













本文根据魏亚东老师在〖2021 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。
讲师介绍
魏亚东,中国工商银行 软件开发中心三级经理,资深架构师,杭州研发部数据库专家团队牵头人和开发中心安全团队成员,负责技术管理、数据库、安全相关工作,目前负责SaaS云产品建设。2009年加入中国工商银行软件开发中心,致力于推动管理创新、效能提升,提供全面技术管控,推动自动化实施,实现业务价值的高质量快速交付;同时作为技术专家,为生产安全提供技术支持。
分享概要
- 风险介绍
- 风险防范
- 方法论
- 确保可落地
- 生产防控
- 生产防控
- SRE管控体系
- 未来畅想
大家好,感谢dbaplus社群给我这个和大家交流的机会,今天分享的主题是《工行MySQL研发管控和治理实践》。之前我在各种分享过程中,也多次强调过只有对自己来说最合适的产品,而没有所谓最好的产品,虽然每种数据库产品都把自己形容得很好,但实际上也都是针对一些特定场景去做的开发,即每种产品都有自己适用的场景,没有可以包打天下的产品。
一、风险介绍

首先介绍MySQL的痛点。因为MySQL是免费的,所以我们在使用过程中必须承担它所带来的风险,换句话说,这就是生命中不可承受之痛。比如慢SQL在业界就算是一种通病,不论哪个公司,只要用了MySQL数据库,慢SQL就必然是所有问题的重中之重。
像阿里在一篇介绍SRE团队建设与职能分工的文章中曾提及:在SRE建设过程中,他们发现,慢SQL已经成为了一种挑战:数据库出现瓶颈,无法支撑业务发展;慢SQL的数量呈爆发式增长,应用稳定性岌岌可危等。
而对于工行来说,同样遇到类似的问题,可以说是不可避免的问题:
数据库性能急剧下降,CPU占用100%
大家可以看图中左下角位置,这其实就是一个CPU在慢SQL影响下急剧飙升的情况。大量数据扫描会导致CPU飚高,1个线程最高可以把一个CPU吃满,如果并发线程多的话,整体的CPU使用率就会急剧飙升,后果很严重。大家都知道,InnoDB有一个线程池innodb_thread_concurrency,这个池是有大小上限的,如果它用尽了,就会导致整个交易堵塞。以前再快的交易最后都会变慢。平时零点几秒就可以解决的事情,最后可能需要几秒、十几秒,这实际上就引发出一种暴风式的连锁反应。之前我所在的研发部就有一个MySQL应用,其拆分为4个群组,其中一个群组就是因为一个慢SQL,导致服务器完全不可用,无法对外提供服务。最后紧急进行了主备切换才解决了生产稳定性的问题。
主从复制时间延迟,影响RPO和RTO时效性,存在生产隐患
涉及主备切换时通常做法都会检查主备的不一致性,确保备库追平主库后才做切换。我们金融行业对高可用性要求非常严谨,RPO需要小于60秒。但慢SQL会导致60秒内无法完成切换,之前我们有应用一个交易的主从复制时间增至24小时都未结束,所以后面我们会采取一系列措施对这方面进行强化治理。
读写分离存在过期读,影响数据一致性
对于传统公司来说,如果想做读写分离,应该是用一些不变的或者极少变化的数据去做。但我们有的应用因为对读写分离机制了解不深,也没有考虑主从复制的时效性,把一些时效性要求非常高的数据从备库去读,这就导致了数据的不一致,引发生产隐患。最后领导只能选择“一刀切”,原则上禁止我们将MySQL备库作为读库进行读写分离,因为即便使用数据分布式访问中间层,比如MyCAT、爱可生的DBLE、阿里的 TDDL或网易的DDB等,如果把备库当作读库,还是会存在过期读这种生产隐患。
