













还记得谷歌大脑团队去年 6 月份发布的 43 页论文《Scaling Vision with Sparse Mixture of Experts》吗?他们推出了史上最大规模的视觉模型 V-MoE,实现了接近 SOTA 的 Top-1 准确率。如今,谷歌大脑开源了训练和微调模型的全部代码。
在过去几十年里,深度学习的进步是由几个关键因素推动的:少量简单而灵活的机制、大型数据集、更专业的硬件配置,这些技术的进步使得神经网络在图像分类、机器翻译、蛋白质预测等任务中取得令人印象深刻的结果。
然而,大模型以及数据集的使用是以大量计算需求为代价的。最近的研究表明,增强模型的泛化能力以及稳健性离不开大模型的支持,因此,在训练大模型的同时协调好与训练资源的限制是非常重要的。一种可行的方法是利用条件计算,该方法不是为单个输入激活整个网络,而是根据不同的输入激活模型的不同部分。这一范式已经在谷歌提出的 pathway(一种全新的 AI 解决思路,它可以克服现有系统的许多缺点,同时又能强化其优势)愿景和最近的大型语言模型研究中得到了重视,但在计算机视觉中还没有得到很好的探索。
稀疏门控混合专家网络 (MoE) 在自然语言处理中展示了出色的可扩展性。然而,在计算机视觉中,几乎所有的高性能网络都是密集的,也就是说,每个输入都会转化为参数进行处理。
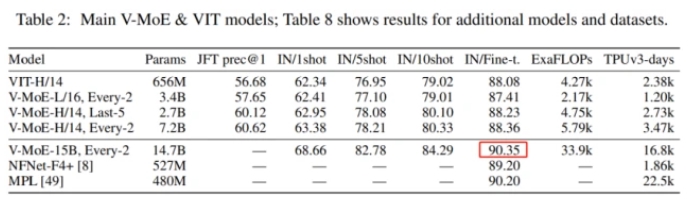
去年 6 月,来自谷歌大脑的研究者提出了 V-MoE(Vision MoE ),这是一种基于专家稀疏混合的新视觉架构。当应用于图像识别时,V-MoE 在推理时只需要一半的计算量,就能达到先进网络性能。此外,该研究还提出了对路由算法的扩展,该算法可以在整个 batch 中对每个输入的子集进行优先级排序,从而实现自适应图像计算。这允许 V-MoE 在测试时能够权衡性能和平滑计算。最后,该研究展示了 V-MoE 扩展视觉模型的潜力,并训练了一个在 ImageNet 上达到 90.35% 的 150 亿参数模型。

论文地址:https://arxiv.org/pdf/2106.05974.pdf
代码地址:https://github.com/google-research/vmoe
V-MoE
谷歌大脑在 ViT 的不同变体上构建 V-MoE:ViT-S(mall)、ViT-B(ase)、ViT-L(arge) 和 ViTH(uge),其超参数如下:
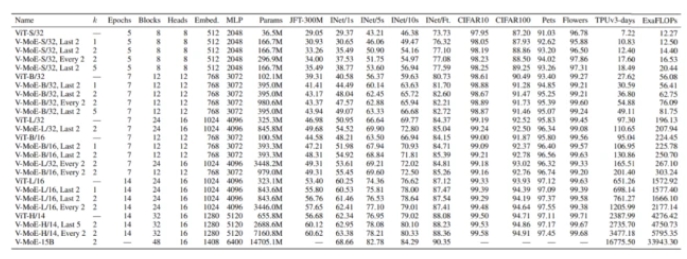
