大家好,我是Python进阶者。
前言
前几天有个学生娃子找我帮忙做点可视化的作业,作业内容包括采集网易云音乐热评评论内容,数据量1W作业足够,然后就是做点数据分析相关的工作即可。这份大作业里边有网络爬虫,有数据分析和数据处理,还有可视化,算是一个大实验了,还需要上交实验报告。这里拿出来部分知识点,给大家分享。学生娃的作业,参考了这个文章:网易云音乐评论爬取。
数据来源
首先是数据来源,来自网易云音乐热评,代码这里就不放出来了,调用了API获取的,抓取难度就少了许多,这里不在赘述了。

分析过程
时间处理
下面的代码主要是评论时间分布,主要是针对时间列做了数据处理,常规操作,你也对照的去以日期和月份去挖掘下有意思的事情。
import pandas as pd
from pyecharts import Line
# 读取数据
df = pd.read_csv('music_comments.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 根据评论ID去重
df = df.drop_duplicates('commentid')
df = df.dropna()
# 获取时间
df['time'] = [int(i.split(' ')[1].split(':')[0]) for i in df['date']]
# 分组汇总
date_message = df.groupby(['time'])
date_com = date_message['time'].agg(['count'])
date_com.reset_index(inplace=True)
# 绘制走势图
attr = date_com['time']
v1 = date_com['count']
line = Line("歌曲被爆抄袭后-评论的时间分布", title_pos='center', title_top='18', width=800, height=400)
line.add("", attr, v1, is_smooth=True, is_fill=True, area_color="#000", is_xaxislabel_align=True, xaxis_min="dataMin", area_opacity=0.3, mark_point=["max"], mark_point_symbol="pin", mark_point_symbolsize=55)
line.render("歌曲被爆抄袭后-评论的时间分布.html")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
运行之后,得到的效果图如下所示:
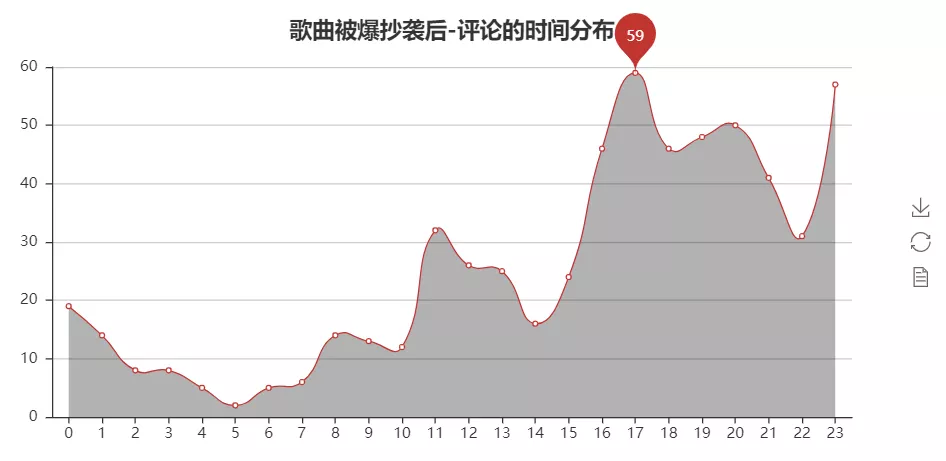
可以看到评论的小伙伴喜欢在下午临近下班和晚上的时候进行评论。
用户评论数量
代码和上面差不多,只需要更改下数据即可。
import pandas as pd
# 读取数据
df = pd.read_csv('music_comments.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 根据评论ID去重
df = df.drop_duplicates('commentid')
df = df.dropna()
# 分组汇总
user_message = df.groupby(['userid'])
user_com = user_message['userid'].agg(['count'])
user_com.reset_index(inplace=True)
user_com_last = user_com.sort_values('count', ascending=False)[0:10]