二、风险防范
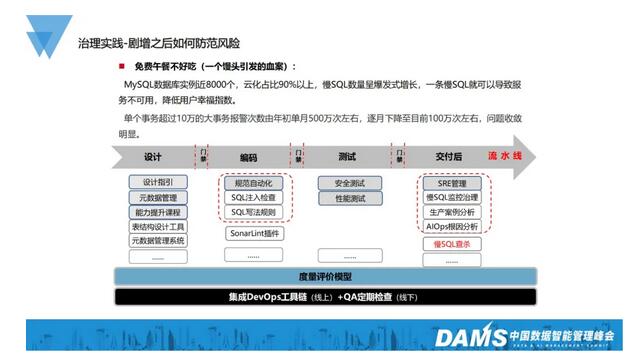
之前我在历次分享中多次强调过,免费的午餐并不好吃。无数的案例告诉我们,慢SQL如果不加处理,最后很容易引发一个血案。大家如果看过电影《无极》的话,应该知道它又被称为“一个馒头引发的血案”。
工行的MySQL数据库实例近8000个,云化占比在90%以上,慢SQL数量呈爆发式增长,一条慢SQL就可以导致服务不可用,降低用户幸福指数。而对于金融行业来说,社会声誉性是必须要考虑的关键因素之一,当服务不可用之后,很容易存在挤兑的风潮。我们几年前上了CCTV其实也是同样的道理,工行代表的是社会稳定性的基础。
从我们治理的统计结果来看,还是相当有成效的。大家可以看到,我们单个事务超过10万的大事务的报警次数,通过治理,由年初的每月500万次左右,逐月下降至目前的100万次左右,问题收敛趋势明显,但数量级摆在那儿,所以我们还是任重而道远。用屈原的话说就是“路漫漫其修远兮,吾将上下而求索”。
工行的治理实践大概分4个阶段,我们基本上是基于自动化的流水线,也就是DevOps去做这些事情的。
1、设计阶段
首先,在设计阶段我们会规范一些设计指引。大家如果有做过编码,或者本身就是数据库领域的专家的话就会知道,我们必须要夯实我们的方法论,而这个方法论就代表着我们设计指引的处理。比如数据库必须要建主键等,这其实都属于我们方法论的层面。
然后就是元数据管理,将数据标准按照应用、产品线等进行规范,抽取制定数据标准,形成元数据字典。现在流行一个概念叫元宇宙,而元数据我们把它简称为Meta。Facebook最近也改名为 Meta,这说明我们在10年前就已经预见到了这种问题。
第三是建立能力提升课程。我们将数据库的使用人分成三级。第一级是基础开发人员,他需要满足一些MySQL常见的使用方式;第二级我们定位为DBA的处理,DBA需要分析InnoDB的本质,进行语句调优等;而第三级就是高阶,我们希望他去对一些底层的逻辑进行处理,比如通过查看MySQL的源代码,判断死锁等,从深处进行发掘,帮助大家快速定位和解决问题。
最后我们落实自动化处理,建立表结构设计工具。我们在Excel的基础上做了一个元数据表结构设计工具,同时将它与我们的元数据管理系统进行连接。我们规定了业务线的数据标准,所有基于这条业务线的应用都必须满足所制定的数据基础,这就是我们所谓的元数据的概念。这样一来,后续我们的数据治理,包括从数据湖中捞取数据等都能保持一致的数据标准,对我们进行一些数据挖掘、上下游联动,以及后面会提到的根因分析,都会起到非常好的作用。
2、编码层面
在编码层面,我们强调规范的自动化。如果只有规范而没有落地执行,那就相当于纸上谈兵,永远无法落于实处。所以我们基于SonarQube扩展建立一些规则,在开发阶段就去检查大家的语法是否正确、是否存在安全隐患等,防患于未然。
同时,考虑到一些安全性相关的问题,这其中还包含了SQL注入的检查。比如MyBatis到底用“$”还是“#”号去处理等问题,防止SQL注入的风险。
还有就是对SQL写法的规则。这里会讲到我们经历过的一个案例:开发人员在update的时候少了一个逗号,用and进行了连接,并由此引发了一个更新血案。因此后来我们在本地基于SonarLint的插件做了一个扩展,将SonarLint安装在开发人员的本地。因为SonarLint跟SonarQube是完整的一个契合体,这样一来,云端的规则制定以后,我们本地的规则也会进行同步,避免了开发人员自己再去安装插件的过程,减少对开发人员的工作干扰。大家看阿里的开发手册,p3c的一些组件检查规则现在也在Sonar中进行了一些扩展。
