本文转自雷锋网,如需转载请至雷锋网官网申请授权。
人类经常会遇到种类新颖的工具、食物或动物,尽管以前从未见过,但人类仍然可以确定这些是新物体。
与人类不同,目前最先进的检测和分割方法很难识别新型的物体,因为它们是以封闭世界的设定来设计的。它们所受的训练是定位已知种类(有标记)的物体,而把未知种类(无标记)的物体视为背景。这就导致模型不能够顺利定位新物体和学习一般物体的性质。
最近,来自波士顿大学、加州大学伯克利分校、MIT-IBM Watson AI Lab研究团队的一项研究,提出了一种检测和分割新型物体的简单方法。

原文链接:https://arxiv.org/pdf/2112.01698v1.pdf
为了应对这一挑战,研究团队创建一个数据集,对每张图片中的每一个物体进行详尽的标记。然而,要创建这样的数据集是非常昂贵的。如下图所示,事实上,许多用于物体检测和实例分割的公共数据集并没有完全标注图像中的所有物体。
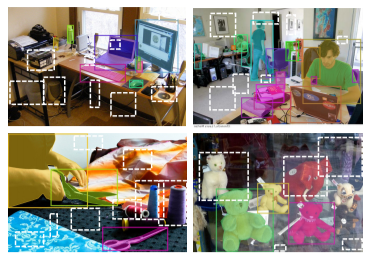
图1. 标准的物体检测器训练中存在的问题。该例来自COCO,有色框是注释框,而白色虚线框是潜在的背景区域。许多白色虚线区域实际上定位了物体,但在传统的物体检测器训练中被认为是背景,从而压制了新物体的目标属性。
1问题背景
未能学习到一般的目标属性会在许多应用场景中暴露出各种问题。例如具身人工智能,在机器人、自动驾驶场景中,需要在训练中定位未见过的物体;自动驾驶系统需要检测出车辆前方的新型物体以避免交通事故。
此外,零样本和小样本检测必须对训练期间未标记的物体进行定位。开放世界实例分割旨在定位和分割新的物体,但最先进的模型表现并不理想。
研究团队发现,导致目前最先进的模型表现不理想的原因在于训练pipeline,所有与标记的前景物体重叠不多的区域将被视为背景。如图1所示,虽然背景中有可见但却未被标记的物体,但模型的训练pipeline使其不能检测到这些物体,这也导致模型无法学习一般的目标属性。
为了解决该问题,Kim等人提出学习候选区域(region proposals )的定位质量 ,而不是将它们分为前景与背景。他们的方法是对接近真实标记的object proposals 进行采样,并学习估计相应的定位质量。虽然缓解了部分问题,但这种方法除了需要仔细设置正/负采样的重叠阈值外,还有可能将潜在的物体压制目标属性。
2方法
为了改进开放集的实例分割,研究团队提出了一个简单并且强大的学习框架,还有一种新的数据增强方法,称为 "Learning to Detect Every Thing"(LDET)。为了消除压制潜在物体目标属性这一问题,研究团队使用掩码标记复制前景物体并将其粘贴到背景图像上。而前景图像是由裁剪过的补丁调整合成而来的。通过保持较小的裁剪补丁,使得合成的图像不太可能包含任何隐藏物体。
然而,由于背景是合成图像创建而来的,这就使其看起来与真实图像有很大的不同,例如,背景可能仅由低频内容组成。因此,在这种图像上训练出来的检测器几乎表现都不是很好。
为了克服这一限制,研究团队将训练分成两部分:
1)用合成图像训练背景和前景区域分类和定位头(classification and localization heads);2)用真实图像学习掩码头(mask head)。
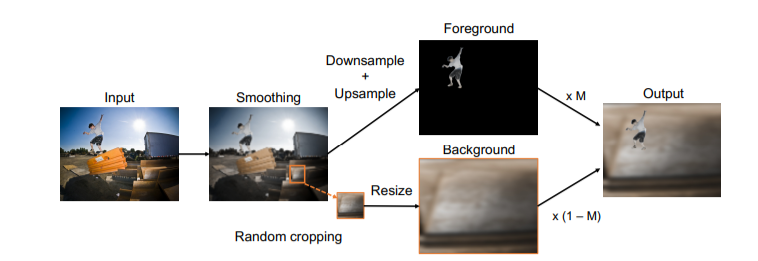
图2. 本文的增补策略是通过提高小区域的比例作为背景来创建没有潜在物体的图像。

