批大小是机器学习中重要的超参数之一。这个超参数定义了在更新内部模型参数之前要处理的样本数量。
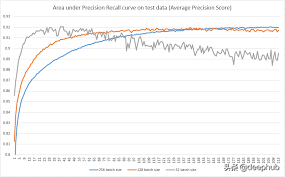
上图为使用 SGD 测试不同批量大小的示例。
批量大小可以决定许多基于深度学习的神经网络的性能。 有很多研究都在为学习过程评估最佳批量大小。 例如,对于 SGD可以使用批量梯度下降(使用批量中的所有训练样本)或小批量(使用一部分训练数据),甚至在每个样本后更新(随机梯度下降)。 这些不同的处理方式可以改变模型训练的的效果。
准确性并不是我们关心的唯一性能指标。 模型的泛化能力可能更加重要。 因为如果我们的模型在看不见的数据上表现不佳它就毫无用处。使用更大的批量会导致更差的网络泛化。 论文“ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA”的作者试图调查这种现象并找出为什么会发生这种情况。 他们的发现很有趣,所以我将在本文中进行详细介绍。 了解这一点将能够为自己的神经网络和训练方式做出更好的决策。
理解论文的假设
要理解任何论文,首先要了解作者试图证明的内容。 作者声称他们发现了为什么大批量会导致更差的泛化。 他们“提供了支持大批量方法趋向于收敛到训练和测试函数的sharp minima(尖锐的最小值)的观点的数值证据——众所周知,sharp minima会导致较差的泛化。 而小批量方法始终收敛到flat minima(平坦的最小值),论文的实验支持一个普遍持有的观点,即这是由于梯度估计中的固有噪声造成的。” 我们将在本篇文章中做更多的说明,所以让我们一步一步来。 下图描绘了尖锐最小值和平坦最小值之间的差异。
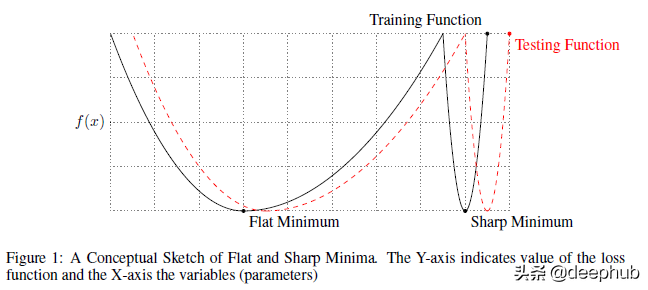
对于尖锐的最小值,X 的相对较小的变化会导致损失的较大变化
一旦你理解了这个区别,让我们理解作者验证的两个(相关的)主要主张:
- 使用大批量将使训练过程有非常尖锐的损失情况。 而这种尖锐的损失将降低网络的泛化能力。
- 较小的批量创建更平坦的损失图像。 这是由于梯度估计中的噪声造成的。
作者在论文中强调了这一点,声明如下:

我们现在将查看他们提供的证据。 他们设置实验的一些方法很有趣,会教会我们很多关于设置实验的知识。
定义锐度
锐度是一个易于掌握和可视化的直观概念。 但是它也存在有一些问题。 例如机器学习对高维数据进行计算/可视化可能很费资源和时间。 作者也提到了这一点, 所以他们使用更简单的启发式方法:通过相邻点来进行锐度的检查, 该函数的最大值就可以用于灵敏度的计算。
论文原文中说到:
我们采用了一种敏感性度量,虽然不完美,但在计算上是可行的,即使对于大型网络也是如此。 它基于探索解决方案的一个小邻域并计算函数 f 在该邻域中可以达到的最大值。 我们使用该值来测量给定局部最小值处训练函数的灵敏度。 由于最大化过程是不准确的,并且为了避免被仅在 Rn 的微小子空间中获得较大 f 值的情况所误导,我们在整个空间 Rn 以及随机流形中都执行了最大化
