我现在有点明白了,在面试过程中面试官有时会让我们手写代码,其实主要是考验大家的基本功,更是通过大众都熟悉的领域来考核大家的体系化思维与应对思路。
而数据结构又是编程领域最基本知识,因为编程的世界中必须解决的问题:存储。
接下来笔者会从自己角度,重新开始学习数据结构,并将学习到的内容与大家一起探讨,交流,共同进步。
温馨提示:本文主要以单链表表为例进行展开,因为单链表的反转、检测环都是常见面试题。
1、链表是什么?具备哪些基本特征?
面试官让我们手写一个链表,那我们首先快速梳理出链表的基本特征。
特意从百度百科上查询了链表的定义:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
基本特征如下:
- 物理存储非连续、逻辑通过指针实现顺序性,其示例图如下所示:
- 数据结构分为指针域和数据域

面向对象编程,类不仅要定义属性,还需要抽象出行为(方法),思考如下:

通知在面试过程中,只需要基本实现增、删、改、查即可。
2、图解与代码实现
链表的类图如下:
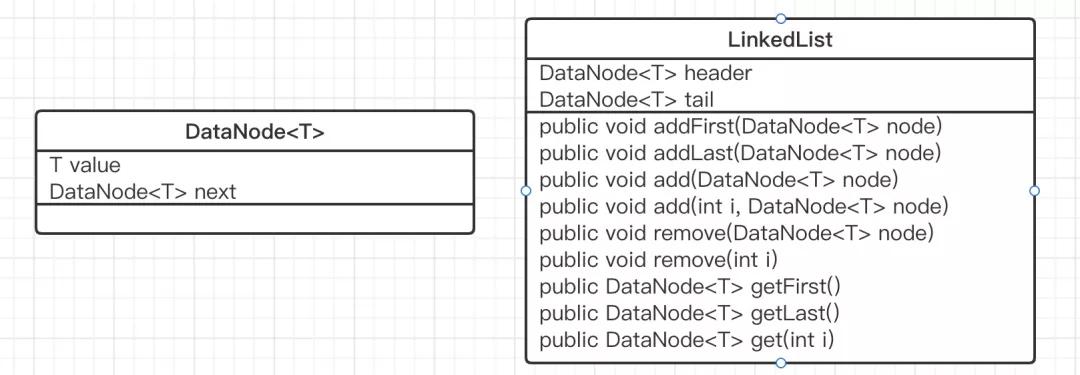
链表的存储结构如下图所示:

接下来将从代码角度来实现一个简易的链表。
2.1 基础代码
链表的基础数据如下所示:
- public class LinkedList<T> {
- /** 指针域*/
- // 头节点
- private DataNode<T> header;
- // 从节点
- private DataNode<T> tail;
- private int size;
- /**
- * 数据节点
- * @param <T>
- */
- private class DataNode<T> {
- public T value;
- public DataNode<T> next;
- public DataNode(T value) {
- this.value = value;
- }
- }
- }
2.2 指定下标插入节点
上面主要是定义基本的数据结构,接下来我们看一下在链表的中间插入新的数据。
在指定下标处插入节点,该节点作为新节点的前驱节点,暂存它的next指针,谨防该指针会丢失,图示如下:

