前端程序员,每天接触的都是浏览器。作为一个合格的前端工程师,浏览器相关的工作原理是我们对性能优化的基石,今天就来考考自己对浏览器了解有多少?
一、从输入 URL 到页面呈现发生了什么?
在浏览器中输入一个网址,如:https://www.baidu.com 。从输入地址到我们看到百度首页,这一过程到底发生了什么?
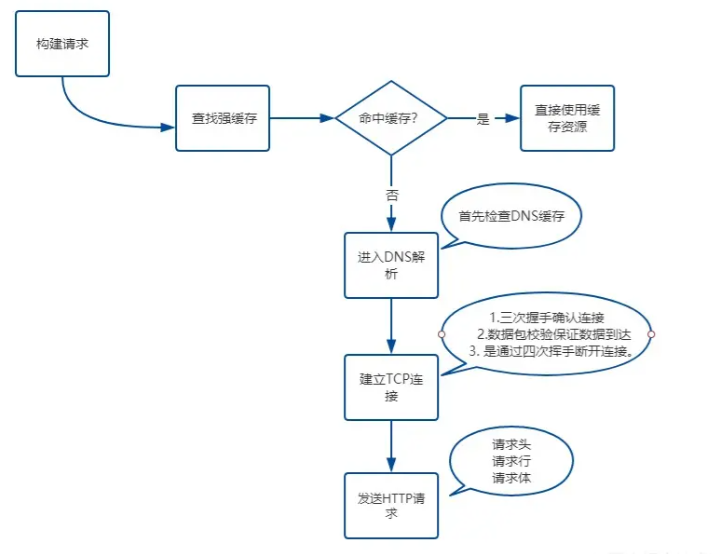
1.1、构建网络请求
1.2、查找缓存
检查如果有缓存,则直接使用缓存,如果没有缓存,则会向服务器发送网络请求。
1.3、DNS解析
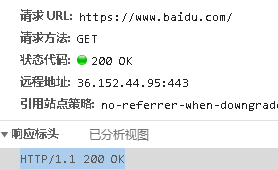
我们访问网站的时候,输入的是域名,比如上边截图内
域名:https://www.baidu.com
IP地址:36.152.44.95:443
真正的数据包是通过 IP 地址传过来的,域名和 IP 是 一 一 映射关系。我们根据域名获取到具体的 IP 这个过程就叫做 DNS 解析。
IP 地址后的数字指定的端口号,如果没有,默认是 80 。
1.4、建立 TCP 连接
服务器要是想把数据包传给浏览器之前,首先要建立连接。建立 TCP 连接,就是保证服务器与浏览器之间能够进行安全连接通信,数据传输完毕之后再断开连接。
TCP (Transmission Control Protocol),传输控制协议,是一种面向连接的,可靠的,基于字节流的传输层通信协议。
同一个域名下,最多能够建立 6 个 TCP 连接,超过 6 个的话,剩余的会排队等待。TCP 连接分为三个阶段:
通过三次握手建立浏览器与服务器之间的连接。
进行数据传输,服务器向浏览器发送数据包。
断开连接的阶段,数据传输完毕之后,通过四次挥手来断开连接。
1.5、发送 HTTP 请求
TCP 建立连接完毕后,浏览器和服务器可以开始通信了,即开始发送 HTTP 请求。
http 请求,前端程序员就很熟悉喽!有请求和响应。
网络请求流程图:
二、页面是如何渲染的?
第一个问题讲的浏览内输入 url 之后做了做了些啥,最后到发送网络请求。服务器根据 url 提供的地址查找文件,然后加载 html、css、js、img等资源文件。接收到文件之后浏览器是如何渲染的呢?
