视觉识别的快速发展始于 Vision transformer (ViT) 的引入,其很快取代了传统卷积神经网络 (ConvNet),成为最先进的图像分类模型。另一方面, ViT 模型在包括目标检测、语义分割等一系列计算机视觉任务中存在很多挑战。因此,有研究者提出分层 Transformer(如 Swin Transformer),他们重新引入 ConvNet 先验,这样使得 Transformer 作为通用视觉主干实际上可行,并在各种视觉任务上表现出卓越的性能。
然而,这种混合方法的有效性在很大程度上仍归功于 Transformer 的内在优势,而不是卷积固有的归纳偏置。在这项工作中,来自 FAIR 、UC 伯克利的研究者重新检查了设计空间并测试了纯 ConvNet 所能达到的极限。研究者逐渐将标准 ResNet「升级(modernize」为视觉 Transformer 的设计,并在此过程中发现了导致性能差异的几个关键组件。

- 论文地址:https://arxiv.org/pdf/2201.03545.pdf
- 代码地址:https://github.com/facebookresearch/ConvNeXt
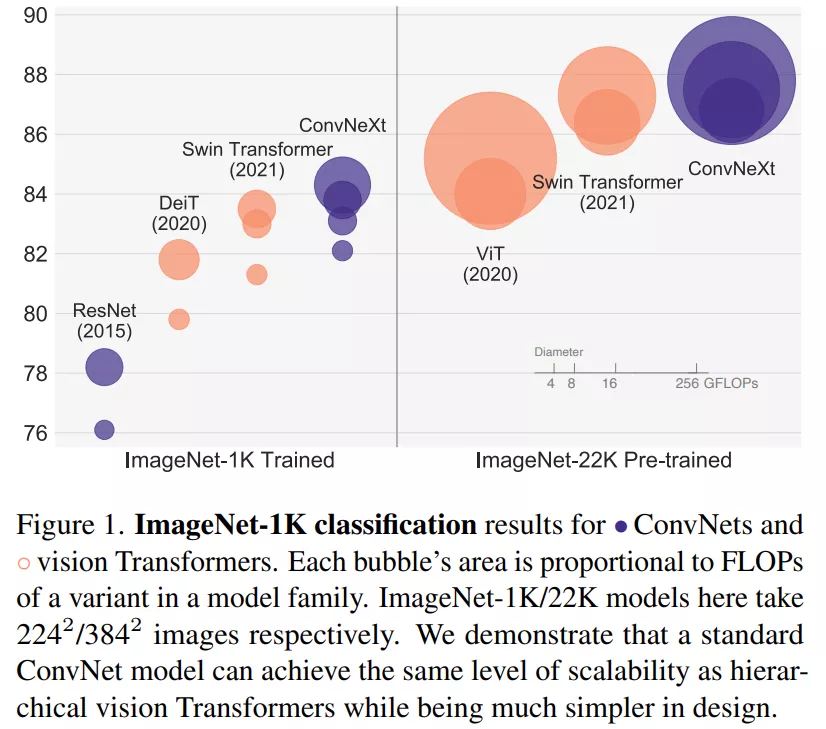
研究者将这一系列纯 ConvNet 模型,命名为 ConvNeXt。ConvNeXt 完全由标准 ConvNet 模块构建,在准确性和可扩展性方面 ConvNeXt 取得了与 Transformer 具有竞争力的结果,达到 87.8% ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformer,同时保持标准 ConvNet 的简单性和有效性。
值得一提的是,该论文一作为刘壮(Zhuang Liu),是大名鼎鼎 DenseNet 的共同一作,凭借论文《Densely Connected Convolutional Networks》,摘得 CVPR 2017 最佳论文奖。作者谢赛宁是ResNeXt的一作。