print(user_com_last)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
运行之后,得到的结果如下所示:
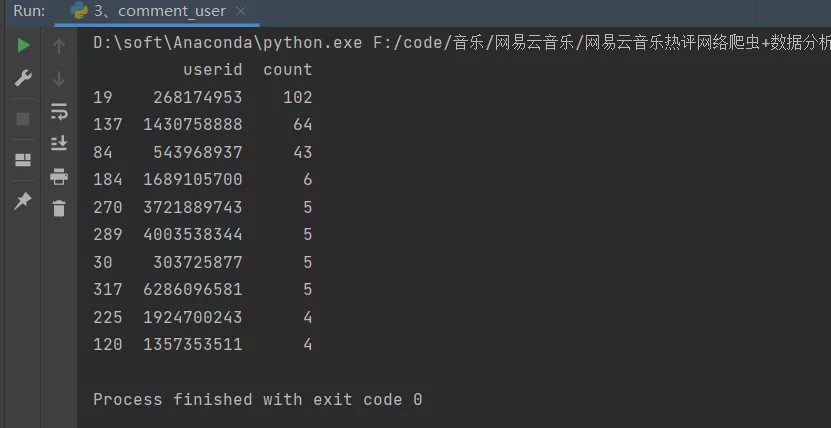
可以看到有忠粉,狂粉,评论数据上百,恐怖如斯。
评论词云
词云这个老生常谈了,经常做,直接套用模板,改下底图即可,代码如下:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pandas as pd
import random
import jieba
# 设置文本随机颜色
def random_color_func(word=None, font_size=None, position=None, orientation=None, font_path=None, random_state=None):
h, s, l = random.choice([(188, 72, 53), (253, 63, 56), (12, 78, 69)])
return "hsl({}, {}%, {}%)".format(h, s, l)
# 读取信息
df = pd.read_csv('music_comments.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 根据评论ID去重
df = df.drop_duplicates('commentid')
df = df.dropna()
words = pd.read_csv('chineseStopWords.txt', encoding='gbk', sep='\t', names=['stopword'])
# 分词
text = ''
for line in df['comment']:
text += ' '.join(jieba.cut(str(line), cut_all=False))
# 停用词
stopwords = set('')
stopwords.update(words['stopword'])
backgroud_Image = plt.imread('music.jpg')
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='FZSTK.TTF',
max_words=2000,
max_font_size=250,
min_font_size=15,
color_func=random_color_func,
prefer_horizontal=1,
random_state=50,
stopwords=stopwords
)
wc.generate_from_text(text)
# img_colors = ImageColorGenerator(backgroud_Image)
# 看看词频高的有哪些
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
print(sort[:50])
plt.imshow(wc)
plt.axis('off')
wc.to_file("网易云音乐评论词云.jpg")
print('生成词云成功!')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
最后生成的词云图如下所示:

用户年龄
代码和上面差不多,只需要更改下数据即可,这里直接放效果图了,如下图所示:
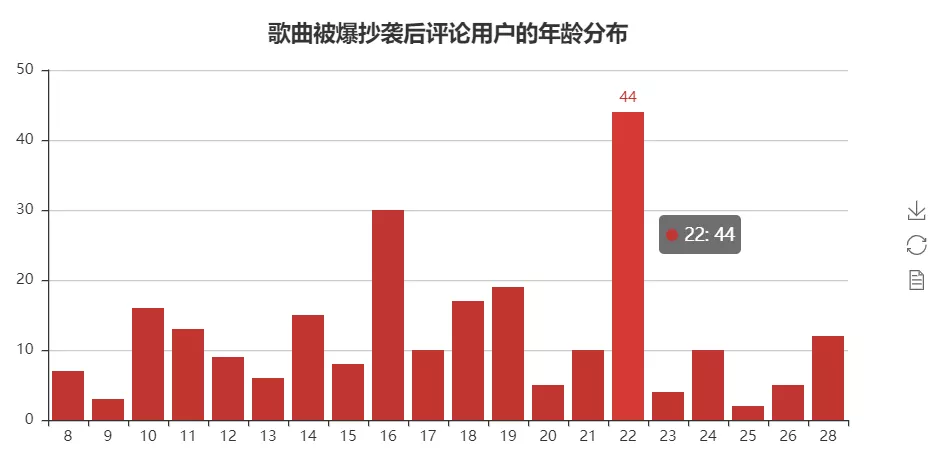
感觉还是年轻的粉丝居多啊!