图3. 原始输入(左)和合成图像(右)。用颜色标示了掩码区域,使用小区域作为背景,避免了背景中会隐藏物体。在某些情况下,背景补丁恰好可以定位前景物体(左栏第二行)。要注意的是,这种情况很少见, 可以看出补丁被明显放大了。
在训练分类头(classification head)时,由于潜在物体在合成图像时就已经被移除了,因此将潜在物体视为背景的几率变得很小。此外,掩码头是为在真实图像中分割实例而训练的,因此主干系统学习了一般表征,能够分离真实图像中的前景和背景区域。
也许这看起来只是一个小变化,但LDET在开放世界的实例分割和检测方面的表现非常显著。
在COCO上,在VOC类别上训练的LDET评估非VOC类别时,平均召回率提高了14.1点。令人惊讶的是,LDET在检测新物体方面有明显提高,而且不需要额外的标记,例如,在COCO中只对VOC类别(20类)进行训练的LDET在评估UVO上的平均召回率时,超过了对所有COCO类别(80类)训练的Mask R-CNN。如图2所示,LDET可以生成精确的object proposals,也可以覆盖场景中的许多物体。
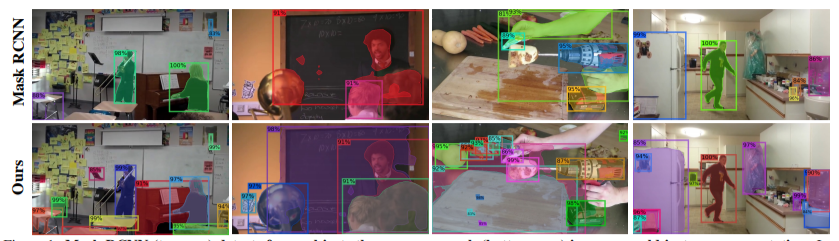
图4. 在开放世界中进行实例分割,Mask R-CNN(上图)比本文所研究的方法(下图)所检测到的物体要少。在此任务中,在不考虑训练种类的情况下,模型必须对图像中的所有物体进行定位并对其分割。图中的两个检测器都是在COCO上训练,并在UVO上测试的。在新的数据增补方法和训练方案的帮助下,本文的检测器准确地定位出许多在COCO中没有被标记的物体。
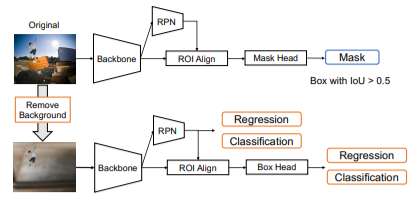
图5. 训练流程。给定一个原始输入图像和合成图像,根据在原始图像上计算的掩码损失和分类,以及在合成图像上的回归损失来训练检测器。
本文的贡献总结如下:
- 提出了一个简单的框架——LDET,该框架由用于开放世界实例分割的新数据增补和解耦训练组成。
- 证明了本文的数据增补和解耦训练对在开放世界实例分割中实现良好的性能至关重要。
- LDET在所有设置中都优于最先进的方法,包括COCO的跨类别设置和COCO-to-UVO和Cityscape-to-Mapillary的跨数据集设置。
3实验结果
研究团队在开放世界实例分割的跨类别和跨数据集上评估了LDET。跨类别设置是基于COCO数据集,将标记分为已知和未知两类,在已知类别上训练模型,并在未知类别上评估检测/分割性能。
由于模型可能会处在一个新的环境中并且遇到新的实例,所以跨数据集设置还评估了模型对新数据集的归纳延伸能力。为此,采用COCO或Cityscapes作为训练源,UVO和Mappilary Vista分别作为测试数据集。在此工作中,平均精度(AP)和平均召回率(AR)作为性能评估标准。评估是以不分等级的方式进行的,除非另有说明。AR和AP是按照COCO评估协议计算的,AP或AR最多有100个检测值。
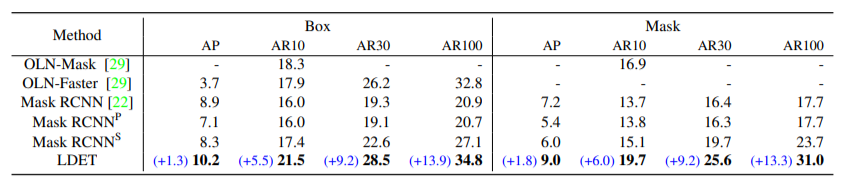
表1. COCO中VOC → Non-VOC泛化的结果。表中最后一行的蓝色部分是对Mask R-CNN的改进。LDET超过了所有的基线,并相较于Mask R-CNN有巨大改进。