3、测试阶段
测试阶段包含两个方面的内容,一个是安全测试,一个是性能测试。
因为很多时候我们都必须预估交易量,例如预测半年内交易量的增长趋势,同时判断会不会有其他场景的影响等,所以我们必须进行压测,这部分我们可以借助一些压测平台进行数据库的压测。
同时,针对安全测试我们也建立了DevSecOps这条黄金管道流水线,通过一些白盒测试(SAST)、黑盒测试(DAST)还有IAST等交互式的测试,来实现安全测试。
大家如果有关注“OWASP Top 10榜单”的话就能看到,注入风险的排名其实是比较高的。
4、交付后
最后是交付后。在这个阶段我们会进行SRE的管理。SRE这个概念由Google首先提出,大家也正在实践过程中。但从个人角度来看,我们其实提概念要大于实施。所以参照Google的实践体系,我们重建了一个自己的SRE的管理体系,这其中就包含了慢SQL的监控治理。
接下来是对生产案例的分析。当出现一个生产案例以后,我们会分析它的解决路径、记录并分析在解决过程中遇到的好或不好的地方、思考后续的改进方法等,将它们汇总成一个生产问题分析文档,定期在整个基地内部组织各部门进行学习,以规避相同的问题再度出现。因为我相信,不管你是否关注,只要看了文档,有了一定的印象以后,后面如果再出现类似的场景就会去下意识地进行规避,我们把这称为潜移默化。
第三部分是AIOps的根因分析。现在业界比较流行“1-5-10”这个概念,即一分钟发现问题,五分钟定位问题,十分钟解决问题。虽然这个理念很好,但从目前来看,“一”现在正在努力,“五”和“十”还属于更加高阶的处理,后面会简单再说一下。
同时,我们在生产上会建立一个慢SQL的查杀机制,将一些大事务提前进行kill掉以进行规避,将慢SQL对生产的一些风险提前扼杀。
理论说起来很简单,但关键在于,大家是否愿意把它作为一个体系去做。也就是说,我们并不希望只是将它当成一个工具去做,而是希望建成一个研发管控的完整生态体系。只有形成了生态圈,最后才能做好治理管控。
三、方法论
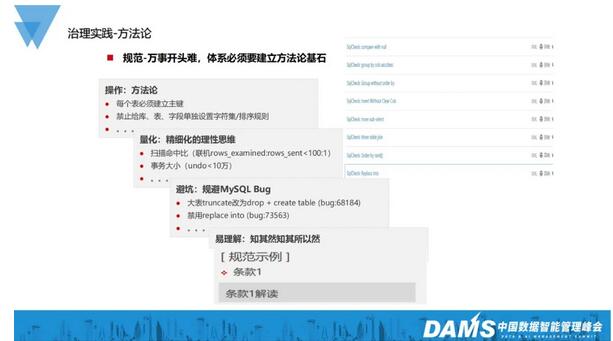
首先是方法论的建立。俗话说万事开头难,我们的体系要想建立,就必须有方法论作为基石。这部分我们大致分为四步:
第一我们会做一些规范的说明。比如:每个表必须建立主键;禁止给库、表、字段单独设置排序规则等。
第二是量化,通过精细化的理性思维去规范、约束大家。中国人其实感性思维占多数,比如我们做菜的时候会说:“我们加少许酱油。”这个“少许”到底是多少?日本人可能会说5克或10克来具体定量,但中国人喜欢说少许。而对于我们来说,就是把扫描命中比等进行量化,要求联机情况下rows_examined:rows_sent<100:1,规定事务大小undo<10万等。不同的公司有不同的标准,这是我们对于自己的要求。
19年我们在建这个体系时,正在跟爱可生公司合作,因此有机会了解到他们对大事务的规范是在1万条以内。所以,因为不同的公司系统硬件等条件不同,我们必须要根据所在企业实际情况去进行考量。
第三,我们要学会避坑。因为MySQL毕竟是一个开源免费的产品,所以它会有很多bug。比如大表的truncate,它其实会引发MySQL服务hang死的现象,最后大家可以在MySQL.err文件中发现一条 page_cleaner脏刷记录的警告,同时还有它超过了多长时间,以及一些LRU的提示。还有就是禁用replace into。因为replace into它的风险大概有三种,我相信大家应该也都遇见过,这里的话就不细说了。