升级卷积神经网络
该研究梳理了从 ResNet 到类似于 Transformer 的卷积神经网络的发展轨迹。该研究根据 FLOPs 考虑两种模型大小,一种是 ResNet-50 / Swin-T 机制,其 FLOPs 约为 4.5×10^9,另一种是 ResNet-200 / Swin-B 机制,其 FLOPs 约为 15.0×10^9。为简单起见,该研究使用 ResNet-50 / Swin-T 复杂度模型展示实验结果。
为了探究 Swin Transformer 的设计和标准卷积神经网络的简单性,该研究从 ResNet-50 模型出发,首先使用用于训练视觉 Transformer 的类似训练方法对其进行训练,与原始 ResNet-50 相比的结果表明性能获得了很大的提升,并将改进后的结果作为基线。
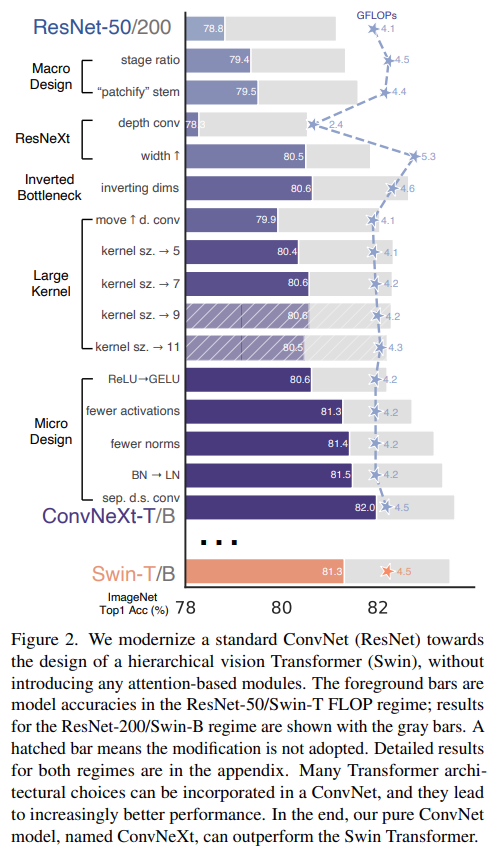
然后该研究制定了一系列设计决策,总结为 1) 宏观设计,2) ResNeXt,3) 反转瓶颈,4) 卷积核大小,以及 5) 各种逐层微设计。下图 2 展示了「升级网络」每一步的实现过程和结果,所有模型都是在 ImageNet-1K 上进行训练和评估的。由于网络复杂度和最终性能密切相关,因此该研究在探索过程中粗略控制了 FLOPs。
训练方法
除了网络架构的设计,训练过程也会影响最终性能。视觉 Transformer 不仅带来了一些新的架构设计决策和模块,而且还为视觉领域引入了多种训练方法(例如 AdamW 优化器)。这主要与优化策略和相关的超参数设置有关。
因此,该研究第一步使用视觉 Transformer 训练程序训练基线模型(ResNet50/200)。2021 年 Ross Wightman 等人的论文《 An improved training procedure in timm 》展示了一组显著提高 ResNet-50 模型性能的训练方法。而在本篇论文中,研究者使用了一种类似于 DeiT 和 Swin Transformer 的训练方法。训练从 ResNet 原始的 90 个 epoch 扩展到了 300 个 epoch。