图6. 在COCO数据集中,VOC to Non-VOC的可视化。上图:Mask R-CNN,下图:LDET。注意训练类别不包括长颈鹿、垃圾箱、笔、风筝和漂浮物。LDET比Mask R-CNN能更好地检测许多新的物体。
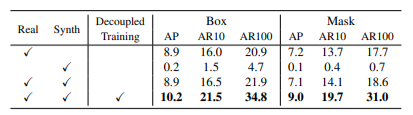
表2. VOC → Non-VOC的数据和训练方法的消融研究。最后一行是本文提出的框架。
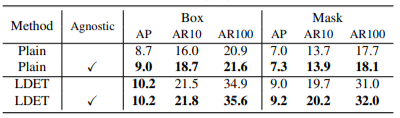
表3. class agnostic训练的消融研究。class agnostic训练对LDET和Mask R-CNN的性能有些许提高。
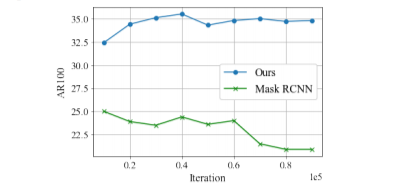
图7. 基线Mask R-CNN存在着对标记实例的过度拟合。因此,随着训练的进行,它检测新物体的性能会下降。相比之下,本文的方法基本上随着训练,性能都会提升。
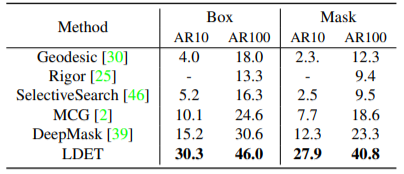
表4. 与COCO上测试的无监督方法和DeepMask的比较。需注意的是,DeepMask使用VGG作为主干。LDET和DeepMask是在VOC-COCO上训练的。
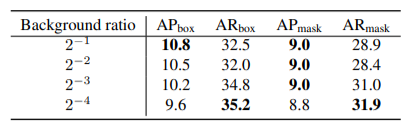
表5. 改变背景区域的大小。2-m表示用输入图像的2-m的宽度和高度裁剪背景区域。从较小的区域取样背景,往往会提高AR,降低AP。
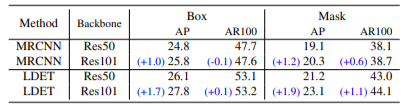
表6. ResNet50与ResNet101的对比。ResNet101倾向于比ResNet50表现得更好,这在LDET中更明显。
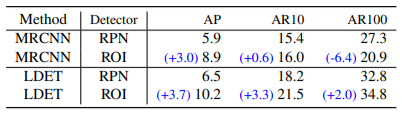
表7. region proposal network和region of interest head的比较。bounding boxes的AP和AR。

图8. COCO实验中的目标属性图(RPN score)的可视化。LDET捕获了各种类别的物体性,而Mask R-CNN则倾向于抑制许多物体。
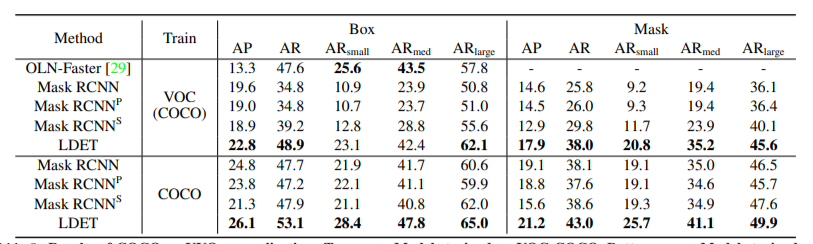
表8. COCO→UVO泛化的结果。上:在VOC-COCO上训练的模型,下:在COCO上训练的模型。与基线相比,LDET在所有情况下都表现出较高的AP和AR。

图9. 在COCO上训练的模型结果的可视化。上图:Mask R-CNN,下图:LDET。最左边的两张图片来自UVO,其他的来自COCO的验证图片。
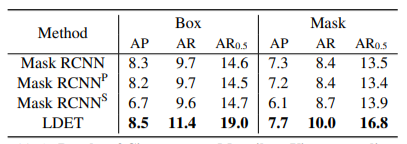
表9. Cityscapes → Mappilary Vista的归纳结果。LDET对自动驾驶数据集是有效的。AR0.5表示AR,IoU阈值=0.5。