第四,是易理解。通过一些方式,告诉他们怎样去理解,让他们既知其然,也知其所以然。对此我们会做一些条款的解读,方便用户知道规范制定的原因,以及可能会引发的问题等。
通过这四步,把方法论的基石建立起来,同时我们会基于SonarQube扩展一定的规则。大家从图中右上角的截图可以看到,我们现在已经在质量门禁中把这些规则加进去了。
四、确保可落地

规范建立以后,如果依赖于人,那就有可能会产生许多不确定的额外风险,所以我们要通过自动化的质量门禁来解决这个问题。我们建立了一个重自动化、轻指引的质量门禁系统。这样一来,不管有没有问题,门禁系统都会帮你进行把控,提前将风险扼杀。
如果大家有做过代码复核或其他一些规范工作的话就会明白,人在看到东西非常多时,就会下意识地产生逃避的想法,这样很容易就会把一个本来可以控制住的场景直接忽略。像我们是基于druid扩展Sonarqube的插件,实现mapper.xml文件的扫描分析,并做到了本地检查规则与云端同步。
我们目前已经建立了27条规则,后续也还在逐步完善丰富。从目前来看,已经涵盖了所有开发人员最常见的一些问题。
这里有一条业界可能没有的规范,就是:MySQL的Update语句的SET中,出现and可能是一个问题,根据SQL标准语法来看,原则上多个字段的更新中应该用逗号进行分割。在现实情况中,一般用逗号的人比较多,但确实也有开发人员中间用and去做分割。可以看图中备注举例的语句,这样会导致它一个字段被更新成一个不可靠的布尔值,最后导致结果跟预期完全不同,导致很严重的生产问题产生。所以针对该情况我们进行了一些额外的扩展。同时,对于replace into,我们也不建议去使用。还有truncate,这部分我们建议大家用Drop + create去解决这方面的问题。
五、生产防控
生产上我们会通过监控自动查杀。但实际上,如果大家学过博弈论的话就会发现:是否查杀?到底怎么保持?这其实很难平衡,可能要通过实际场景去评估到底要不要去做。
接下来是慢SQL的治理。我们在2021年上半年大概发现了6670条慢SQL并落实版本优化,但正确率其实并不高,后续我们会考虑优化一些慢SQL的治理模型,将我们的准确率从20%再进行提升。
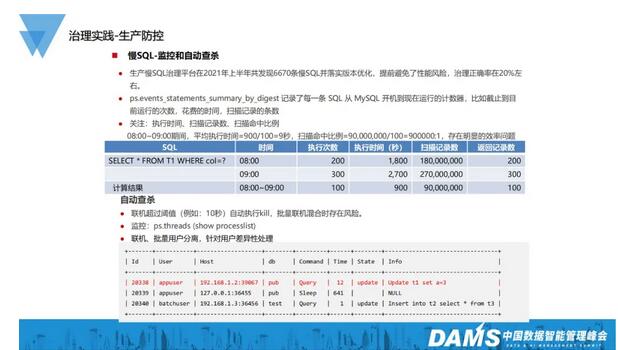
因为20%就意味着,我们的开发人员可能要花80%的无效时间去处理这方面的问题,显然违背了二八原则。虽然这个过程很痛苦,但我们确实收到一定的经营效果。本质上我们可以看到performance_schema可以用于监控MySQL运行过程中的资源消耗、资源等待等情况。这应该是MySQL 5.7以后会有的一个视图,这个视图中有一个表statements_summary_by_digest,它会记录每一条SQL的执行次数、时间,以及扫描的数据量等,通过对它们时间差的对比,获取真正的处理时间,从而判断语句是否存在问题。
Oracle的awr报告也是这样的道理,它是通过两个快照之间的差去进行比较。对于我们来说,比如8:00、9:00,我们的时间是一个语句。如图所示,它在8点执行了200次,执行时间是1800秒,扫描的记录数大概是1亿8000万;第二个是在9点,执行次数是300次,执行时间是2700秒。通过时间差可以判断,8:00~9:00之间只执行了100次,执行时间为900秒,那相当于一次执行花费了9秒,这其实就是一个标准的慢SQL。
