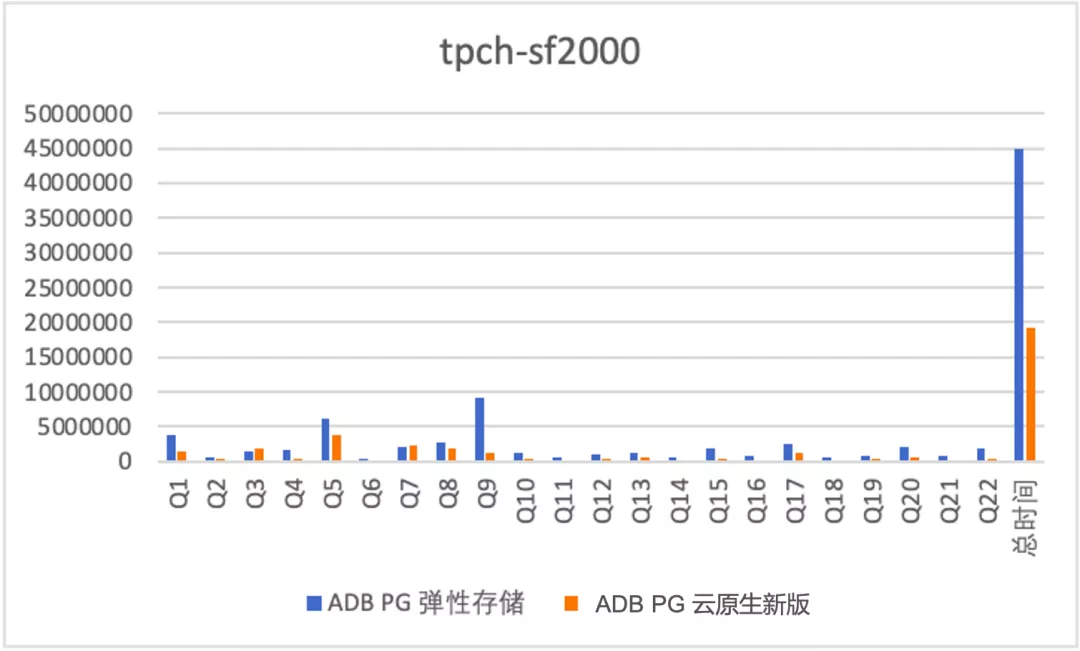
从上述测试结果来看:
- 云原生版本对比老的弹性存储版本均有1倍多的性能提升,原因在于细粒度并行带来的加速效果;
- 对于TPCH这种计算密集型的作业,即使数据一半缓存,一半OSS性能也不错,sf 2000数据量是sf 500的4倍,rt增加到原来的2.8倍,主要原因在于4*4C规格的实例没有到OSS的带宽瓶颈,另外由于本身读取的预取等优化。
五 总结
AnalyticDB PostgreSQL新版云原生是充分的将物理资源进行了池化,将存储和计算能力单元化进行分配,实现灵活的部署。这个特性为使用者提供极致的性价比,做到了算力的最优分配,同时降低用户使用的门槛,让用户专注于业务而无需将大量精力放在算力和存储的规划上,实现体验升级。
- 通过存储计算分离,用户可以根据业务负载模型,轻松适配计算密集型或存储密集型,存储并按使用计费,避免存储计算一体僵化而造成的资源浪费;
- 动态的适配业务负载波峰和波谷,云原生MPP架构计算侧使用了shared-nothing架构,支持秒级的弹性伸缩能力,而共享存储使得底层存储独立不受计算的影响。这降低了用户早期的规格选型的门槛,预留了后期根据业务的动态调整灵活性;
- 在存储计算分离基础上,提供了数据共享能力,这真正打破了物理机的边界,让云上的数据真正的流动了起来。例如数据的跨实例实时共享,可支持一存多读的使用模式,打破了传统数仓实例之间数据访问需要先导入,再访问的孤岛,简化操作,提高效率,降低成本。
六 后续计划
在上述存储分离的架构上,我们后续主要有3个大的方向:
- 能力补齐,这块主要是补齐当前版本的一些限制,例如Primary key,索引,物化视图,补齐写入的能力;
- 性能持续优化,主要优化缓存没有命中场景;
- 云原生架构持续升级,这块主要是在当前存储计算分离架构下,进一步提升用户体验;
在云原生升级我们主要有2个重点方向:
- 存算分离往Serverless再进一步,扩缩容无感。会进一步把元数据和状态也从计算节点剥离到服务层,把segment做成无状态的,这样的好处在于扩缩容能做到用户无感,另外一个好处在于segment无状态有利于提高系统高可用能力,当前我们还是通过主备模式提供高可用,当有节点故障的时候,主备切换缓存失效性能会急剧下降,segment无状态后我们会直接将它提出集群,通过“缩容”的方式继续提高服务。
- 应用跨实例的数据共享。此外对于分析型业务,数据规模大,以TB起步,传统数仓采用烟囱式架构,数据冗余,数据同步代价高的问题,我们希望提供跨实例的数据共享能力,重构数仓架构。
云原生版本将于2022年2月正式商业化发布,想要更多信息可以访问产品网站https://www.aliyun.com/product/gpdb
七 引用资料
【1】 http://click.aliyun.com/m/1000307639/
【2】 https://developer.aliyun.com/article/838806?groupCode=analyticdb4postgresql&share_source=wechat_qr
【3】 https://developer.aliyun.com/article/783182