本文转载自微信公众号「编程界」,作者五月君 。转载本文请联系编程界公众号。
几个话题
本文会根据以下几个话题进行讨论与讲解,文中的目录不完全和这几个话题一致,但当你阅读完本文后,相信这些答案应该也有了,都在文中。
- 为什么要使用游标、什么时候使用?
- 关注服务器内存,游标什么时候关闭?
- 需要注意的游标超时与容错处理
- 为什么不要随意调整 batchSize 数量?
- 使用时需注意 Mongoose 与原生 Node.js MongoDB 驱动程序的不同之处
- 解答群友问题时发现的一个关于游标的 Bug
- 扩展 - 为什么可以使用 for await of 遍历游标对象?
为什么要使用游标?
这样的写法 collection.find().toArray(),大家在学习 MongoDB 时应该见的也不少,它的原理是客户端驱动程序会自动把返回的所有数据一次性加载到应用程序内存中,理解起来相对简单些,如果数据量小是没问题的,在一些数据处理的场景中,具体有多少数据也许是未知的,有可能返回大量的数据,如果全部 hold 在内存,在服务端内存寸土寸金的地方,白白消耗服务内存不说,内存占用过高还可能造成服务 OOM。
MongoDB 里面的游标,有点类似于在 Node.js 里使用 Stream 处理文件数据,相比把整个文件读入内存在处理这种模式,Stream 带来的收益是很大的。

很形象的一个图,来源:https://www.cnblogs.com/vajoy/p/6349817.html[1]
游标基本工作原理
当我们使用 collection.find() 或 collection.aggregate() 返回的是一个指向该集合的指针,也称为游标(cursor),是不能直接访问数据的,只有当循环迭代这个游标时才会真正的从数据库集合读取数据。
在 Node.js 中使用很简单,只要支持 for await of 语法,即可遍历游标返回的数据集,和正常使用 for of 遍历数组很相似,区别是 for await of 遍历的数据源是异步的。当循环迭代开始时驱动程序会使用 getMore() 命令批量从数据库集合中获取一批数据先缓存起来,例如 Node.js MongoDB 驱动程序每次默认批量获取 1000 条(注意,第一次 getMore() 时实际请求是 101 条),取决于 batchSize[2] 参数设置,待这批数据处理完成之后,在向 MongoDB Server 执行 getMore() 继续请求直到游标耗尽。
以下为 Node.js 中的两种使用示例,个人比较推荐 for await of 这种写法。方法二 while 循环这种写法在一个 MongoDB Node.js 驱动程序版本中存在一个 Bug 下文会介绍。
const userCursor = await collection.find();
// 如果没有返回数据,需要做一些特殊处理的,可以使用 userCursor.count() 或 userCursor.hasNext()
if (!await userCursor.count()) {
// TODO: 提前结束,做一些其它操作
return;
}
// 方法一:
for await (const user of userCursor) {
}
// 方法二:
while (await userCursor.hasNext()) {
const doc = userCursor.next();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
例如,数据库集合有 10000 条数据,每次批量获取 1000 条,I/O 消耗应该也为 10 次。终端链接至 MongoDB Server 设置 db.setProfilingLevel(0, { slowms: 0 })记录所有的操作日志,之后在打开 MongoDB Server 控制台日志,执行应用程序之后会看到如下日志信息,每次 getMore 都指向了同一个游标 ID getMore: 5098682199385946244。
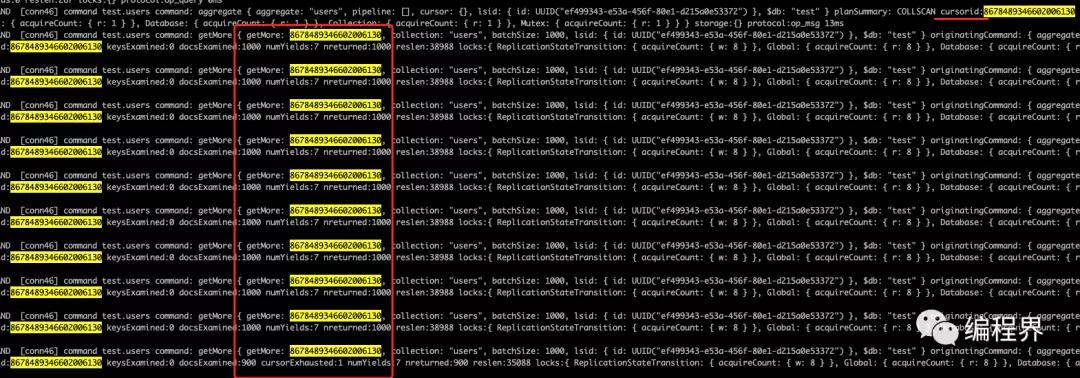
游标读取结果.png
如果需要修改 batchSize 结果的,通过 options 指定 batchSize 属性或调用 batchSize 方法都可以。
collection.find().batchSize(1100)
// 或以下方法
collection.find({}, {
batchSize: 1100
})
- 1.