虽然我不清楚在座各位所属应用对慢SQL的判定标准,默认应该是大于10秒的才算慢SQL。但对于我们金融行业来说,实际上超过一秒都属于慢SQL的处理范围。同时我们可以看到,它的扫描记录数大概是9000万,这样算来,它的扫描命中比例是900000:1,也就是说,我需要扫描90万条数据才能找到一条数据,这样的扫描比有很大的问题,显然存在效率问题,而我们的规范要求是100:1。
接下来是自动查杀。我们可以设置,当联机超过阈值时自动执行kill。但这样的做法在批量联机混合时存在风险,因为我们现在的批量联机用户实际上都是混合在一起的,而我们允许批量耗时超过10秒,这就很容易出现误杀。针对这一点,我们可以通过show processlist命令查看或者是通过 ps.threads去跟进线程的执行情况。
针对上述情况,我们做了两件事情:第一是推联机用户跟批量用户的分离,针对不同用户进行差异性处理。对于联机用户我们会进行自动查杀;而对于批量用户,因为我们判断它语句执行所花费的时间是合理的,所以就暂时先不管。
MySQL其实并不适合OLAP的应用,按照我的理解,我们可以通过大数据平台,也就是Hive、Spark,或者通过一些其他的方式去处理。这实际上就代表:MySQL仅局限于OLTP,其他像一些大数据平台等去做一些OLAP的处理,做到权责分离。
看到这里大家可能会说HTAP,我觉得这是一个老概念,属于新瓶装旧酒,以前Oracle其实就是HTAP数据库,但MySQL不行,所以需要结合实际业务场景做到功能和场景的分离。
六、生产防控

接下来是处理大事务的纳什均衡,也就是对监控和自动查杀的危害进行分析。因为我们现在的主从控制模式都是基于行复制的模式,所以,针对这种行复制模式,如果是大事务,我们binlog写入、传输,还有在备机的回放速度都会很慢。我们之前有应用被发现24小时都没有在备库完成重演,最后查出原因:因为这个表是新建的,所以它没有建主键,相当于每次都去做全扫,同时因为它是一个大事务,最后就导致24小时都没有回放完成。而解决方案也很简单,把事务量降低,同时对表进行增加主键的处理。
然后就是交易写入堵塞,以及当主库出现故障时面临的、切与不切之间的博弈。在这种大事务情况下,如果有些应用比较着急,那就会切,但这样可能会导致一些库的数据没有重演完成,使业务存在风险;但如果选择不切,而是等它自然结束的话,就有可能满足不了我们3个9的高可用度。在这样两难的情况下,切与不切都会导致问题。最后只能靠上帝或者靠领导拍板。但无论最后的决定是什么,我们都可能会面对在这方面受到业务或者客户的投诉的情况,所以,根据我的亲身经历,我认为这种风险是非常巨大的。
为此我们做了自动查杀。大家可以看到,MySQL可以通过执行show engine innodb status这个命令,对事务进行监控。在事务还没有结束时,会提示这个事务更新的记录数,而/G是我们对结果进行格式化,大家有机会的话可以尝试一下。
如果超过设定好的阈值,我们会自动执行kill。但在执行这个操作时我们需要规避一刀切的情况,所以我们现在仅进行一些小规模的试点。在试点完成以后才会进行大规模的处理,说白了就是不敢强上,因为强上很容易出问题。
关于日志的导入问题如图所示,这个事务里有一个导入操作,目前已经导入了3,245,700多条数据,这个大事务会影响我们很多事务的处理,我们就可以通过后台自动把这个事务终止掉,避免问题进一步扩大。
七、SRE管控体系
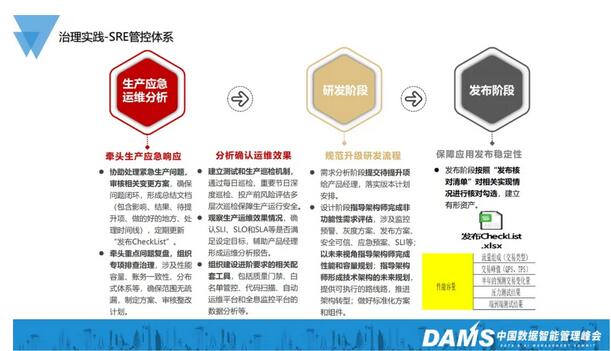
一般情况下,从Google对SRE的解释来看,它实际上是从生产运维层面去进行生产事件的处理和回溯。但是从开发团队的角度,因为对于金融行业来说,运维团队和开发团队并不一样,而且相互间容易存在掣肘。