代码如下所示
- public void add(int index, T value) {
- if(index >= size) {
- throw new ArrayIndexOutOfBoundsException();
- }
- DataNode<T> node = new DataNode<>(value);
- DataNode<T> prev = get(index);
- DataNode<T> tmp = prev.next; // @1
- prev.next = node; // @2
- node.next = tmp; // @3
- }
链表的插入首先找到前驱节点,暂存它的next指针,谨防该指针会丢失,图解如下图所示:
上述三行代码的说明如下:
- @1:首先创建一个临时节点,用于暂存前驱节点的next
- @2:前驱节点的next指针重新指向待插入的节点
- @3:新节点的next指针指向原前驱节点的next指针
优化点:其实我们发现,前驱节点是要暂存,但是否真有必要开辟一个临时节点,其实不需要,直接将其赋值给新节点的next即可。优化代码如下:
- node.next = prev.next;
- prev.next = node;
2.3 移除指定下标处节点
移除指定下标处节点的示例图:
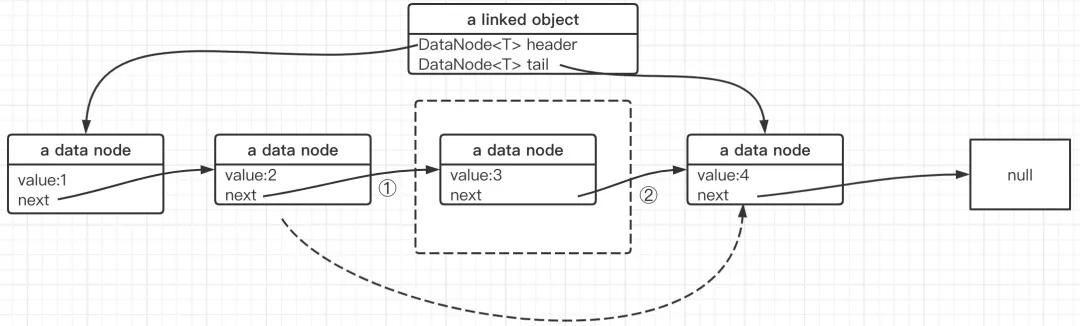
正如上图所示,要移除下标为2的节点,即图中的第三个节点,核心关键点还是需要找到待删除节点的前驱节点,然后前驱节点的next等于待删除节点的next即可,故实现代码如下:
- public T remove(int index) {
- if(index >= size) {
- throw new ArrayIndexOutOfBoundsException();
- }
- DataNode<T> pre = get(index - 1 );
- DataNode<T> cur = pre.next;
- pre.next = cur.next;
- // help GC
- cur.next = null;
- size --;
- return cur.value;
- }
2.4 单链表反转
所谓的单链表反转,就是将原链表逆序输出结果,其示例图如下:
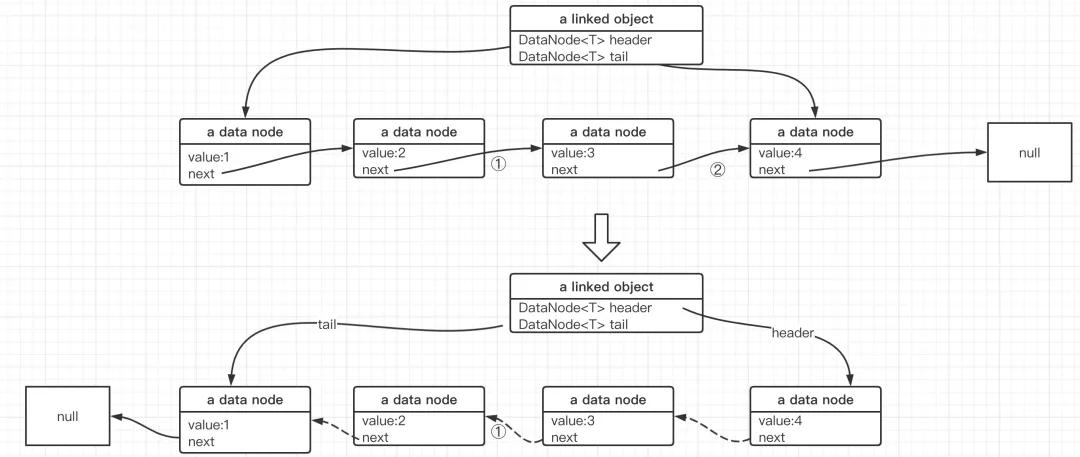
单链表的反转,需要做的事情是将当前节点的next指针指向前驱节点。