- 2.
- 3.
- 4.
- 5.
切记不要将 batchSize 设置为 1,例如,10000 条数据每获取一条数据,客户端都将连接服务器读取,这将会产生 10000 次网络 IO,下图使用 mongostat 监控,展示了每秒查询游标时的 getMore 次数。
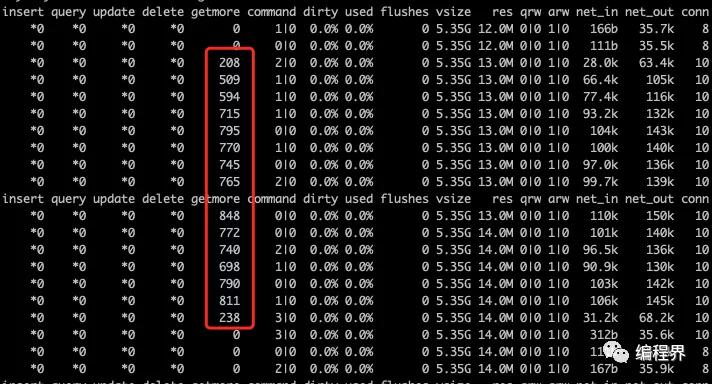
游标超时
如果一个游标在一定时间内无人访问,超时之后会被回收,防止产生内存泄漏,启动时可通过 mongod --setParameter cursorTimeoutMillis=300000 参数设置,默认超时为 10 分钟,参见文档 cursorTimeoutMillis#Default: 600000 (10 minutes)[3]。
例如,总共查询 10000 条数据,第一次 getmore() 默认批量获取 1000 条数据,如果在默认的 10 分钟内没有处理完成这 1000 条数据,游标会被关闭,待下次执行 getmore() 就会报错 cursor id 4011961159809892672 not found,一般称之为游标超时。
如有遇到游标超时,可通过调整 cursorTimeoutMillis 参数或减少 batchSize 数量选择适合于自己的程序配置,通常默认配置是不需要调整的。例如,在遍历游标数据时调了一个外部接口,由于接口超时导致的游标超时这种外部业务原因的,应先去优化业务本身,再考虑调整配置。
为了解决游标超时,你可能还见到过 cursor.addCursorFlag('noCursorTimeout', true) 这样的配置,这会禁用掉游标的超时限制,只有等到游标耗尽或手动关闭 cursor.close() 游标才可能被释放,禁用超时时间这种做法,很不推荐使用,每个游标都存在额外的内存占用消耗,如果因为疏忽忘记手动关闭游标导致的 MongoDB Server 内存泄漏就得不偿失了。
游标状态
登陆 MongoDB 客户端,执行 db.serverStatus().metrics.cursor 命令,查看当前游标使用状态。如果真的出现游标导致的 MongoDB 服务器内存泄漏,以下几个数据指标,做为运维人员在排查问题时,会有帮助。
- timedOut:指 MongoDB Server 进程启动到现在所有的游标超时数量,此指标反映了应用程序因为处理耗时任务 或 游标打开后因为报错没有显示关闭游标 这两种情况导致的游标超时数量。
- open.noTimeout:为了防止游标超时,MongoDB 提供了一个配置 DBQuery.Option.noTimeout[4] 设置永不超时,但如果处理完毕忘记显示关闭游标,会导致游标常驻内存,数量越大内存泄漏的风险也越大,建议是尽量不要设置 noTimeout。
- open.pinned:“固定” 打开游标的数量。
- open.total:MongoDB Server 当前为客户端打开的游标数量,当有游标耗尽,total 的数量也会不断的减少。
{
"timedOut" : NumberLong(4),
"open" : {
"noTimeout" : NumberLong(0),
"pinned" : NumberLong(0),
"total" : NumberLong(0)
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
游标与异步迭代器
JavaScript 在 ES6 语法提供了一个功能叫迭代器,定义了一套统一的接口,只要实现了该接口的数据类型,都可使用 for of 关键词遍历,例如数组、Map、Set 类型等,这些类型上有一个方法 Symbol.iterator 返回的就是一个迭代器对象,迭代器对象的 next() 方法返回值包含了 vlaue、done 两个属性,如果 done 为 true 表示数据已遍历完成,但 Symbol.iterator 只支持同步的数据源。
而我们从数据库集合获取数据涉及到网络 I/O,这是一个异步的操作,Symbol.iterator 就无法支持了,在ECMAScript 2018 标准中提供了一个新的属性 Symbol.asyncIterator,这是一个异步迭代器,与 Symbol.iterator 不同的是 Symbol.asyncIterator 的 next() 方法返回的是一个包含 { value, done } 的 Promise 对象,如果一个对象设置了该属性,它就是异步可迭代对象,相应的我们可使用 for await...of 循环遍历数据。
下面看下 MonogoDB Node.js 驱动程序在 v4.2.2 版本中的实现,同样也提供了 Symbol.asyncIterator 接口,这也就是为什么我们可以使用 for await...of 循环遍历。
// mongodb/lib/cursor/abstract_cursor.js
class AbstractCursor extends mongo_types_1.TypedEventEmitter {
[Symbol.asyncIterator]( "Symbol.asyncIterator") {
return {
next: () => this.next().then(value => value != null ? { value, done: false }: { value: undefined, done: true })
};
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
容错处理
在遍历游标的过程中,for 循环体内如果出现一些错误导致循环提前终止,这个时候游标并不会被立刻销毁,可以选择手动关闭游标或等待超过默认的游标超时时间后,游标也会被销毁。
如果设置了 noCursorTimeout 属性为永不超时,这个时候就一定记得要关闭游标,因此在上面也建议尽量不要做这个设置。
