













阿粉之前一直都是使用传统的SSM进行开发,也就我们所说的 Spring,SpringMVC,Mybatis,即使使用的SpringBoot,无非也就是这么集中,对于持久层框架的选择,也都是Mybaits,但是阿粉无意中发现,现在使用SpringDataJPA的公司也是非常的多的,所以,今天阿粉来讲一下这个SpringDataJPA.
SpringDataJPA和Mybaits
什么是JPA
jpq是面向对象的思想,一个对象就是一个表,强化的是你对这个表的控制。jpa继承的那么多表约束注解也证明了jpa对这个数据库对象控制很注重。
其实,在阿粉的眼中,JPA好像就是和Hibernate是一样的东西,区别并不大。
Spring Data JPA是Spring Data的子模块。使用Spring Data,使得基于“repositories”概念的JPA实现更简单和容易。Spring Data JPA的目标是大大简化数据访问层代码的编码。作为使用者,我们只需要编写自己的repository接口,接口中包含一些个性化的查询方法,Spring Data JPA将自动实现查询方法.
也就是说是什么呢?如果我们要写一个根据ID查对象的方法比如:
findUserById(String Id) 首先这个方法的名称,阿粉起名起的还是比较标准的,如果你在使用SpringDataJPA的话,再repository中直接使用这个方法名,就可以了,但是如果你使用了 Mybaits 的话,可能你需要在xml文件中,或者再方法上写SQL 就比如这个样子,
- select * from User where id = "xxxxx";
什么是Mybaits
mybatis则是面向sql,你的结果完全来源于sql,而对象这个东西只是用来接收sql带来的结果集。你的一切操作都是围绕sql,包括动态根据条件决定sql语句等。mybatis并不那么注重对象的概念。只要能接收到数据就好。
而且MyBatis对于面向对象的概念强调比较少,更适用于灵活的对数据进行增、删、改、查,所以在系统分析和设计过程中,要最大的发挥MyBatis的效用的话,一般使用步骤则与hibernate有所区别:
综合整个系统分析出系统需要存储的数据项目,并画出E-R关系图,设计表结构
根据上一步设计的表结构,创建数据库、表
编写MyBatis的SQL 映射文件、Pojos以及数据库操作对应的接口方法
而且现在有很多的Mybaits的插件,用于逆向生成 Mybaits 的文件,比如直接通过你建立的表生成 Dao文件和 dao.xml文件。
但是今天阿粉的重点可不是说这个 Mybatis,而是SpringDataJPA
接下来阿粉就来详细说说这个SpringDataJPA
什么是SpringDataJPA
官方文档先放上
总的来说JPA是ORM规范,Hibernate是JPA规范的具体实现,这样的好处是开发者可以面向JPA规范进行持久层的开发,而底层的实现则是可以切换的。Spring Data Jpa则是在JPA之上添加另一层抽象(Repository层的实现),极大地简化持久层开发及ORM框架切换的成本。
为什么这么多公司会选择 Mybaits ,而不选择使用 SpringDataJPA 呢?
因为Spring Data Jpa的开发难度要大于Mybatis。主要是由于Hibernate封装了完整的对象关系映射机制,以至于内部的实现比较复杂、庞大,学习周期较长。这对于现在的快捷式开发显然并不适合,但是因为某些公司最早的开发,所以现在很多公司仍然延续使用 Spring Data Jpa 来进行开发,接下来阿粉就来说说这个 Spring Data Jpa 是如何使用的。
如何使用 SpringDataJPA
我们直接使用SpringBoot 整合一下Spring Data Jpa 来进行操作。来展示如何使用 Spring Data Jpa。
创建一个 SpringBoot 的项目,
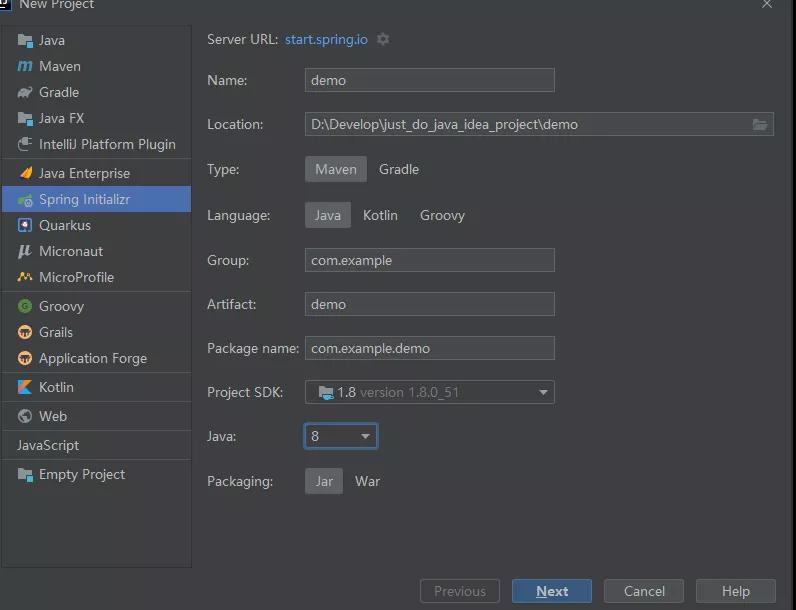
然后加入我们的依赖,或者你在创建的时候就进行选择,比如选择好我们接下来所需要的所有依赖就像这个样子。