该研究使用了 AdamW 优化器、Mixup、Cutmix、RandAugment、随机擦除(Random Erasing)等数据增强技术,以及随机深度和标签平滑(Label Smoothing)等正则化方案。这种改进的训练方案将 ResNet-50 模型的性能从 76.1% 提高到了 78.8%(+2.7%),这意味着传统 ConvNet 和视觉 Transformer 之间很大一部分性能差异可能是训练技巧导致的。
宏观设计
该研究第二步分析了当前 Swin Transformer 的宏观网络设计。Swin Transformer 使用类似于卷积神经网络的多阶段设计,每个阶段具有不同的特征图分辨率。其中两个重要的设计考量是阶段计算比和主干架构。
一方面,ResNet 中跨阶段计算分布的原始设计很大程度上是受实验影响的。另一方面,Swin-T 遵循相同的原则,但阶段计算比略有不同。该研究将每个阶段的块数从 ResNet-50 中的 (3, 4, 6, 3) 调整为 (3, 3, 9, s3),使得 FLOPs 与 Swin-T 对齐。这将模型准确率从 78.8% 提高到了 79.4%。
通常,主干架构重点关注网络如何处理输入图像。由于自然图像中固有的冗余性,普通架构在标准 ConvNet 和视觉 Transformer 中积极地将输入图像下采样到适当的特征图大小。标准 ResNet 中包含一个步长为 2 的 7×7 卷积层和一个最大池,这让输入图像可进行 4 倍下采样。而视觉 Transformer 使用了「patchify」策略,Swin Transformer 虽然使用类似的「patchify」层,但使用更小的 patch 大小来适应架构的多阶段设计。该研究将 ResNet 主干架构替换为使用 4×4、步长为 4 的卷积层实现的 patchify 层,准确率从 79.4% 提升为 79.5%。这表明 ResNet 的主干架构可以用更简单的 patchify 层替代。