但由于单链表只有next指针,故从头节点开始遍历的过程中,遍历指针前进到的当前节点时,需要能方便的访问到该节点的前驱动。
另外一个核心点就是,在遍历过程中,对当前节点的next指针进行操作(赋值为前驱节点)时必须暂存该节点的next指针,否则next指针丢失,无法遍历到链表的结尾。
基于上述思路,链表反转的具体操作流程如下图所示:
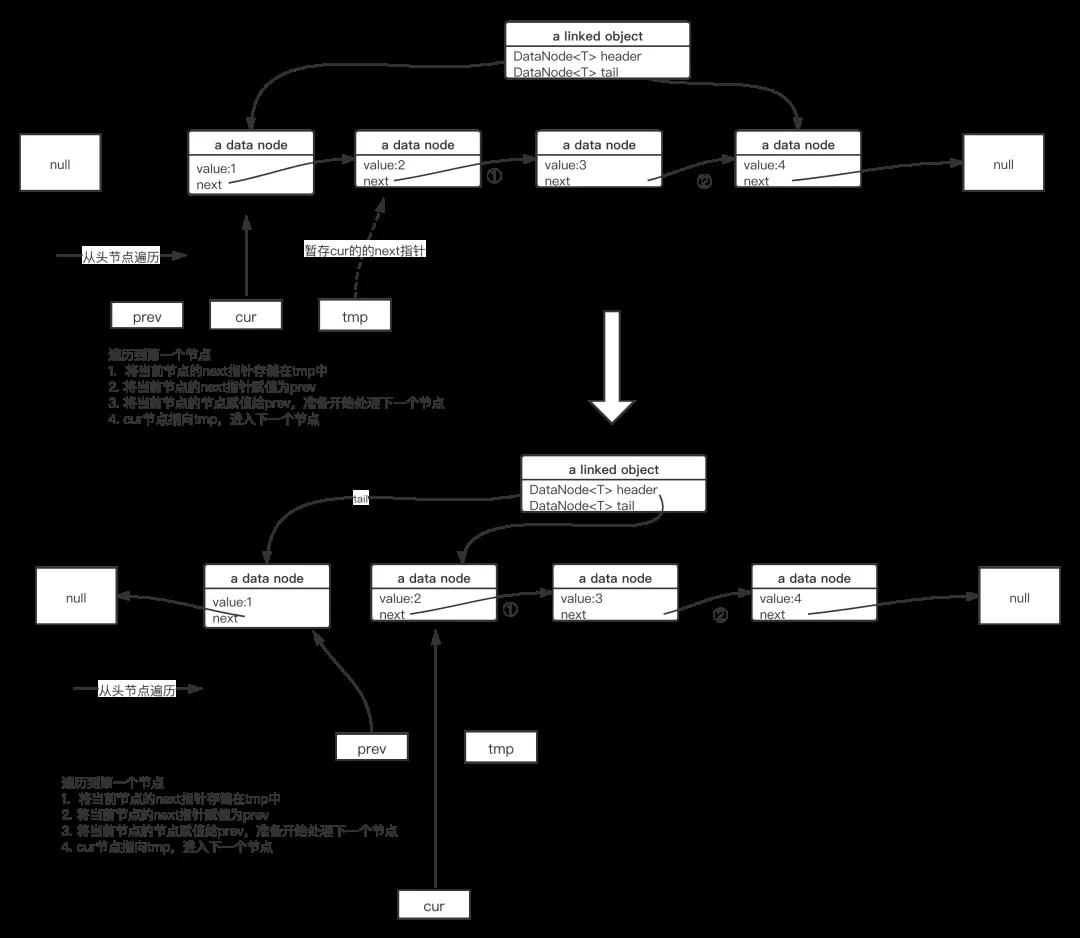
基于上述思路,代码编写如下所示:
- public void reverse() {
- // 从头节点开始遍历
- DataNode<T> cur = header;
- // 记录当前节点到 prev 前驱节点
- DataNode<T> cur_prev = null;
- // 暂存当前节点到next指针
- DataNode<T> cur_next = null;
- // 从当前节点开始遍历,直接到尾部
- while(cur != null) {
- //反转之前,先暂存相关节点
- cur_next = cur.next;
- cur.next = cur_prev;
- cur_prev = cur;
- // 继续遍历下一个节点
- cur = cur_next;
- }
- //反转 header ,tail
- DataNode<T> tmp = header;
- header = tail;
- tail = tmp;
- }
链表的其他方法实现,基本差不多,从编写代码的过程中,不难看出链表的操作,主要是操作各个节点的指针。
3、常见面试题
3.1 链表与数组的区别
链表与数组的区别可以从如下几个方面展开:
- 内存布局
- 插入性能
- 查找性能
3.1.1 内存布局
数组必须申请连续的内存,即物理上连续,例如当前jvm虚拟机当前还剩150M内存,但此时尝试去创建一个100M内存,可能无法分配内存而触发垃圾回收,而链表是逻辑连续,物理上不连续,因为时通过指针进行定位。
3.1.2 插入性能
链表在头、尾节点插入性能极佳,如果需要在链表的随机位置插入数据,需要先从头节点开始遍历,先找到相关待插入节点的前驱节点,后续的插入操作只需要涉及指针赋值,性能表现佳,而数组的插入由于需要涉及数据的复制、移动,从而带来较大性能损耗。

3.1.3 查找性能
数组最大的优势是随机查找能力,其时间复杂度为O(1),即数组可以根据下表快速定位到需要查询到数据。而链表只能是从头节点或尾节点开始遍历。
本文转载自微信公众号「中间件兴趣圈」,可以通过以下二维码关注。转载本文请联系中间件兴趣圈公众号。