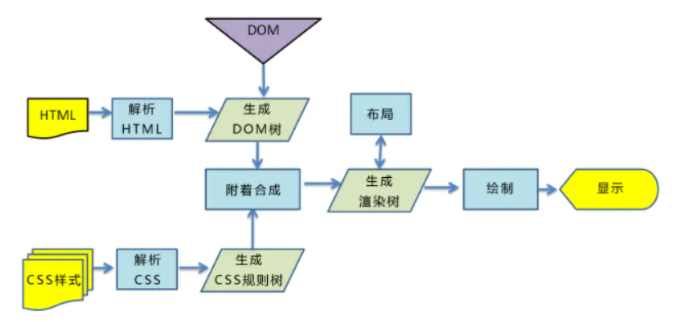
浏览器渲染的过程为:
- 浏览器将获取的 html 文档解析成 DOM 树。
- 处理 CSS 标记,构成层叠样式表模型CSSOM。
- 将 DOM 和 CSSOM 合并,创建渲染树(rendering tree),代表一系列将被渲染的对象。
- 渲染树的每个元素包含的内容都是计算过的,它被称为布局 layout 。浏览器使用流式布局的方式,只需一次绘制操作布局所有的元素。
- 将渲染树的各个节点绘制到屏幕上,这一步被称之为 painting。
图示:
三、浏览器缓存是怎么回事?
3.1、强缓存
检查强缓存的时候,不会发送 http 请求。
如何来检查呢?通过相应的字段来进行检查的,在 hTTP/1.0 中使用的是 Expires /,在 HTTP/1.1 使用的是 Cache-Control 。
Expires
Expires 即过期时间,存在于服务端返回的响应头,告诉浏览器在过期时间之前可以直接从缓存内获取数据,无需再次发送网络请求。
- expires: Wed, 29 Dec 2021 07:19:28 GMT
- 我是在2021-12-22 12:30左右 请求的 https://www.baidu.com/ ,
- 返回的 expires 内容如上。
- 表示资源在 2012-12-29 07:12:28 过期,在这之前不会向服务器发送请求
这个方式你看有毛病吗?潜藏了一个大坑,如果电脑的本地时间与服务器时间不一致时,那么服务器返回的这个过期时间可能就是不准确的,因此这种方式在 HTTP 1.1 中被抛弃了。
Cache-Control
在 HTTP1.1 中,采用了一个非常关键的字段:Cache-Control 。这个字段也存在于响应头中。如:
- cache-control: max-age=2592000
代表的是这个响应返回后,在 (2592/3600=720小时)直接可以直接使用缓存。
它和 Expires 本质的不同在于它并没有采用具体的时间点,而是采用的时长来控制强缓存。如果 Expires 和 Cache-Control 同时存在的时候,Cache-Control 会优先考虑。
强缓存有没有可能失效呢?如果资源缓存时间超时,也就是强缓存失效了,接下来该怎么办呢?此时就会进入到第二级屏障 -- 协商缓存。
3.2、协商缓存
强缓存失效之后,浏览器在请求头中携带相应的 缓存tag 向服务器发送请求,服务器根据这个 缓存tag 决定到底是否使用缓存,这就是协商缓存
缓存 tag 有两种:ETag 和 Last-Modified 。
ETag 是服务器根据当前文件内容生成的唯一标识,如果内容发生更新,唯一标识也会更新。浏览器接收到的 ETag 会作为 if-None-Match 字段的内容,并放到请求头中,发送给服务器之后,服务器会与服务器上的 值进行对比,如果两者一样,浏览器直接返回304,使用缓存。不一样时发送 http 请求。
Last-Modified ,最后修改时间。浏览器第一次发送网络请求后,服务器会在响应头上加上该字段。浏览器再发请求时,会把该值作为 last-Modified-Since 的值,放入请求头,然后服务器会与服务器上的最后修改时间进行对比,如果两者一样,浏览器直接返回304,使用缓存。不一样时发送 http 请求。
两者对比:
精准度上 ETag 更好一点。因为 ETag 能够更准确的判断资源是否有更新,保证拉取到的都是最新内容。
性能上 Last-Modified 刚好一点,只需要记录一个时间点就好了。
如果两者都存在的话,优先考虑 ETag。
3.3、缓存位置
前边讲述,浏览器请求地址时,服务器返回 304 表示使用浏览器缓存,这些资源究竟缓存到哪了呢?