ResNeXt-ify
第三步该研究尝试采用 ResNeXt [82] 的思路,ResNeXt 比普通的 ResNet 具有更好的 FLOPs / 准确率权衡。核心组件是分组卷积,其中卷积滤波器被分成不同的组。ResNeXt 的指导原则是「使用更多的组,扩大宽度」。更准确地说,ResNeXt 对瓶颈块中的 3×3 卷积层采用分组卷积。由于显著降低了 FLOPs,因此这扩展了网络宽度以补偿容量损失。
该研究使用分组卷积的一种特殊情况——深度卷积(depthwise convolution),其中组数等于通道数。深度卷积已被 MobileNet [32] 和 Xception [9] 使用。研究者注意到,深度卷积类似于自注意力中的加权求和操作,在每个通道的基础上进行操作,即仅在空间维度上混合信息。深度卷积的使用有效地降低了网络的 FLOPs。按照 ResNeXt 中提出的策略,该研究将网络宽度增加到与 Swin-T 的通道数相同(从 64 增加到 96)。随着 FLOPs (5.3G) 的增加,网络性能达到了 80.5%。
反转瓶颈
Transformer 中一个重要的设计是创建了反转瓶颈,即 MLP 块的隐藏维度比输入维度宽四倍,如下图 4 所示。有趣的是,Transformer 的这种设计与卷积神经网络中使用的扩展比为 4 的反转瓶颈设计有关联。
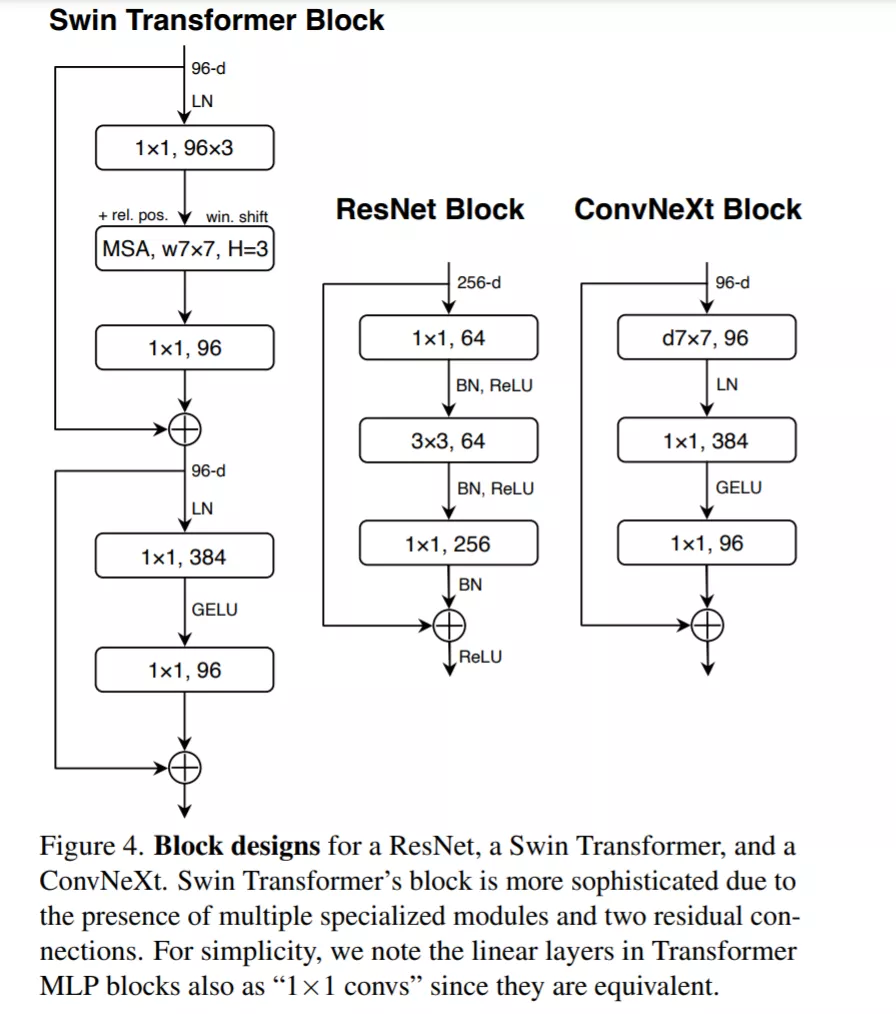
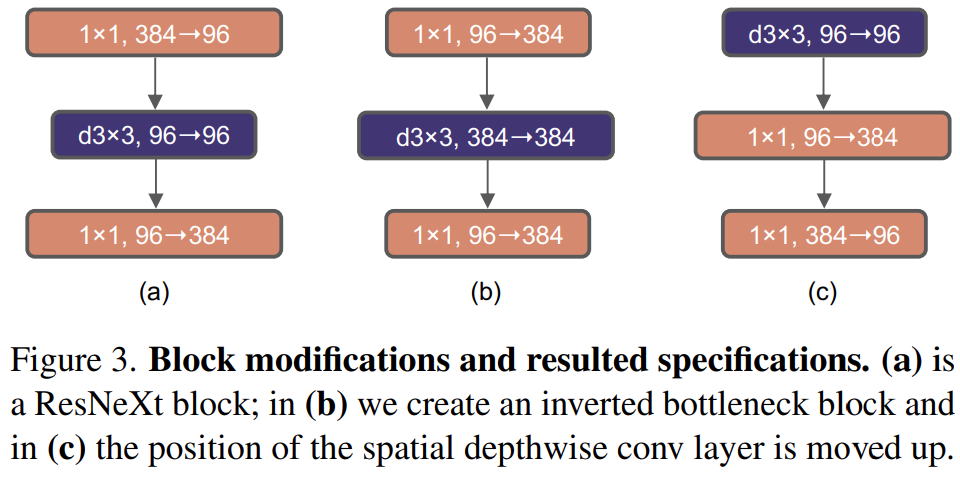
因此该研究第四步探索了反转瓶颈的设计。如下图 3 所示,尽管深度卷积层的 FLOPs 增加了,但由于下采样残差块的 shortcut 1×1 卷积层的 FLOPs 显著减少,整个网络的 FLOPs 减少到 4.6G。有趣的是,这会让性能从 80.5% 稍稍提高至 80.6%。在 ResNet-200 / Swin-B 方案中,这一步带来了更多的性能提升——从 81.9% 提升到 82.6%,同时也减少了 FLOPs。
卷积核大小