这个时候我们就直接勾选上lombok,然后SpringWeb,还有我们的数据库驱动的 Jpa 的依赖。
创建完成,我们就能看到已经为我们添加好了我们所需要的依赖环境
- <dependencies>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-data-jpa</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- </dependency>
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <scope>runtime</scope>
- </dependency>
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- <optional>true</optional>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-test</artifactId>
- <scope>test</scope>
- </dependency>
- </dependencies>
如果不会选依赖的,各位,这肯定是一个非常好的方式。
接下来配置一下 yml 文件
- server:
- port: 8080
- servlet:
- context-path: /
- spring:
- datasource:
- url: jdbc:mysql://localhost:3306/jpa?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&useSSL=false
- username: root
- password: 123456
- jpa:
- database: MySQL
- database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
- show-sql: true
- hibernate:
- ddl-auto: update
看,最后有个hibernate,这就是之前阿粉说的,hibernate提供规范,
ddl-auto
这个参数也是有很多值的,不同的值代表着不同的内容。
- create:每次运行程序时,都会重新创建表,故而数据会丢失
- create-drop:每次运行程序时会先创建表结构,然后待程序结束时清空表
- upadte:每次运行程序,没有表时会创建表,如果对象发生改变会更新表结构,原有数据不会清空,只会更新(推荐使用)
- validate:运行程序会校验数据与数据库的字段类型是否相同,字段不同会报错
- none: 禁用DDL处理
然后启动一下,看看是否成功,如果出现数据库啥的不合适的,肯定是帐号和密码写错了,或者连接的数据库不对,看着改一下。有问题就改嘛,这才是好朋友。

看阿粉启动的还是相对来说很成功的,接下来我们就得安排一下这个 JPa 的使用方式了。
接下来我们创建好一组内容,Controller,Service,Dao,Entry,
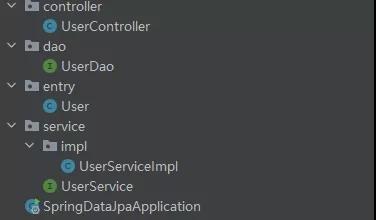
然后是我们实体类的内容和表
- @Data
- @Entity
- @Table(name = "user")
- public class User {
- @Id
- @GenericGenerator(name = "idGenerator", strategy = "uuid")
- @GeneratedValue(generator = "idGenerator")
- private String id;
- @Column(name = "user_name", unique = true, nullable = false, length = 64)
- private String userName;
- @Column(name = "user_password", unique = true, nullable = false, length = 64)
- private String userPassword;
- }
这时候主键阿粉使用的事uuid的策略,但是 Jpa 也是自带主键生成策略的。
- TABLE:使用一个特定的数据库表格来保存主键
- SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。这个值要与generator一起使用,generator 指定生成主键使用的生成器(可能是orcale中自己编写的序列)
- IDENTITY:主键由数据库自动生成(主要是支持自动增长的数据库,如mysql)
- AUTO:主键由程序控制,也是GenerationType的默认值
这时候 Dao 需要继承一下 Jpa 的接口了。
- public interface UserDao extends JpaRepository<User, String> {}
JpaRepository里面可是自带了不少方法的,
- List<T> findAll();
- List<T> findAll(Sort sort);
- List<T> findAllById(Iterable<ID> ids);
- <S extends T> List<S> saveAll(Iterable<S> entities);
- void flush();
- <S extends T> S saveAndFlush(S entity);
- <S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
- /** @deprecated */
- @Deprecated
- default void deleteInBatch(Iterable<T> entities) {
- this.deleteAllInBatch(entities);
- }
- void deleteAllInBatch(Iterable<T> entities);
- void deleteAllByIdInBatch(Iterable<ID> ids);
- void deleteAllInBatch();
- /** @deprecated */
- @Deprecated
- T getOne(ID id);
- T getById(ID id);
- <S extends T> List<S> findAll(Example<S> example);
- <S extends T> List<S> findAll(Example<S> example, Sort sort);
方法是真的不少,主要还是看你怎么使用,
我们来试试吧。
- @RestController
- @RequestMapping("/users")
- public class UserController {
- @Autowired
- private UserService userService;
- @RequestMapping(value = "/save")
- public User saveUser() {
- User user = new User();
- user.setUserName("zhangSan");
- user.setUserPassword("123456");
- return userService.saveUser(user);
- }
- }
Service 方法直接调用 UserDao 中的保存,也就是父类中的save方法。
- public interface UserService {
- User saveUser(User user);
- }
- @Service
- public class UserServiceImpl implements UserService {
- @Autowired
- private UserDao userDao;
- @Override
- public User saveUser(User user) {
- return userDao.save(user);
- }
- }
然后我们调用方法,再看看数据库

我们成功插入进去了一条数据,也就是说,这个方法是没什么毛病的呀,那是不是可以把所有的方法都挨着试一遍。
阿粉这里就不再一一的演示了,毕竟很简单的。
如果你觉得这些方法不能够满足你的使用,那么你就得继续看了,毕竟确实不能满足日常需求呀。就比如说多参数的,查询,这时候就有And出现,如果有需要,你就得专门的再去 官方文档中查看了
Jpa官方文档
如果你想使用一下SQL语句呢?
这时候,你就得写一个自定义的方法,然后再 Dao 你自定义方法上面加入 @Query注解然后在其中写你的 SQL 语句。
- @Query("select * from User where u.user_password = ?1")
- User getByPassword(String password);
?1这个实际上就是代表的参数,如果有多个参数,可以使使用?2
其实和 Mybaits 的 #{0} 看起来很类似。
Jpa的简单使用,你学会了么?说实在的,感觉这种方式,把代码和SQL都融合在了一起,感觉确实不是很好,至少从观看上面来说,体验就非常不好。




