ViT 已被证明在迁移学习设置中具有良好的扩展性,在较少的预训练计算下,比 CNN 获得更高的准确率。ViT 将图像处理为一系列 patch,输入图像首先被分成大小相等的 patch,这些 patch 被线性投影到 Transformer 的隐藏层,在位置嵌入后,patch 嵌入(token)由 Transformer 进行处理,该 Transformer 主要由交替的自注意力和 MLP 层组成。MLP 有两个层和一个 GeLU 非线性。对于 Vision MoE,该研究用 MoE 层替换其中的一个子集,其中每个专家都是一个 MLP,如下图所示:
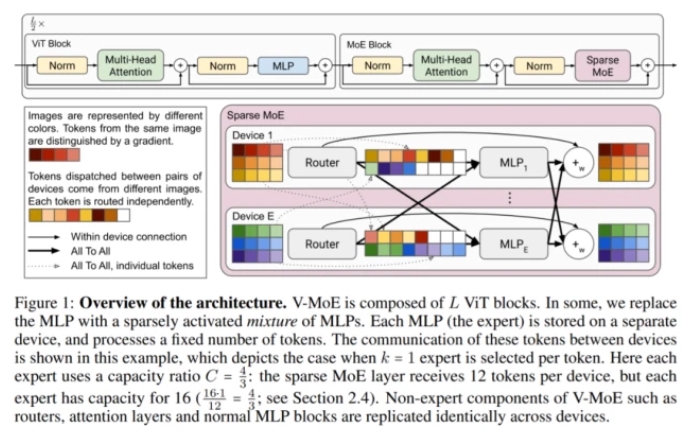
为了大规模扩展视觉模型,该研究将 ViT 架构中的一些密集前馈层 (FFN) 替换为独立 FFN 的稀疏混合(称之为专家)。可学习的路由层为每个独立的 token 选择对应的专家。也就是说,来自同一图像的不同 token 可能会被路由到不同的专家。在总共 E 位专家(E 通常为 32)中,每个 token 最多只能路由到 K(通常为 1 或 2)位专家。这允许扩展模型的大小,同时保持每个 token 计算的恒定。下图更详细地显示了 V-MoE 编码器块的结构。
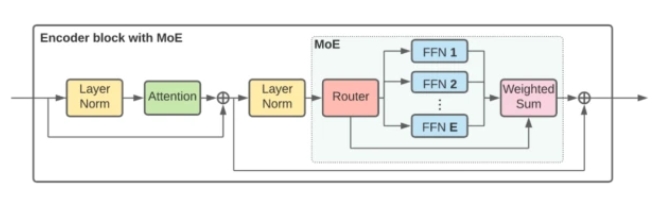
V-MoE Transformer 编码器块
实验结果
谷歌大脑首先在大型图像数据集 JFT-300M 上对模型进行一次预训练。
下图左展示了模型在所有大小(从 small s/32 到 huge H/14)时的预训练结果。然后,使用一个新的 head(一个模型中的最后一层)将模型迁移至新的下游任务(如 ImageNet)。他们探索了两种迁移设置:在所有可用的新任务示例上微调整个模型或者冻结预训练网络并使用少量示例仅对新 head 调整(即所谓的小样本迁移)。
下图右总结了模型迁移至 ImageNet 的效果,其中每个图像类别仅在 5 张图像上训练(叫做 5-shot transfer)。

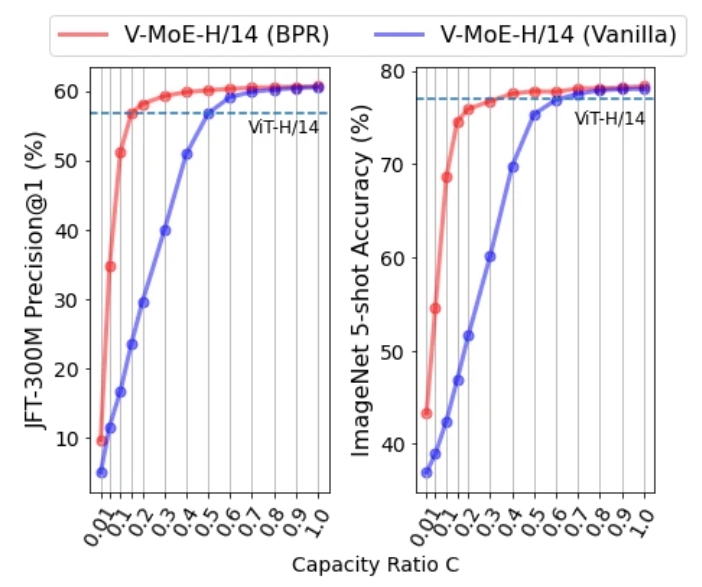
左为 JFT-300M 数据集上的 Precision@1 曲线图;右为 ImageNet 5-shot 的准确率曲线图。
对于这两种情况,谷歌大脑发现,在给定训练计算量时,稀疏模型显著优于密集模型或者更快地实现相似性能。为了探索视觉模型的极限,他们在 JFT-300M 扩展数据集上训练了一个具有 150 亿参数、24 个 MoE 层(出自 48 个块)的模型。这个迄今为止最大的视觉模型在 ImageNet 上实现了 90.35 的 Top-1 准确率。
优先路由