第五步该研究探索了大型卷积核的作用。视觉 Transformer 最显著的特性是其非局部自注意力,每一层都具有全局感受野。虽然已有卷积神经网络使用了大卷积核,但黄金标准(VGGNet [62] )是堆叠小卷积核(3×3)的卷积层。尽管 Swin Transformer 重新将局部窗口引入到自注意力块中,但窗口大小至少为 7×7,明显大于 3×3 的 ResNe(X)t 卷积核大小。因此该研究重新审视了在卷积神经网络中使用大卷积核的作用。
向上移动深度卷积层。要探索大卷积核,一个先决条件是向上移动深度卷积层的位置(如图 3(c) 所示)。类似地,Transformer 中也将 MSA 块放置在 MLP 层之前。由于已经设置一个反转瓶颈块,复杂、低效的模块(MSA、大卷积核)通道变少,而高效、密集的 1×1 层将完成繁重的工作。因此这个中间步骤将 FLOPs 减少到 4.1G,导致性能暂时下降到 79.9%。
增大卷积核。经过上述准备工作,采用更大的卷积核是具有显著优势的。该研究尝试了几种卷积核大小:3、5、7、9、11。网络的性能从 79.9% (3×3) 提高为 80.6% (7×7),而网络的 FLOPs 大致保持不变。
此外,研究者观察到较大的卷积核的好处是在 7×7 处会达到饱和点,并在大容量模型中验证了这种行为。当卷积核大小超过 7×7 时,ResNet-200 机制模型没有表现出进一步的增益。因此该研究在每个块中都使用了 7×7 深度卷积。
至此,宏观尺度网络架构的升级调整已经完成。
微观设计
下一步研究者探究了一些微观尺度上的架构差异——这里的大部分探索都是在层级完成的,重点是激活函数和归一化层的具体选择。
用 GELU 替代 ReLU。随着时间的推移,研究者已经开发了许多激活函数,但 ReLU 由于其简单性和有效性,仍然在 ConvNet 中广泛使用。ReLU 也被用作原始 Transformer 中的激活函数。GELU 可以被认为是 ReLU 的更平滑变体,被用于最先进的 Transformer,包括 Google 的 BERT 和 OpenAI 的 GPT-2 ,以及 ViT 等。该研究发现 ReLU 在 ConvNet 中也可以用 GELU 代替,准确率保持不变(80.6%)。
