索引,可以有效提高我们的数据库搜索效率,各种数据库优化八股文里都有相关的知识点可背,不过单纯的被条目其实很容易忘记。
所以松哥想通过几篇文章,和大家仔细聊一聊索引的正确使用姿势,结合一些具体的例子来帮助大家理解索引优化,这是一个小小的系列,可能会有几篇文章,今天先来第一篇。
1. 索引列独立
当我们将带有索引的列作为搜索的条件的时候,需要确保索引不在表达式中,索引中也不包含各种运算。
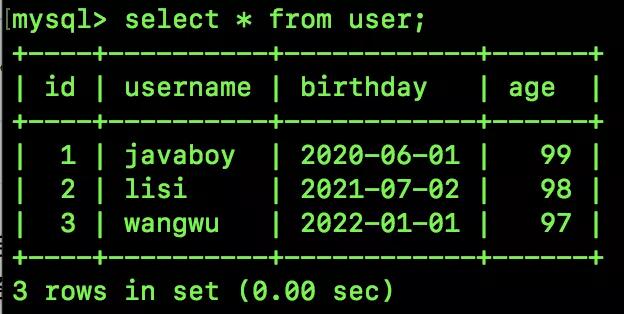
我举个简单例子,假设我有如下一张表:
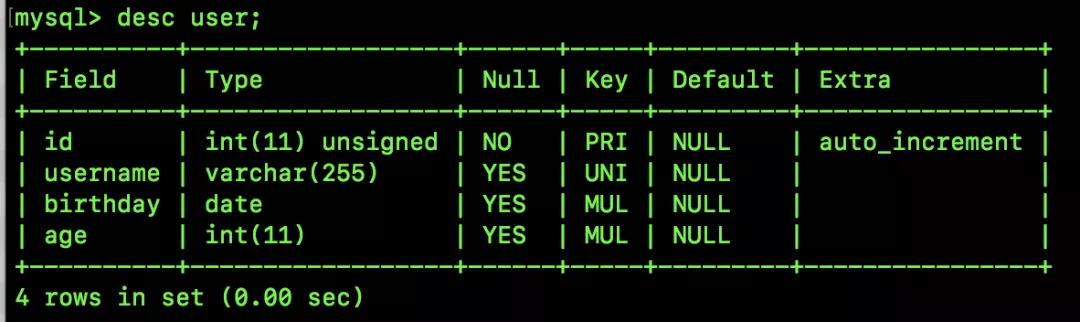
一个 user 表,里边就四个字段,每个字段上都建了索引,现在有三条测试数据:
我们来比较如下两个查询:
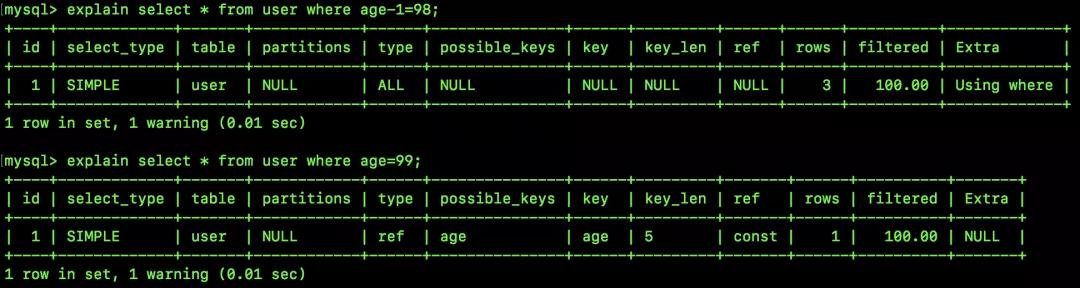
可以看到:
- 第一个 type 为 ALL 表示全表扫描(没用上索引);第二个 type 为 ref 表示通过索引查找数据,一般出现等值匹配的时候,type 会为 ref。
- 第二个的 key 指明了 MySQL 使用哪个索引来优化查询;rows 则显示了 MySQL 为了找到所需的值而要读取的行数.