需要注意的是,作者将一定程度的交叉验证集成到程序中。 虽然从解决方案空间中获取多个样本似乎过于简单,但这是一种非常强大的方法并且适用于大多数情况。 如果你对他们计算的公式感兴趣,它看起来像这样。

查看相关的证明
我们了解了作者提出的基本术语/定义,让我们看看提出的一些证据。 本篇文章中无法分享论文/附录中的所有内容,所以如果你对所有细节感兴趣可以阅读论文的原文。
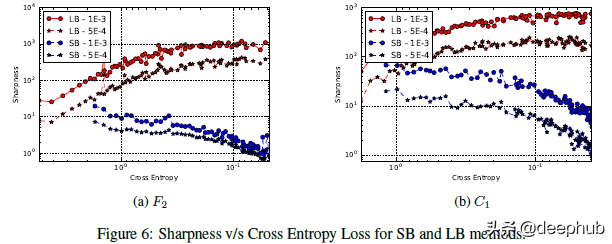
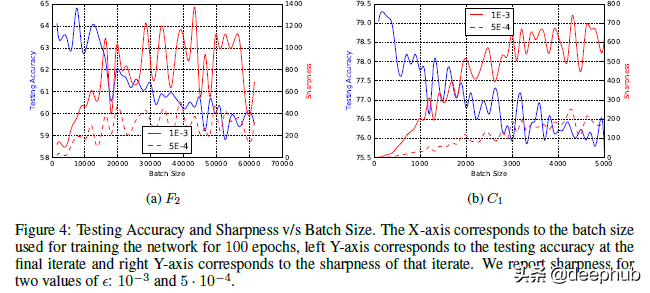
在上面的图中可以看到交叉熵损失与锐度的关系图。从图中可以看到,当向右移动时损失实际上越来越小。那么这个图表是什么意思呢?随着模型的成熟(损失减少),Large Batch 模型的清晰度会增加。用作者的话来说,“对于在初始点附近的较大的损失函数值,小批次 和 大批次 方法产生相似的锐度值。随着损失函数的减小,与 大批次 方法相对应的迭代的锐度迅速增加,而对于 小批次 方法锐度最初保持相对恒定然后降低,这表明在探索阶段之后会收敛到平坦的最小化器。”
作者还有其他几个实验来展示结果。除了在不同类型的网络上进行测试外,他们还在小批量和大批量网络上使用了热启动。结果也与我们所看到的非常一致。
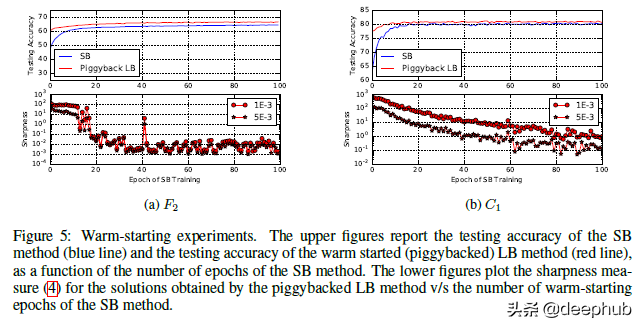
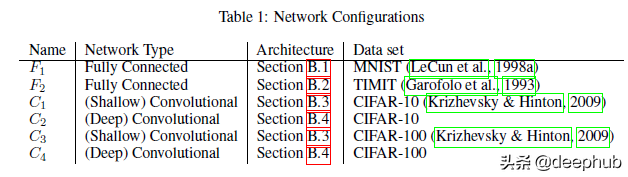
我在论文中发现的一个有趣的观点是,当他们证明了这种较低的泛化与使用较大批大小时的模型过拟合或过度训练无关时。 很容易假设过拟合是低泛化的原因(一般情况下我们都这么理解),但作者反对这一点。 要了解他们的论点,请查看此表。
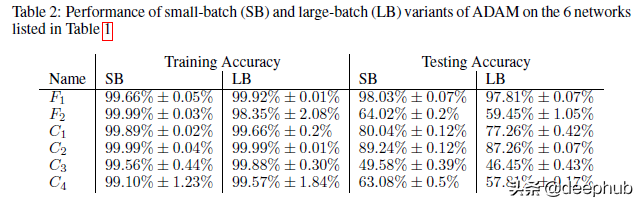
小批量训练通常具有更好的训练性能。 即使在我们使用小批量训练的训练精度较低的网络中,我们也注意到会有更高的训练精度。 作者以下原文可以作为重点,“我们强调,泛化差距不是由于统计中常见的过拟合或过度训练造成的。 这种现象以测试准确度曲线的形式表现出来,该曲线在某个迭代峰值处,然后由于模型学习训练数据的特性而衰减。 这不是我们在实验中观察到的。 F2 和 C1 网络的训练-测试曲线见图 2,它们是其他网络的代表。 因此,旨在防止模型过拟合的早停的启发式方法并不能够缩小泛化差距。”
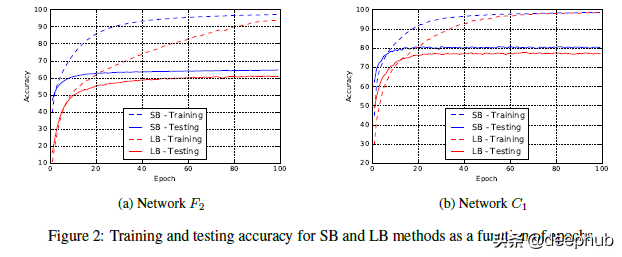
看看网络收敛到测试精度的速度有多快
简而言之,如果这是过度拟合的情况,将不会看到 大批次 方法的性能始终较低。 相反通过更早的停止,我们将避免过拟合并且性能会更接近。 这不是我们观察到的。 我们的学习曲线描绘了一幅截然不同的表现。