更少的激活函数。Transformer 和 ResNet 块之间的一个小区别是 Transformer 的激活函数较少。如图 4 所示,该研究从残差块中消除了所有 GELU 层,除了在两个 1×1 层之间的 GELU 层,这是复制了 Transformer 块的风格。这个过程将结果提高了 0.7% 到 81.3%,实际上与 Swin-T 性能相当。
更少的归一化层。Transformer 块通常也具有较少的归一化层。在这里,该研究删除了两个 BatchNorm (BN) 层,在 conv 1 × 1 层之前只留下一个 BN 层。这进一步将性能提升至 81.4%,已经超过了 Swin-T 的结果。请注意,该研究的每个块的归一化层比 Transformer 还要少,研究人员发现在块的开头添加一个额外的 BN 层并不能提高性能。
用 LN 代替 BN。BatchNorm(BN)是 ConvNet 中的重要组成部分,因为它提高了收敛性并减少了过拟合。然而,BN 也有许多错综复杂的东西,可能会对模型的性能产生不利影响 。研究者曾多次尝试开发替代方案,但 BN 仍然是大多数视觉任务的首选方法。在原始 ResNet 中直接用 LN 代替 BN 性能欠佳。随着网络架构和训练技术的改进,该研究重新审视使用 LN 代替 BN 的影响,得出 ConvNet 模型在使用 LN 训练时没有任何困难;实际上,性能会改进一些,获得了 81.5% 的准确率。
分离式(Separate)下采样层。在 ResNet 中,空间下采样是通过每个 stage 开始时的残差块来实现的,使用 stride =2 的 3×3 卷积。在 Swin Transformer 中,在各个 stage 之间添加了一个分离式下采样层。该研究探索了一种类似的策略,在该策略中,研究者使用 stride =2 的 2×2 卷积层进行空间下采样。令人惊讶的是,这种改变会导致不同的训练结果。