缓存位置一共有四种,按照优先级由高到低排列分别为:
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
四、浏览器的本地存储有哪些?
所谓本地存储,就是把一些信息,存储到客户端本地,存储的信息不会因为页面的跳转或关闭而消失。浏览器本地存储主要分为:cookie、webStorage 和 indexDB。
4.1、cookie
cookie 主要为了辨别用户身份。弥补 http 在状态管理上的不足。
http 是一个无状态协议,浏览器向服务器发送请求之后,服务器返回响应,下次再请求的时候,服务器已经不认识浏览器了,如果浏览器下次再发送请求时,能够把 cookie 带上,服务器进行解析,便能够辨别浏览器的身份。
cookie 就是用来存储状态的,它的特点分别有:
- 能够兼容所有浏览器,它和服务器之间有一定的关联。
- 存储大小限制:一般浏览器规定同源下最多只能存储 4KB 大小
- cookie 存在过期时间,过期时间可以自己设置。
- cookie 不稳定,清除浏览器缓存或三方清理垃圾时容易把 cookie 移除掉。
- 用户可以根据句自己的需求开启 cookie 缓存,如果开启无痕浏览器或隐身模式时,将关闭 cookie。
4.2、webStorage
webStorag 可分为 localStorage 和 sessionStorage ,是本地持久化存储,本地持久化存储用来保存一些不需要发送给服务器的信息,用来补充 cookie 存储方式不足。
localStorage 特点:
- 不兼容低版本浏览器 IE6-8 。
- 生命周期是永久的,除非用户主动清除,否则一直存在。
- 存储的数据大小一般为 5M,各浏览器之间有差异。
- 不受浏览器无痕模式或隐身模式影响。
- 严格的本地存储,与服务器之间没有关系。
sessionStorage 特点:
- 不兼容低版本浏览器 IE6-8 。
- 仅在当前会话下有效,关闭当前页面或关闭浏览器,就会被清除。
- 存储的数据大小一般为 5M,各浏览器之间有差异。
- 严格的本地存储,与服务器之间没有关系。
localStorage 和 sessionStorage 有一个本质区别,localStorage 生命周期是永久化的,而 sessionStorage 只存在于当前会话。
4.3、indexedDB
indexedDB 是 html5 提供的一种本地存储,一般保存大量用户数据并要求数据之间有搜索需要的场景,当网络断开,做一些离线应用,数据格式为 json 。本质上是一个 非关系型数据库。它的容量是没有上限的。
特点:
- 存储空间较大,默认250M 。
- 键值对操作,可以进行数据库读取和遍历,也可以用索引进行高效的检索。
- 受同源策略限制,无法跨域访问数据库。
总结:浏览器本地存储每种方式都有各自的特点,cookie 比较小适合存储与服务器之间通信的较小状态信息,webStorage 存储不参与服务器通信的数据,indexedDB 存储大型的非关系型数据库。
五、什么是 XSS 攻击?