const userCursor = await collection.find();
try {
for await (const user of userCursor) {
// 可能抛出错误 throw new Error('124')
}
} catch (e) {
// 处理错误
} finally {
userCursor.close();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
Mongoose 需要注意的地方
使用 mongoose 和原生支持的 mongodb 模块还是有很多差异的,mongoose 的 find() 方法默认不会返回游标对象,需要在 find 后显示调用 cursor() 方法,且没有 cursor.count()、cursor.hasNext() 方法支持,对于一些想判断如果游标没有数据做一些特殊处理,处理起来不是很友好。
const userCursor = await User.find({}).cursor();
for await (const user of userCursor) {
}
- 1.
- 2.
- 3.
- 4.
一个关于游标的 Bug
在 Node.js 群里,一个群友发来消息使用游标遇到了问题,后来也对这个问题做了一些查找和验证,下文会介绍,基于一个特定版本和特定的应用场景才会出现这个问题,放在这里也是希望用到的朋友能少踩一个坑。
MongoDB Node.js 驱动程序在 3.5.4 版本基于游标迭代查询数据时,如果用了 limit 限制返回的数据条目,并且使用 hasNext(),存在一个 Bug,首先是从返回的游标对象取出的 count 数不对,其次是遍历出的数据条目与实际 limit count 数对不上,如果 limit 为奇数还会收到 MongoError: Cursor is closed 错误。
如果需要调整每一次的 getMore() 数量,游标可以结合 batchSize 使用。为什么用了游标还要使用 limit?这个也可以思考下。
const userCursor = await collection.find({}).limit(5);
console.log('cursor count: ', await userCursor.count());
try {
while (await userCursor.hasNext()) {
const doc = await userCursor.next();
console.log(doc);
}
} catch (err) {
console.error(err.stack);
}
userCursor.close();
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
mongodb@^3.5.4 版本输出结果:
cursor count: 10000
{ _id: 61d6590b92058ddefbac6a14, userID: 0 }
{ _id: 61d6590b92058ddefbac6a15, userID: 1 }
null
MongoError: Cursor is closed
at Function.create (/test/node_modules/mongodb/lib/core/error.js:43:12)
at Cursor.hasNext (/test/node_modules/mongodb/lib/cursor.js:197:24)
at file:///test/index.mjs:42:27
at processTicksAndRejections (internal/process/task_queues.js:93:5)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
NPM 包 mongodb 受影响版本为 3.5.4 参见 issue jira.mongodb.org/browse/NODE-2483[5]NPM 包 mongoose 受影响版本为 5.9.4 参见 issue github.com/Automattic/mongoose/issues/8664[6]
参考资料
[1]https://www.cnblogs.com/vajoy/p/6349817.html: https://www.cnblogs.com/vajoy/p/6349817.html
[2]batchSize: https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/#cursor-batches
[3]cursorTimeoutMillis#Default: 600000 (10 minutes): https://docs.mongodb.com/manual/reference/parameters/#mongodb-parameter-param.cursorTimeoutMillis
[4]DBQuery.Option.noTimeout: https://docs.mongodb.com/manual/reference/method/cursor.addOption/#mongodb-data-DBQuery.Option.noTimeout
[5]NPM 包 mongodb 受影响版本为 3.5.4 参见 issue jira.mongodb.org/browse/NODE-2483: https://jira.mongodb.org/browse/NODE-2483
[6]NPM 包 mongoose 受影响版本为 5.9.4 参见 issue github.com/Automattic/mongoose/issues/8664: https://github.com/Automattic/mongoose/issues/8664