地区分布
这个代码稍微复杂一些了,毕竟涉及到地图,代码如下:
import pandas as pd
from pyecharts import Map
def city_group(cityCode):
"""
城市编码
"""
city_map = {
'11': '北京',
'12': '天津',
'31': '上海',
'50': '重庆',
'5e': '重庆',
'81': '香港',
'82': '澳门',
'13': '河北',
'14': '山西',
'15': '内蒙古',
'21': '辽宁',
'22': '吉林',
'23': '黑龙江',
'32': '江苏',
'33': '浙江',
'34': '安徽',
'35': '福建',
'36': '江西',
'37': '山东',
'41': '河南',
'42': '湖北',
'43': '湖南',
'44': '广东',
'45': '广西',
'46': '海南',
'51': '四川',
'52': '贵州',
'53': '云南',
'54': '西藏',
'61': '陕西',
'62': '甘肃',
'63': '青海',
'64': '宁夏',
'65': '新疆',
'71': '台湾',
'10': '其他',
}
cityCode = str(cityCode)
return city_map[cityCode[:2]]
# 读取数据
df = pd.read_csv('music_comments.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 根据评论ID去重
df = df.drop_duplicates('commentid')
df = df.dropna()
# 进行省份匹配
df['location'] = df['city'].apply(city_group)
# 分组汇总
loc_message = df.groupby(['location'])
loc_com = loc_message['location'].agg(['count'])
loc_com.reset_index(inplace=True)
# 绘制地图
value = [i for i in loc_com['count']]
attr = [i for i in loc_com['location']]
print(value)
print(attr)
map = Map("歌曲被爆抄袭后评论用户的地区分布图", title_pos='center', title_top=0)
map.add("", attr, value, maptype="china", is_visualmap=True, visual_text_color="#000", is_map_symbol_show=False, visual_range=[0, 60])
map.render('歌曲被爆抄袭后评论用户的地区分布图.html')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
最后得到的效果图如下所示:
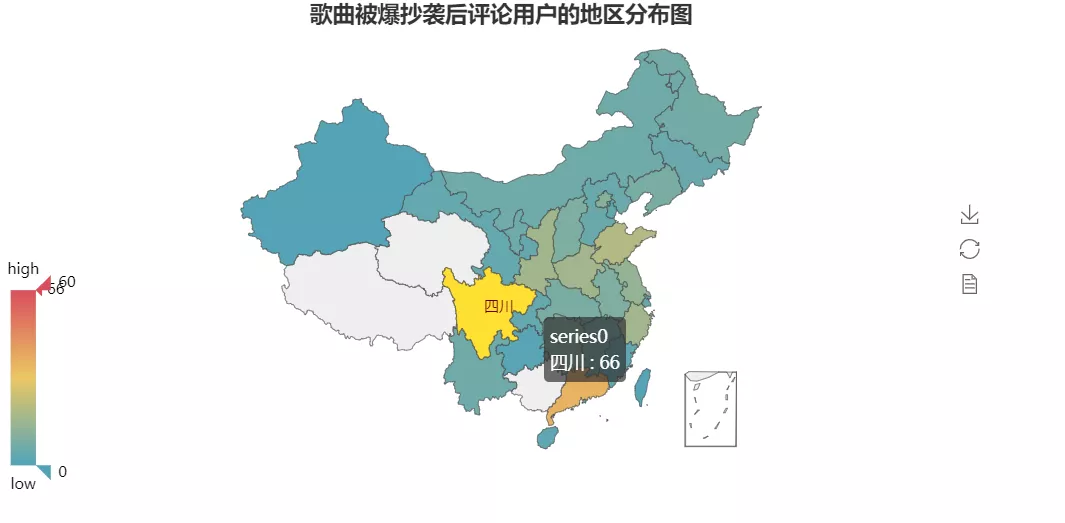
可以看到四川、广东省的评论数量居多。
粉丝性别
代码和上面的差不多,这里不再赘述,直接上效果图了。
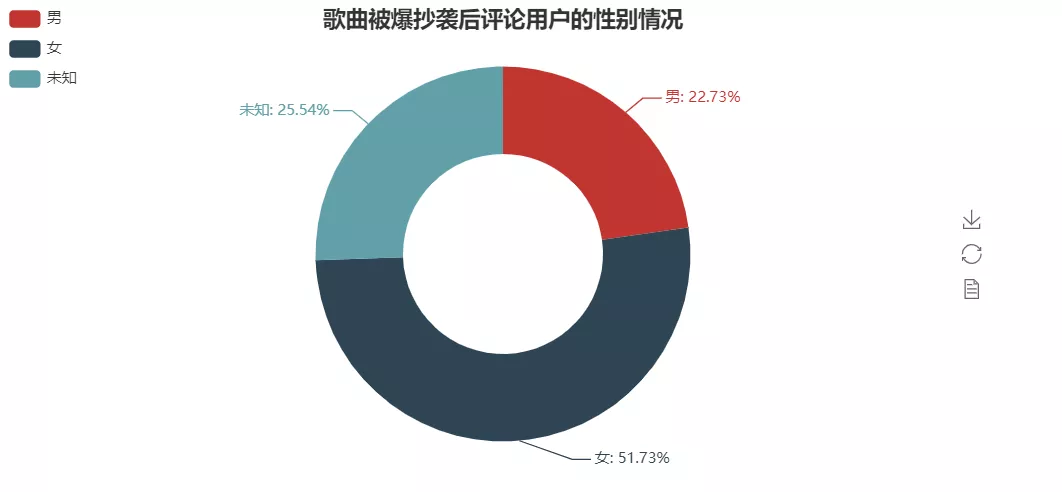
可以看到女粉丝占据了大头。
总结
大家好,我是Python进阶者。这篇文章主要基于网易云热评数据,利用了Python中的数据处理库pandas进行数据处理和分析,并利用可视化库pyecharts给大家分享了相关图形的制作方法,并发现了一些有趣的数据分析结果。