XSS ( Cross Site Scripting ) 跨站脚本,为了与 CSS 区分,故意叫做 XSS 。主要是由于网站程序员对用户输入过滤不足,导致攻击者利用输入可以在页面进行显示或盗取用户信息,利用身份信息进行恶意操作的一种攻击方式。
讲直白点,就是恶意攻击者通过在输入框处添加恶意 script 代码,用户浏览网页的时候执行 script 代码,从而达到恶意攻击用户的目的。
5.1、XSS 攻击类型
XSS 攻击实现有三种方式:存储型、反射型 和 文档写。
存储型
表面意思理解,就是将恶意脚本存储起来。将脚本存储到服务器的数据库,然后在客户端执行这些恶意脚本,从而达到攻击效果。
比如,在评论区提交一段 script 代码,如果前后端不做任何转义工作,直接把脚本存储到数据库,页面加载数据的时候,渲染时发现它是 js 代码,就会直接执行,相当于执行了一段未知逻辑的 js 。
反射型
反射型 XSS 指的是恶意脚本作为网络请求的一部分。
浏览器请求接口如:
- http://www.xxx.com?q=<script>alert("恶意脚本")</script>
会将参数 q= 传递给服务器,服务器将内容返回给浏览器,浏览器渲染时,发现它是 js 脚本,就会直接执行。所以页面一加载的时候,就会有一个弹框。
之所以称为反射型,是因为它是从浏览器通过网络请求经过服务器,然后又返回浏览器,执行解析。
文档型
文档型的 XSS 攻击不会经过服务器,作为中间人的角色,在数据传输过程中劫持到网络数据包,然后修改里面的 html 文档。
常见的 wifi 劫持 或者本地恶意软件。
XSS 攻击危害包括:
- 盗取用户各类账号,如机器登录账号,用户网银,各类管理员账号。
- 控制企业数据,包括读取,篡改、添加、删除敏感数据。
- 盗窃具有商业价值的资料。
- 控制受害者机器向其他网站发起攻击。
- 劫持别人的广告,点击广告之后跳转到自己的广告页
5.2、XSS防范措施
措施1:XSS 攻击原理就是恶意执行 js 脚本,我们要防范它,只需要在用户输入的地方,对输入的内容进行转码或过滤。
- 如:
- <script>
- alert('恶意脚本')
- </script>
- //转码后
- <script>alert('恶意脚本')</script>
这样在代码 html 中解析时,不会当做 js 脚本执行。
措施2:CSP ,浏览器中的内容安全策略,就是决策浏览器加载哪些资源。具体的有:
- 同源策略,限制其他域下的资源加载。
- 禁止在当前页面向其他域下提交数据。
- 提供上报机制,能够及时发现 XSS 攻击。
措施3:HttpOnly,如果 cookie 设置了 httponly,那么通过 js 脚本无法获取到 cookie 信息。这样能够有效防止 XSS 攻击,窃取用户信息。
六、http 和 https
浏览器访问 http 的网站的时候,域名前面会提示“不安全”,访问 https//xxx.com 的时候浏览器提示 “安全”,这是为什么呢?
http 协议,超文本传输协议,被用于在服务器和浏览器之间传递信息,http协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者直接截取浏览器和服务器之间传输报文,就可以直接读懂其中的信息。
为了解决 http 协议的缺陷,使用 https 安全套接字层超文本传输协议,为了保证数据的安全性,在 http 协议的基础上,新增了 SSL 协议,SSL依靠证书来验证服务器的身份器,并未浏览器和服务器之间的通信加密。
https 并不是一个新协议,而是一个加强版的 http 。简单讲 https 协议由 SSL+http 协议构建成可进行加密传输、身份认证的网络协议,要比 http 协议安全。
https 和 http 的区别:
- https 协议需要申请安全证书,一般免费较少,需要费用,而 http 不需要。
- https 具有 SSL 加密传输,更加安全,而 http 是明文传输,不安全。
- https 和 http 使用的不同连接方式,用的默认端口不一样,http 是 80,https是443。
- http 的连接简单,没有状态,而 https 是需要通过 SSL 校验身份信息的,相对更加安全。
https 工作原理图:
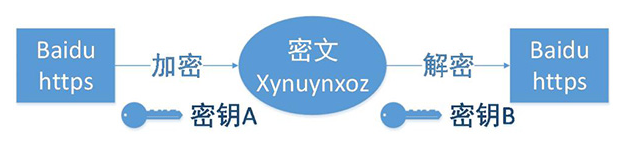
加解密过程
接着我们来谈谈浏览器和服务器进行协商加解密的过程。
首先,浏览器会给服务器发送一个随机数client_random和一个加密的方法列表。
服务器接收后给浏览器返回另一个随机数server_random和加密方法。
现在,两者拥有三样相同的凭证: client_random、server_random和加密方法。
接着用这个加密方法将两个随机数混合起来生成密钥,这个密钥就是浏览器和服务端通信的暗号。