进一步调查表明,在空间分辨率发生变化的地方添加归一化层有助于稳定训练。该研究可以将准确率提高到 82.0%,大大超过 Swin-T 的 81.3%。该研究采用分离式下采样层,得到了最终模型 ConvNeXt。ResNet、Swin 和 ConvNeXt 块结构的比较如图 4 所示。
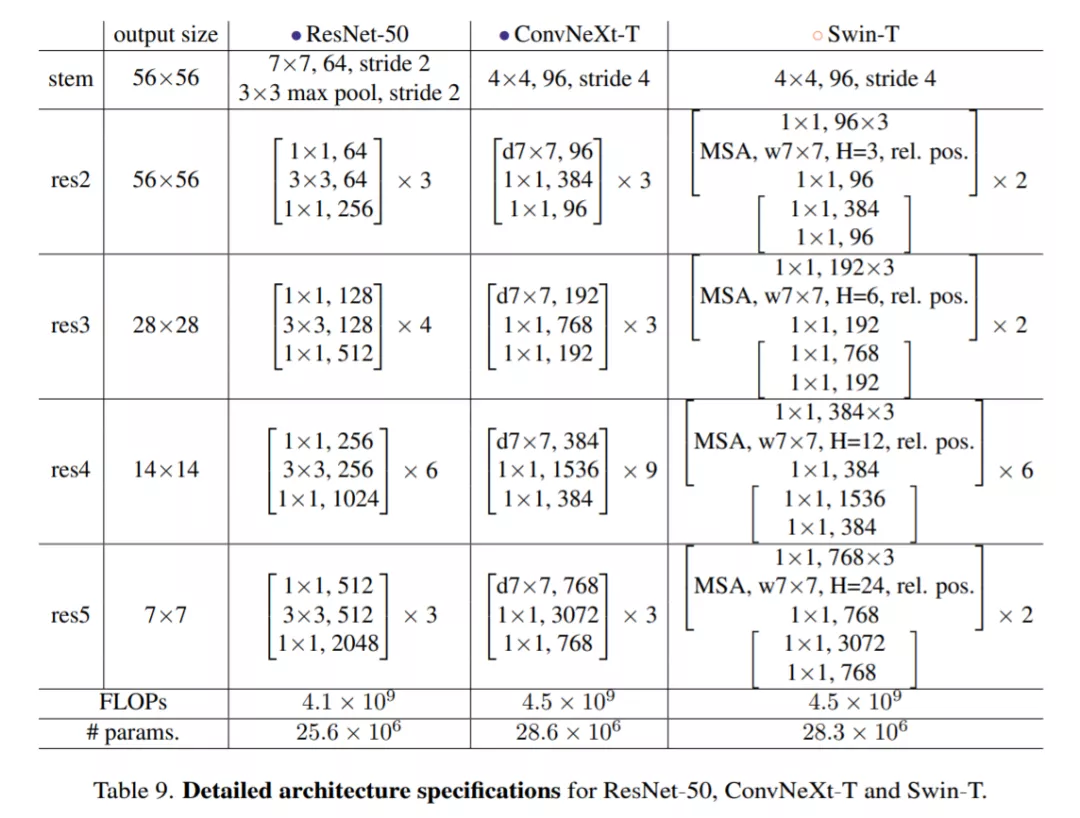
ResNet-50、Swin-T 和 ConvNeXt-T 的详细架构规范的比较如表 9 所示。
实验
ImageNet 实验评估
该研究构建了不同的 ConvNeXt 变体,ConvNeXtT/S/B/L,与 Swin-T/S/B/L 具有相似的复杂性,可进行对标实验评估。此外,该研究还构建了一个更大的 ConvNeXt-XL 来进一步测试 ConvNeXt 的可扩展性。不同变体模型的区别在于通道数、模块数,详细信息如下:

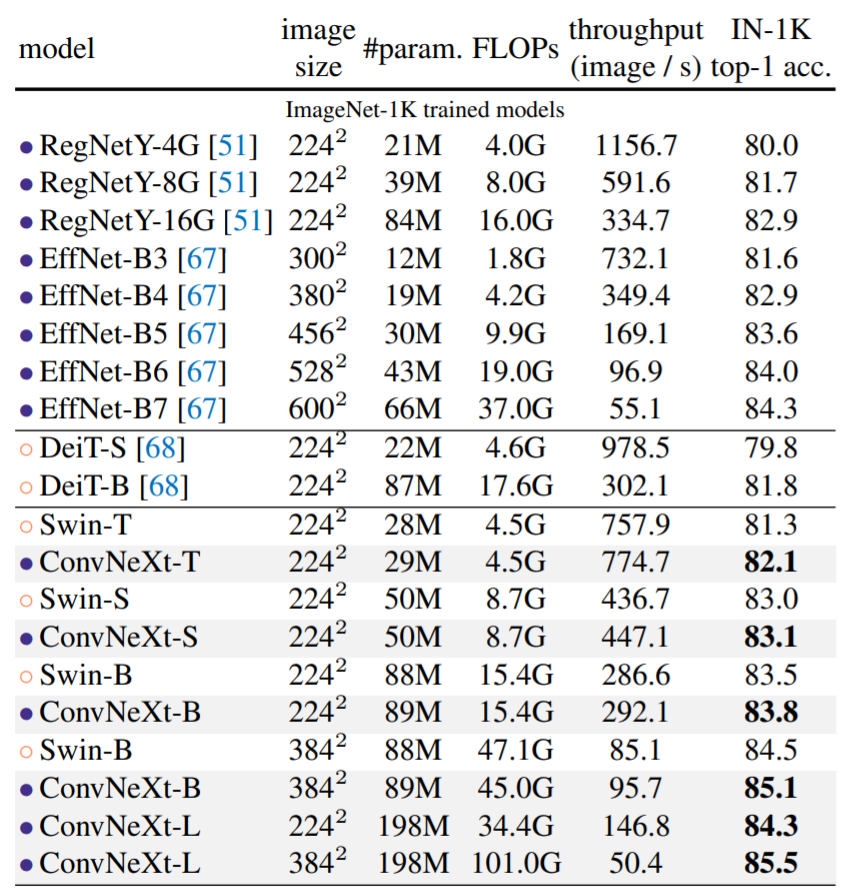
Results ImageNet-1K:下表是 ConvNeXt 与 Transformer 变体 DeiT、Swin Transformer,以及 RegNets 和 EfficientNets 的结果比较。
由结果可得:ConvNeXt 在准确率 - 计算权衡以及推理吞吐量方面取得了与 ConvNet 基线(RegNet 和 EfficientNet )具有竞争力的结果;ConvNeXt 的性能也全面优于具有类似复杂性的 Swin Transformer;与 Swin Transformers 相比,ConvNeXts 在没有诸如移位窗口或相对位置偏置等专门模块的情况下也具有更高的吞吐量。
ImageNet-22K:下表(表头参考上表)中展示了从 ImageNet-22K 预训练中微调的模型的结果。这些实验很重要,因为人们普遍认为视觉 Transformer 具有较少的归纳偏置,因此在大规模预训练时可以比 ConvNet 表现更好。