- 第一个的 Extra 为 Using where 表示这个搜索需要在 server 层进行判断(过滤),即存储引擎层无法返回满足条件的数据(当然这里也不需要回表,因为压根都没有用啥索引)。
从上面的分析中可以看到,虽然 age-1=98 与 age=99 虽然在逻辑上并无二致,但是 MySQL 却无法自动解析第一个表达式,进而导致第一个无法使用索引。所以,我们不要在 where 条件中写表达式,不仅仅是上面这种表达式,一些使用了自带函数的表达式也不能使用,我们要尽量简化 where 条件。
不过上面这个例子太牵强了,一般大家不会犯这种错误,但是下面这个例子就不一定了,可能会有小伙伴在上面栽跟头:查询最近一年出生的用户(birthday 列也是索引):
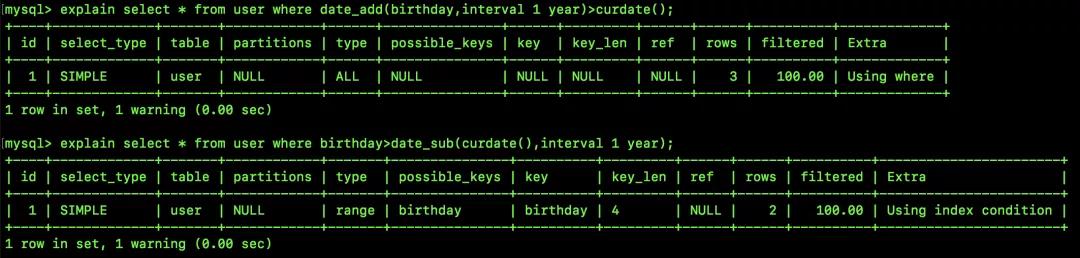
在这张图里,我给出了两种不同的查询思路:
对 birthday 做计算,如果 birthday 加上一年,得到的时间大于当前时间,那么说明该用户出生日期在最近一年一年之内。
对当前日期进行计算,如果当前日期减去一年得到的时间小于 birthday,说明 birthday 在一年之内。
根据上图 explain 的结果,很明显第一种方案没有用上索引,进行了全表扫描;而第二种方案则用上了索引,只读取了两行数据就可以了。究其原因,就是因为第一种方案在索引列上进行了函数运算,导致 MySQL 没法使用索引了。
2. 巧用覆盖索引
一般来说我们不建议在查询中直接使用 select *,使用 select * 有很多问题,其中一个问题就是无法利用索引覆盖扫描(覆盖索引)。
那这里需要大家首先明白什么是覆盖索引。
在什么是 MySQL 的“回表”?一文中,松哥和大家聊了,索引按照物理存储方式可以分为聚簇索引和非聚簇索引。
我们日常所说的主键索引,其实就是聚簇索引(Clustered Index);主键索引之外,其他的都称之为非主键索引,非主键索引也被称为二级索引(Secondary Index),或者叫作辅助索引。
对于主键索引和非主键索引,使用的数据结构都是 B+Tree,唯一的区别在于叶子结点中存储的内容不同:
主键索引的叶子结点存储的是一行完整的数据。
非主键索引的叶子结点存储的则是主键值以及索引列的值。
这是两者最大的区别。
所以,搜索时如果使用了非主键索引,那么一共会搜索两棵 B+Tree,第一次搜索 B+Tree 拿到主键值后再去搜索主键索引的 B+Tree,这个过程就是所谓的回表。但是,如果搜索的字段刚好就在二级索引的叶子结点上,那么是不是就不需要回表了?我们来验证下。
假设我有如下一张表:
CREATE TABLE `user2` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`address` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`gender` varchar(4) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `username` (`username`,`address`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
id 是主键,username 和 address 是复合索引。
这表有三条记录:
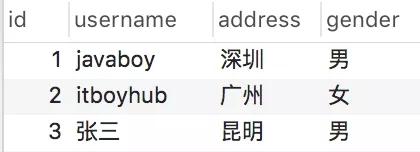
我们来做个简单测试,先来看如下 SQL:
explain select username,address from user2 where username='javaboy';
- 1.

这个查询 SQL,我们查询的字段是 username 和 address,由于这两个字段是复合索引,因此都保存在二级索引的 B+Tree 的叶子结点中,搜索到 username 后也就能拿到 address 的值了,因此不需要回表查询。大家注意最后 Extra 中的 Using index 就是这意思。
Using index 表示使用索引覆盖扫描来返回记录,直接从索引中过滤不需要的记录并返回命中结果,这是在 MySQL 服务器层完成的,但是无须再回表查询记录。
相同的道理,id 的值也存在于二级索引中,按理说也不需要回表,所以我稍微修改一下查询 SQL,加入 id,大家来看下:
explain select username,address,id from user2 where username='javaboy';
- 1.

可以看到跟我们想的一样。
那么我再加上 gender 呢?如果要查询的字段中包含 gender,由于 gender 并没有保存在二级索引的的叶子结点中,那么此时就需要回表查询了:
explain select gender from user2 where username='javaboy';
- 1.
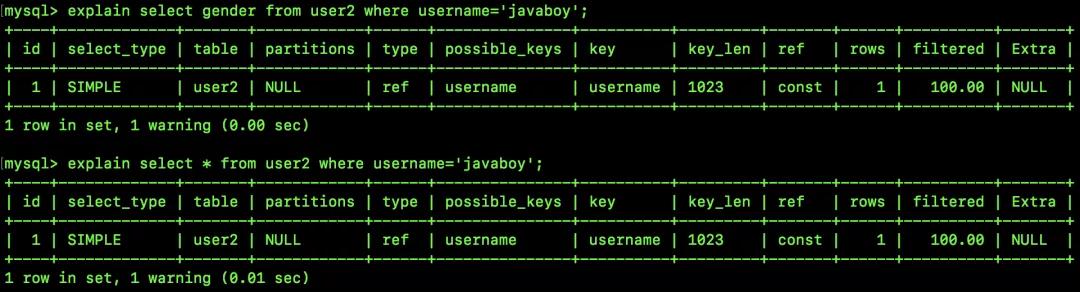
可以看到,此时 Extra 为空,同时用到了二级索引 username,那么此时就需要回表了。
这个就是覆盖索引,巧用覆盖索引,能避免回表,提高查询效率。那么此时就要尽量避免使用 select * 了(因为一般来说不太可能给所有字段都建立一个复合索引)。
好啦,不知道小伙伴看明白没有,下篇文章我们继续~
本文转载自微信公众号「江南一点雨」,可以通过以下二维码关注。转载本文请联系江南一点雨公众号。