这里我们分为三部分进行分析:
1、生产应急 运维分析
1)牵头生产应急响应。
协助处理紧急生产问题,审核相关变更方案,确保问题闭环,形成总结文档(包含影响、结果、待提升项、做的好的地方、处理时间线),定期更新“发布CheckList”。
牵头重点问题复盘,组织专项排查治理,涉及性能容量、账务一致性、分布式体系等,确保范围无疏漏,制定方案、审核整改计划。
2)分析确认运维效果
建立测试和生产巡检机制,通过每日巡检、重要节日深度巡检、投产前风险评估多层次巡检方式以保障生产运行安全。
观察生产运维效果情况,确认SLI、SLO和SLA等是否满足设定目标,辅助产品经理形成运维分析报告。
组织建设进阶要求的相关配套工具,包括质量门禁、白名单管控、代码扫描、自动运维平台和全息监控平台的数据分析等。
2、研发阶段
1)规范升级研发流程。
需求分析阶段提交待提升项给产品经理,落实版本计划安排。
设计阶段指导架构师完成非功能性需求评估,涉及监控预警、灰度方案、发布方案、安全可信、应急预案、SLI等;以未来视角指导架构师完成性能和容量规划;指导架构师形成技术架构的未来规划,提供可执行的路线路,推进架构转型;做好标准化方案和组件。
3、发布阶段
在发布时,我们会根据CheckList,对相关实现情况进行核对勾选,在确保所有指标都达标以后,才允许它进行正式发布。这样就能够在应用质量方面有较大的提升。
八、未来畅想

最后简单介绍一下我们对未来的畅想,也就是我们现在正在做的事情。
上文提到,我们一直在做“1-5-10”。但是目前还处于“1”稳步推进,“5”和“10”艰难实现的阶段。
针对一分钟定位我们发现,我们其实并没有那么多采集指标,所以对一些数据可以加大采集,比如常规数据:CPU、内存......等,目前对于中间件系统基础监控数据已经完成处理了,像网络、QPS、连接数等。
针对MySQL数据库,其实它有一些性能指标可以进行高密度采集,也有一些影响数据库性能的要素指标需要进行低密度采集。这部分主要分为两类,第一类是像ps.threads这种可以高密度地处理的,同时show engine innodb status,这样我们可以快速发现到底用哪些死锁,或迅速了解某个事务处理的数据量,以及哪些线程在做哪些事情等。这些是我们要做高密度采集的事情。低密度采集也就是我们提到过的摘要信息的处理,每小时进行一次快照的数据分析,同时通过events_statements_history,对数据进行定时采集。
通过高密度采集,我们可以快速进行一分钟定位,查出出现问题的具体位置。
接下来是五分钟预判。我们工行的实验室之前有用“逻辑回归加孤立森林算法进行异常检测,用图算法进行根因定位”对全链路进行一些根因的分析和追溯。但通过我们之前跟某Top企业交流时发现,根因定位这个方法实际的正确率只在40%左右,波动检测精度可达到80以上,但该算法属于监督算法,需要针对性训练,无法大规模普及,且模型并没有达到我们所预想的标准。之前阿里在中台有一篇宣传文章,介绍说它的五分钟预判准确率可以达到90%,虽然我不太相信这个值,但他们的模型应该是相对比较好的。
十分钟自愈这部分算是我们对未来的期望,我们希望未来在发现问题以后,系统可以直接自行处理。这部分其实我们现在在做的一些自动化运维可以达到这个要求。比如当数据库发现问题以后,经过一些检测,自动进行主从切换。这其实也属于十分钟自愈的范畴。
我们只能说还在路上,但是未来具体是什么样的?目前我们也只能猜测。希望未来会更加美好!




