该研究表明,在使用大型数据集进行预训练时,正确设计的 ConvNet 并不逊于视觉 Transformer——ConvNeXt 的性能仍然与类似大小的 Swin Transformer 相当或更好,吞吐量略高。此外,该研究提出的 ConvNeXt-XL 模型实现了 87.8% 的准确率——在 384^2 处比 ConvNeXt-L 有了相当大的改进,证明了 ConvNeXt 是可扩展的架构。
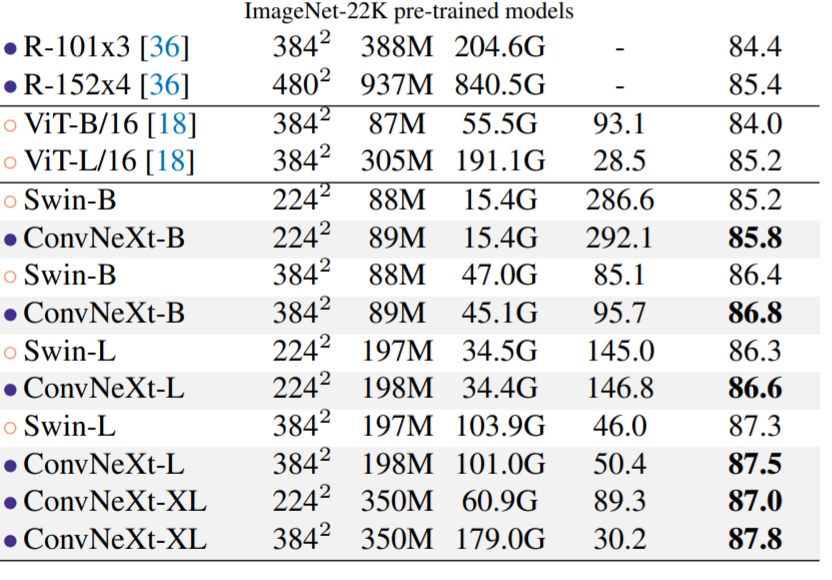
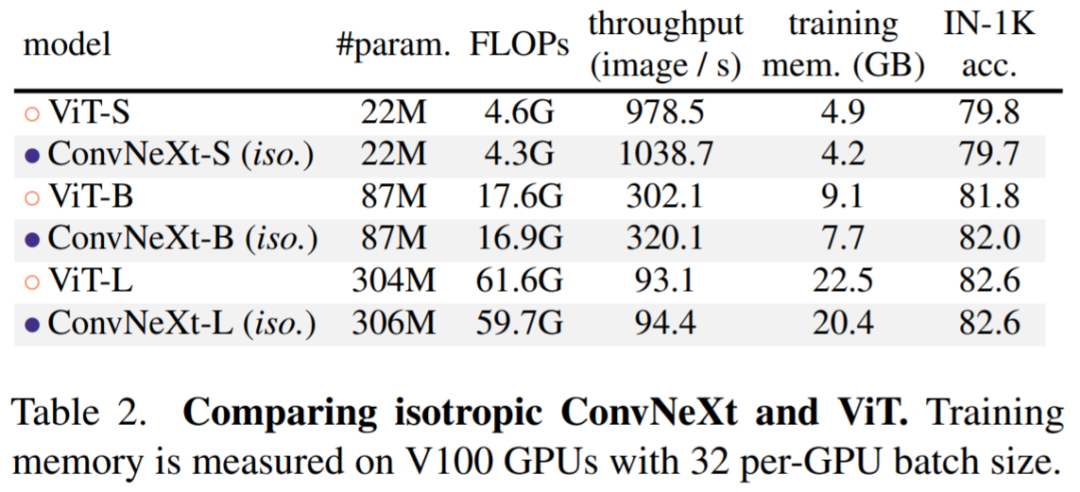
Isotropic ConvNeXt 与 ViT 对比:在消融实验中,研究者使用与 ViT-S/B/L (384/768/1024) 相同的特征尺寸构建 isotropic ConvNeXt-S/B/L。深度设置为 18/18/36 以匹配参数和 FLOP 的数量,块结构保持不变(图 4)。ImageNet-1K 在 224^2 分辨率下的结果如表 2 所示。结果显示 ConvNeXt 的性能与 ViT 相当,这表明 ConvNeXt 块设计在用于非分层模型时仍具有竞争力。
下游任务评估
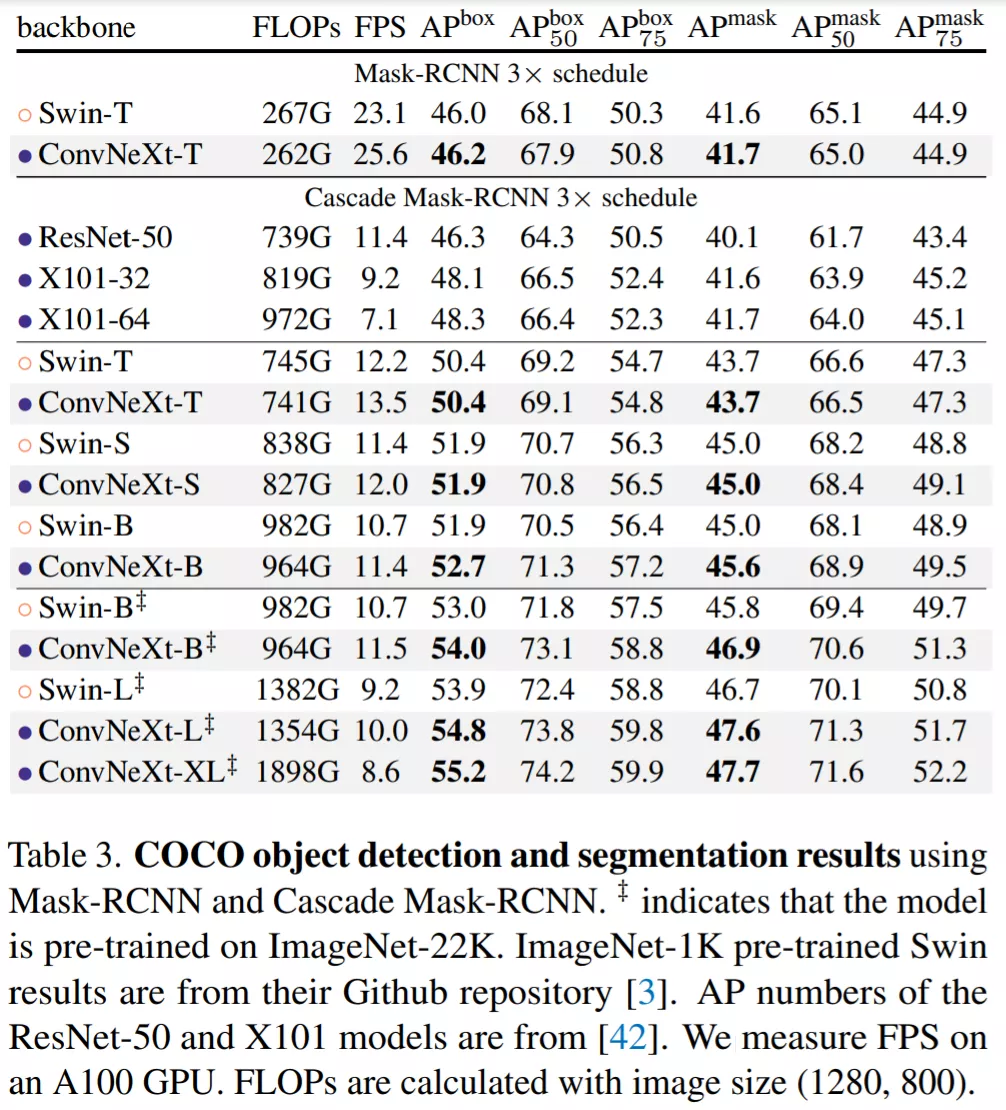
在 COCO 上的目标检测和分割研究:该研究以 ConvNeXt 为主干,在 COCO 数据集上微调 Mask R-CNN 和 Cascade Mask R-CNN 。表 3 比较了 Swin Transformer、ConvNeXt 和传统 ConvNet(如 ResNeXt)在目标检测和实例分割上的结果。结果表明在不同的模型复杂性中,ConvNeXt 的性能与 Swin Transformer 相当或更好。
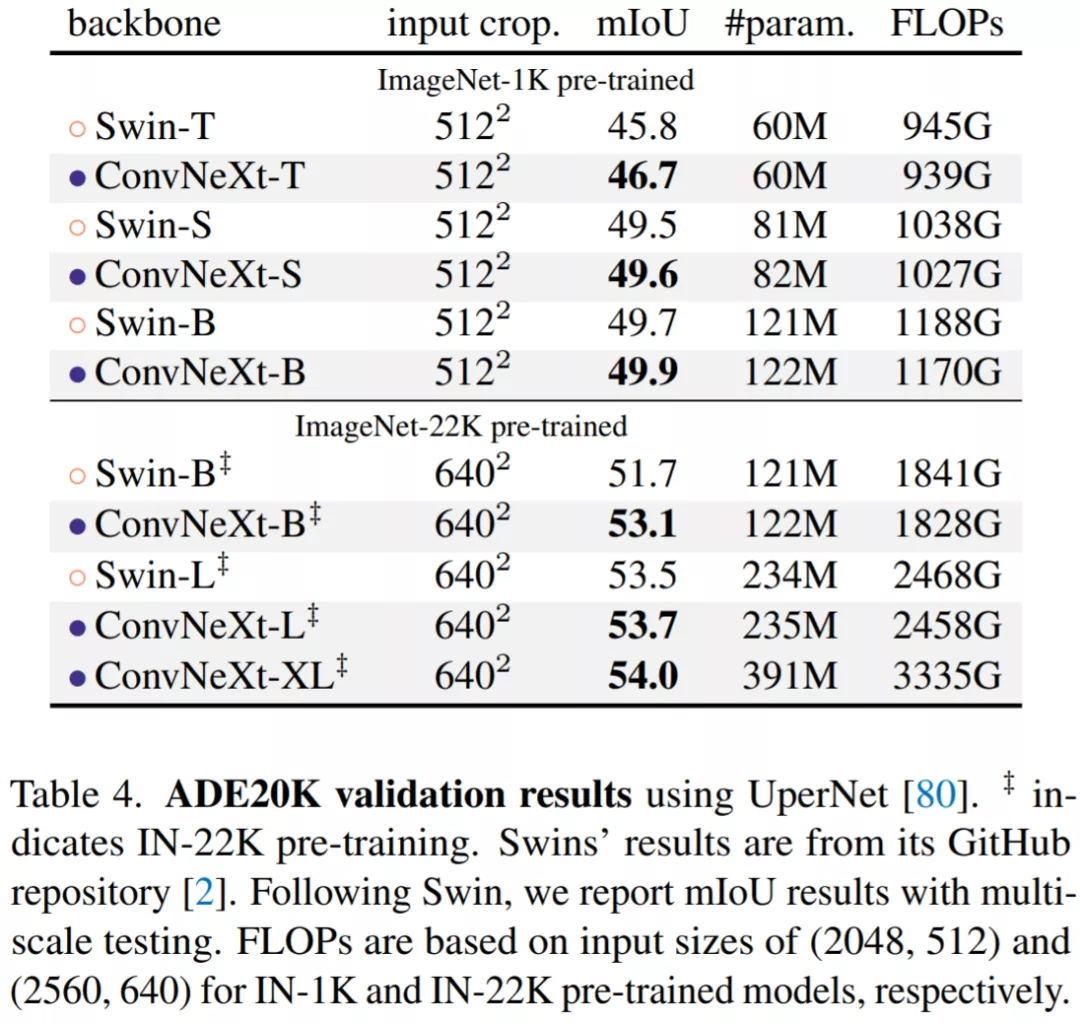
基于 ADE20K 的语义分割:在表 4 中,该研究报告了具有多尺度测试的验证 mIoU。ConvNeXt 模型可以在不同的模型容量上实现具有竞争力的性能,进一步验证了 ConvNeXt 设计的有效性。