在实践中,由于硬件限制,使用动态大小的缓冲区(buffer)效率不高,因此模型通常为每个专家使用预定义的缓冲区容量。一旦专家变「满」,超出此容量的分配 token 将被丢弃并不会被处理。因此,更高的容量会产生更高的准确性,但它们的计算成本也更高。
谷歌大脑利用这种实现约束来使 V-MoE 在推理时更快。通过将总组合缓冲区容量降低到要处理的 token 数量以下,网络被迫跳过处理专家层中的一些 token。该模型不是以某种任意方式选择要跳过的 token(就像以前的工作那样),而是学习根据重要性分数对它们进行排序。这样可以保持高质量的预测,同时节省大量计算。他们将这种方法称为批量优先级路由(Batch Priority Routing, BPR),动态示意图如下所示:

在高容量下,Vanilla 和优先路由都可以很好地处理所有 patch。但是,当减小缓冲区大小以节省计算时,Vanilla 路由选择处理任意 patch,通常导致预测不佳;BPR 智能地优先选择处理重要 patch,使得以更低的计算成本获得更佳的预测。
事实证明,适当地删除 token 对于提供高质量和更有效的推理预测至关重要。当专家容量减少时,Vanilla 路由机制的性能会迅速下降。相反,BPR 对低容量更为稳健。
总体而言,谷歌大脑观察发现,V-MoE 在推理时非常灵活:例如,可以减少每个 token 选择的专家数量以节省时间和计算,而无需对模型权重进行任何进一步的训练。
探索 V-MoE
由于关于稀疏网络的内部工作原理还有很多待发现,谷歌大脑还探索了 V-MoE 的路由模式。一种假设是,路由器会根据某些语义背景(如「汽车」专家、「动物」专家等)学会区分并分配 token 给专家。
为了测试这一点,他们在下面展示了两个不同 MoE 层的图,一个非常早期(very early-on),另一个更靠近 head。x 轴对应 32 个专家中的每一个,y 轴显示图像类别的 ID(从 1 到 1000)。图中每个条目都显示了为与特定图像类对应的 token 选择专家的频率,颜色越深表示频率越高。
结果显示,虽然在早期层几乎没有相关性,但在网络后期,每个专家只接收和处理来自少数几个类别的 token。因此,可以得出结论,patch 的一些语义聚类出现在网络的更深层。
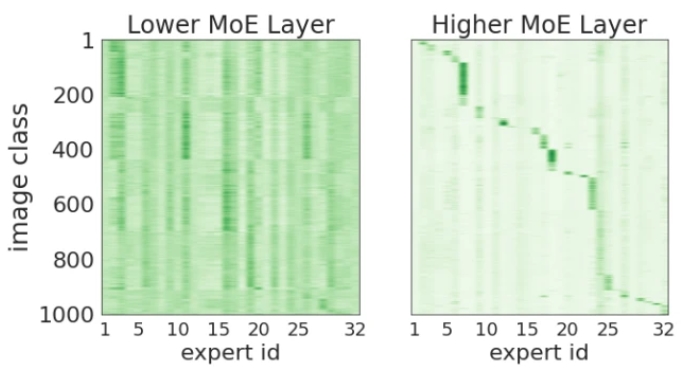
更高的路由决策与图像类别相关。
谷歌大脑相信这只是计算机视觉大规模条件计算的开始。异构专家架构和条件可变长度路由也是有潜力的研究方向。稀疏模型尤其有益于数据丰富的领域,例如大规模视频建模。他们希望开源的代码和模型能够吸引更多研究人员关注该领域。



























